 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaQA: A Question Answering Dataset with Paraphrase Responses for Single-Turn Conversation
Mar 13, 2021
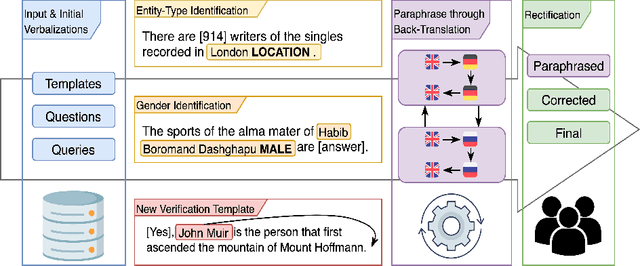

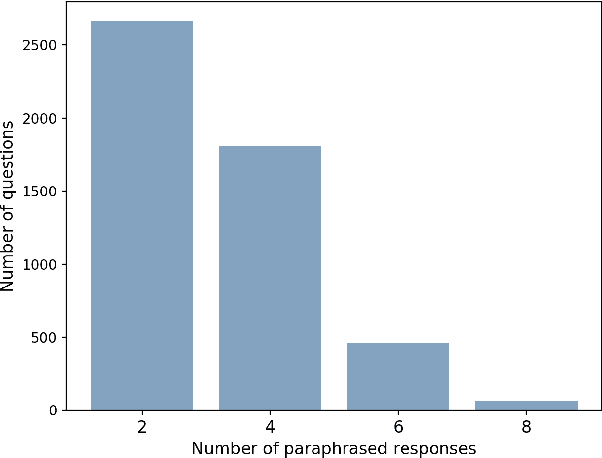
This paper presents ParaQA, a question answering (QA) dataset with multiple paraphrased responses for single-turn conversation over knowledge graphs (KG). The dataset was created using a semi-automated framework for generating diverse paraphrasing of the answers using techniques such as back-translation. The existing datasets for conversational question answering over KGs (single-turn/multi-turn) focus on question paraphrasing and provide only up to one answer verbalization. However, ParaQA contains 5000 question-answer pairs with a minimum of two and a maximum of eight unique paraphrased responses for each question. We complement the dataset with baseline models and illustrate the advantage of having multiple paraphrased answers through commonly used metrics such as BLEU and METEOR. The ParaQA dataset is publicly available on a persistent URI for broader usage and adaptation in the research community.
Context Transformer with Stacked Pointer Networks for Conversational Question Answering over Knowledge Graphs
Mar 13, 2021
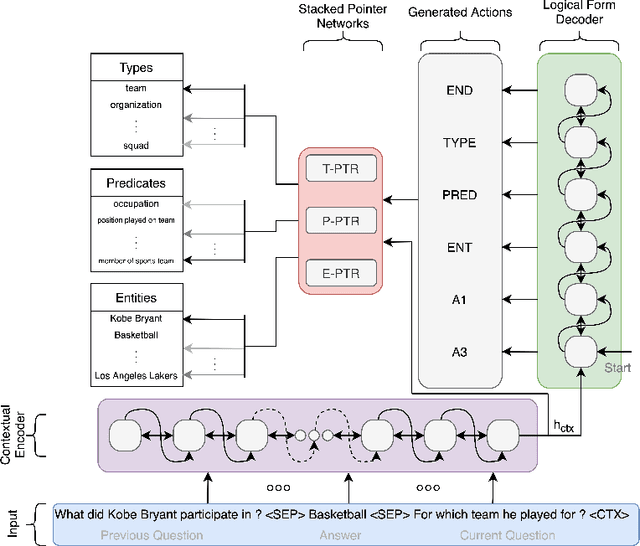
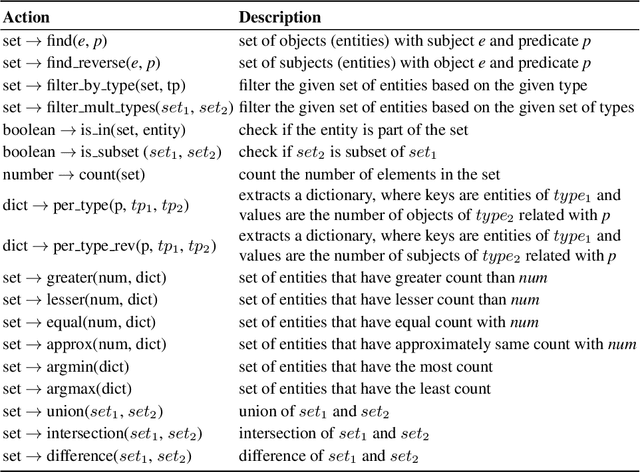
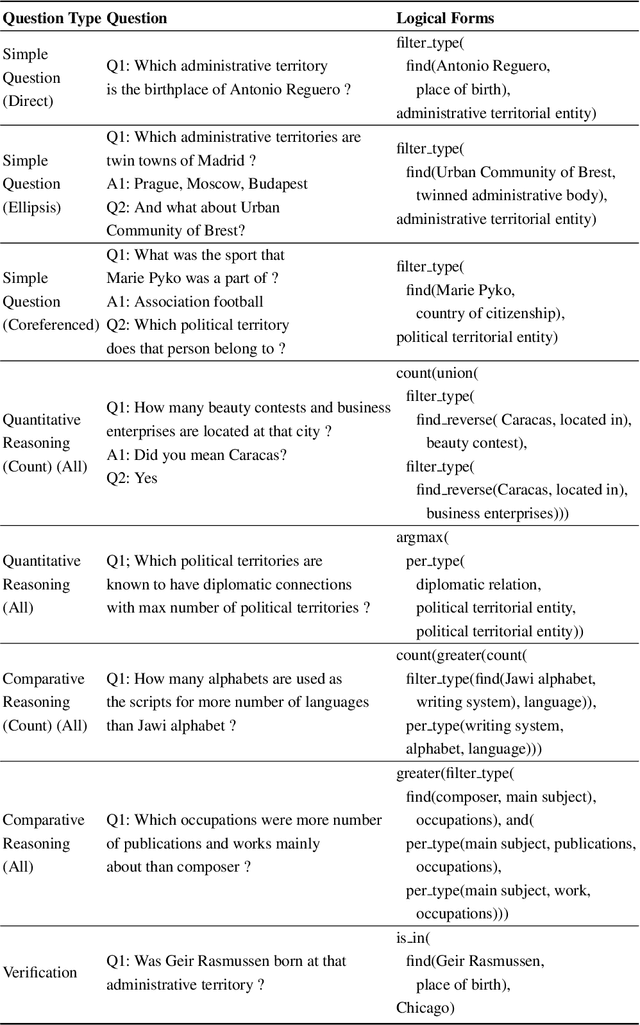
Neural semantic parsing approaches have been widely used for Question Answering (QA) systems over knowledge graphs. Such methods provide the flexibility to handle QA datasets with complex queries and a large number of entities. In this work, we propose a novel framework named CARTON, which performs multi-task semantic parsing for handling the problem of conversational question answering over a large-scale knowledge graph. Our framework consists of a stack of pointer networks as an extension of a context transformer model for parsing the input question and the dialog history. The framework generates a sequence of actions that can be executed on the knowledge graph. We evaluate CARTON on a standard dataset for complex sequential question answering on which CARTON outperforms all baselines. Specifically, we observe performance improvements in F1-score on eight out of ten question types compared to the previous state of the art. For logical reasoning questions, an improvement of 11 absolute points is reached.
Better Call the Plumber: Orchestrating Dynamic Information Extraction Pipelines
Feb 22, 2021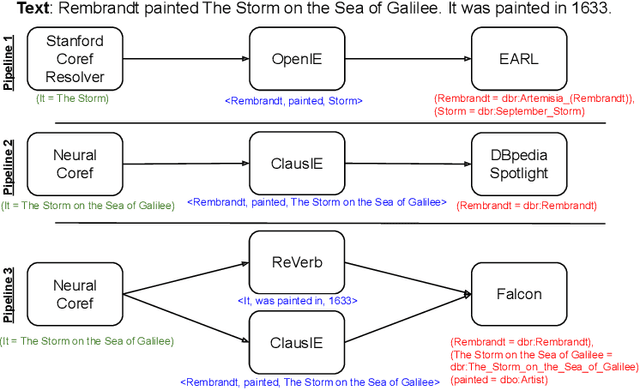
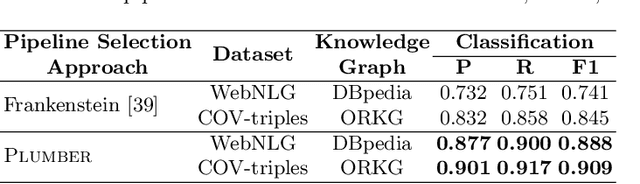
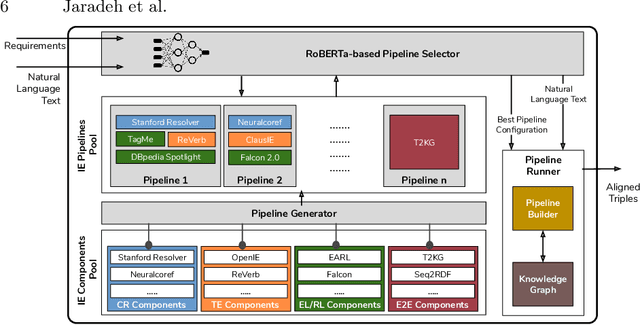
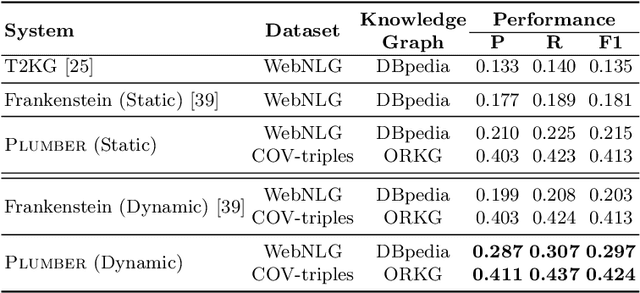
In the last decade, a large number of Knowledge Graph (KG) information extraction approaches were proposed. Albeit effective, these efforts are disjoint, and their collective strengths and weaknesses in effective KG information extraction (IE) have not been studied in the literature. We propose Plumber, the first framework that brings together the research community's disjoint IE efforts. The Plumber architecture comprises 33 reusable components for various KG information extraction subtasks, such as coreference resolution, entity linking, and relation extraction. Using these components,Plumber dynamically generates suitable information extraction pipelines and offers overall 264 distinct pipelines.We study the optimization problem of choosing suitable pipelines based on input sentences. To do so, we train a transformer-based classification model that extracts contextual embeddings from the input and finds an appropriate pipeline. We study the efficacy of Plumber for extracting the KG triples using standard datasets over two KGs: DBpedia, and Open Research Knowledge Graph (ORKG). Our results demonstrate the effectiveness of Plumber in dynamically generating KG information extraction pipelines,outperforming all baselines agnostics of the underlying KG. Furthermore,we provide an analysis of collective failure cases, study the similarities and synergies among integrated components, and discuss their limitations.
CHOLAN: A Modular Approach for Neural Entity Linking on Wikipedia and Wikidata
Feb 08, 2021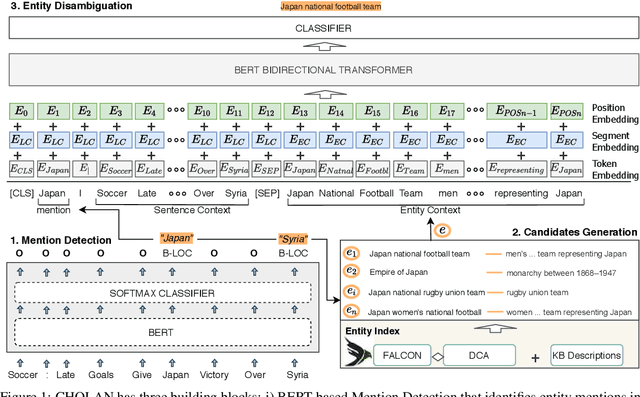
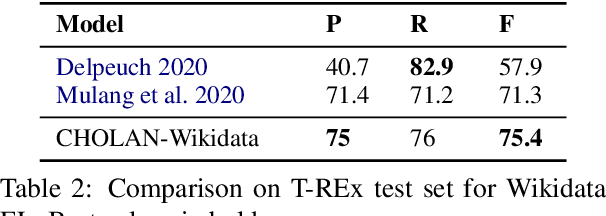
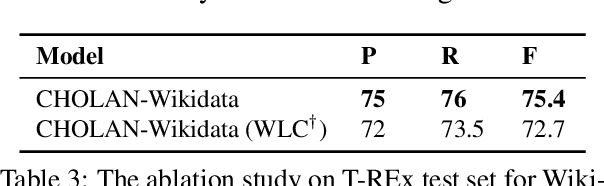
In this paper, we propose CHOLAN, a modular approach to target end-to-end entity linking (EL) over knowledge bases. CHOLAN consists of a pipeline of two transformer-based models integrated sequentially to accomplish the EL task. The first transformer model identifies surface forms (entity mentions) in a given text. For each mention, a second transformer model is employed to classify the target entity among a predefined candidates list. The latter transformer is fed by an enriched context captured from the sentence (i.e. local context), and entity description gained from Wikipedia. Such external contexts have not been used in the state of the art EL approaches. Our empirical study was conducted on two well-known knowledge bases (i.e., Wikidata and Wikipedia). The empirical results suggest that CHOLAN outperforms state-of-the-art approaches on standard datasets such as CoNLL-AIDA, MSNBC, AQUAINT, ACE2004, and T-REx.
QA2Explanation: Generating and Evaluating Explanations for Question Answering Systems over Knowledge Graph
Oct 16, 2020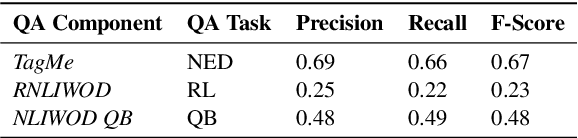
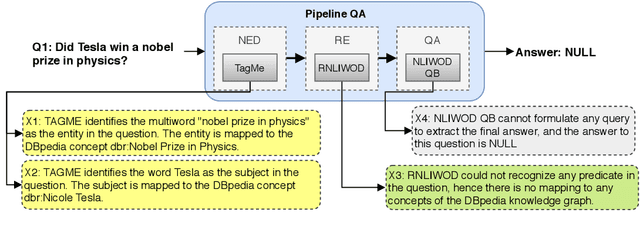
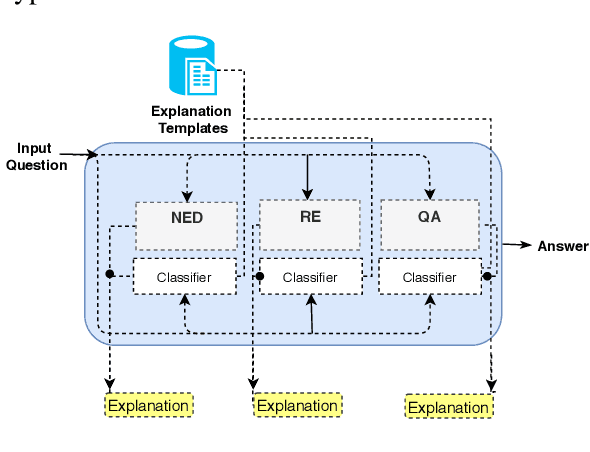
In the era of Big Knowledge Graphs, Question Answering (QA) systems have reached a milestone in their performance and feasibility. However, their applicability, particularly in specific domains such as the biomedical domain, has not gained wide acceptance due to their "black box" nature, which hinders transparency, fairness, and accountability of QA systems. Therefore, users are unable to understand how and why particular questions have been answered, whereas some others fail. To address this challenge, in this paper, we develop an automatic approach for generating explanations during various stages of a pipeline-based QA system. Our approach is a supervised and automatic approach which considers three classes (i.e., success, no answer, and wrong answer) for annotating the output of involved QA components. Upon our prediction, a template explanation is chosen and integrated into the output of the corresponding component. To measure the effectiveness of the approach, we conducted a user survey as to how non-expert users perceive our generated explanations. The results of our study show a significant increase in the four dimensions of the human factor from the Human-computer interaction community.
* Accepted in IntEx-SemPar: Interactive and Executable Semantic Parsing EMNLP 2020 Workshop
RECON: Relation Extraction using Knowledge Graph Context in a Graph Neural Network
Sep 18, 2020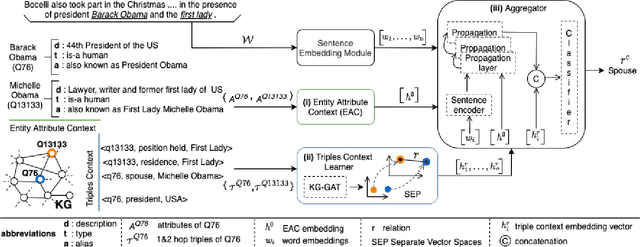
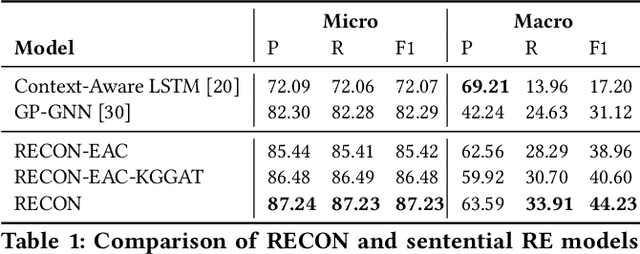
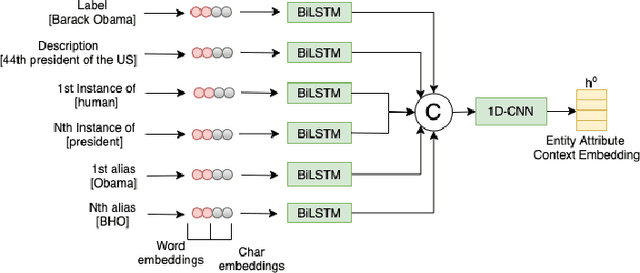
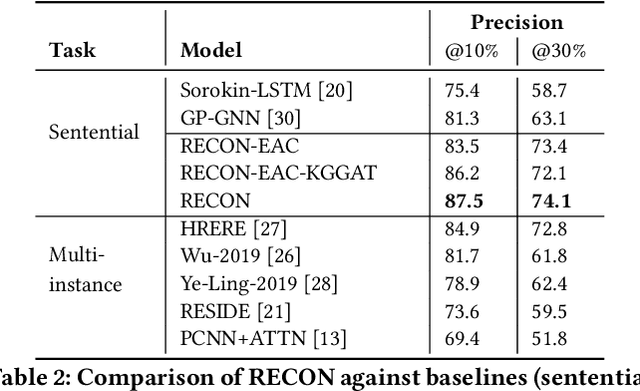
In this paper, we present a novel method named RECON, that automatically identifies relations in a sentence (sentential relation extraction) and aligns to a knowledge graph (KG). RECON uses a graph neural network to learn representations of both the sentence as well as facts stored in a KG, improving the overall extraction quality. These facts, including entity attributes (label, alias, description, instance-of) and factual triples, have not been collectively used in the state of the art methods. We evaluate the effect of various forms of representing the KG context on the performance of RECON. The empirical evaluation on two standard relation extraction datasets shows that RECON significantly outperforms all state of the art methods on NYT Freebase and Wikidata datasets. RECON reports 87.23 F1 score (Vs 82.29 baseline) on Wikidata dataset whereas on NYT Freebase, reported values are 87.5(P@10) and 74.1(P@30) compared to the previous baseline scores of 81.3(P@10) and 63.1(P@30).
Uncovering the Corona Virus Map Using Deep Entities and Relationship Models
Sep 07, 2020
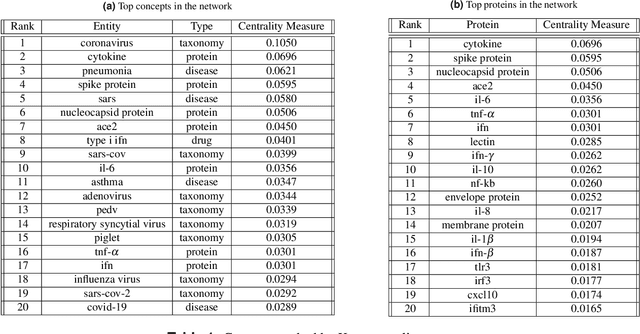
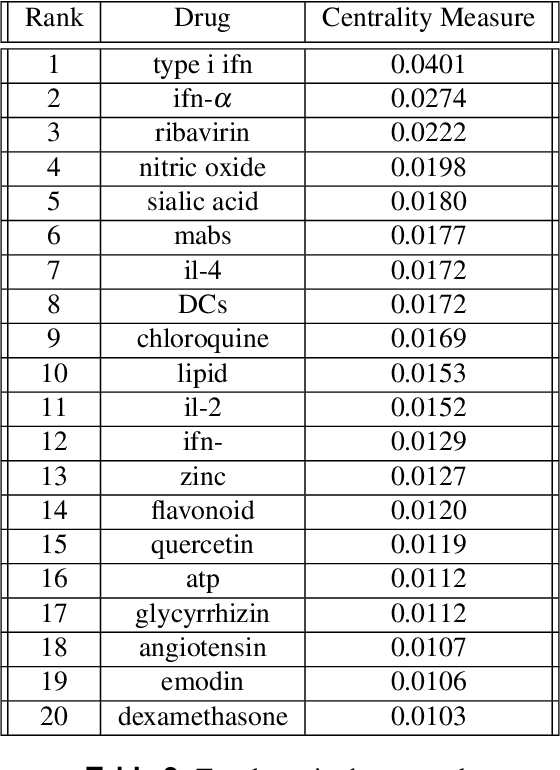
We extract entities and relationships related to COVID-19 from a corpus of articles related to Corona virus by employing a novel entities and relationship model. The entity recognition and relationship discovery models are trained with a multi-task learning objective on a large annotated corpus. We employ a concept masking paradigm to prevent the evolution of neural networks functioning as an associative memory and induce right inductive bias guiding the network to make inference using only the context. We uncover several import subnetworks, highlight important terms and concepts and elucidate several treatment modalities employed in related ailments in the past.
Evaluating the Impact of Knowledge Graph Context on Entity Disambiguation Models
Aug 30, 2020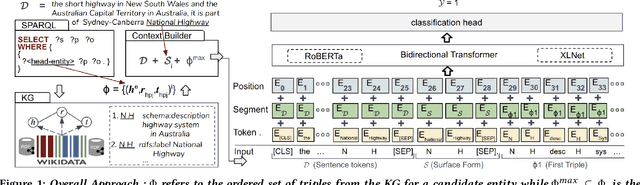
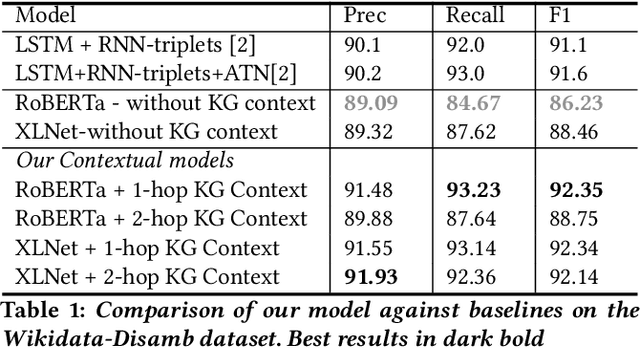

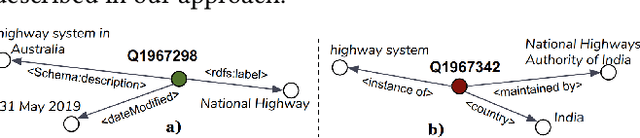
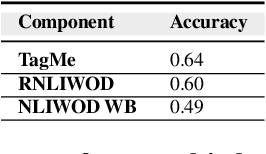
Pretrained Transformer models have emerged as state-of-the-art approaches that learn contextual information from text to improve the performance of several NLP tasks. These models, albeit powerful, still require specialized knowledge in specific scenarios. In this paper, we argue that context derived from a knowledge graph (in our case: Wikidata) provides enough signals to inform pretrained transformer models and improve their performance for named entity disambiguation (NED) on Wikidata KG. We further hypothesize that our proposed KG context can be standardized for Wikipedia, and we evaluate the impact of KG context on state-of-the-art NED model for the Wikipedia knowledge base. Our empirical results validate that the proposed KG context can be generalized (for Wikipedia), and providing KG context in transformer architectures considerably outperforms the existing baselines, including the vanilla transformer models.
* to appear in proceedings of CIKM 2020
FALCON 2.0: An Entity and Relation Linking Tool over Wikidata
Feb 12, 2020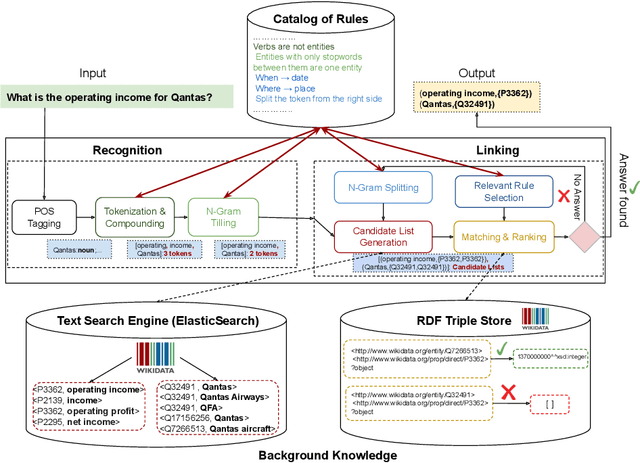

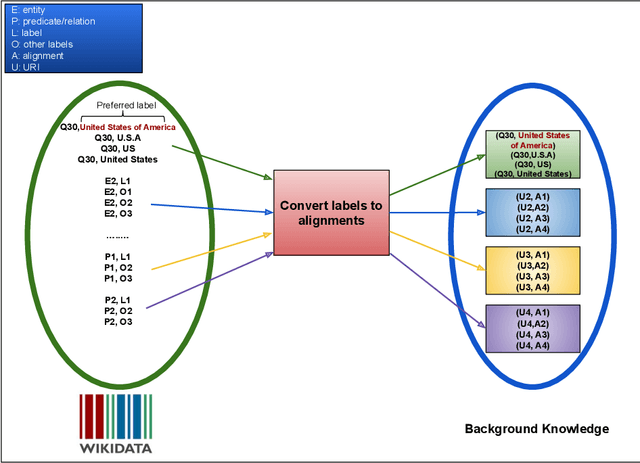

Natural Language Processing (NLP) tools and frameworks have significantly contributed with solutions to the problems of extracting entities and relations and linking them to the related knowledge graphs. Albeit effective, the majority of existing tools are available for only one knowledge graph. In this paper, we present Falcon 2.0, a rule-based tool capable of accurately mapping entities and relations in short texts to resources in both DBpedia and Wikidata following the same approach in both cases. The input of Falcon 2.0 is a short natural language text in the English language. Falcon 2.0 resorts to fundamental principles of the English morphology (e.g., N-Gram tiling and N-Gram splitting) and background knowledge of labels alignments obtained from studied knowledge graph to return as an output; the resulting entity and relation resources are either in the DBpedia or Wikidata knowledge graphs. We have empirically studied the impact using only Wikidata on Falcon 2.0, and observed it is knowledge graph agnostic, i.e., Falcon 2.0 performance and behavior are not affected by the knowledge graph used as background knowledge. Falcon 2.0 is public and can be reused by the community. Additionally, Falcon 2.0 and its background knowledge bases are available as resources at https://labs.tib.eu/falcon/falcon2/.
Context-aware Entity Linking with Attentive Neural Networks on Wikidata Knowledge Graph
Dec 12, 2019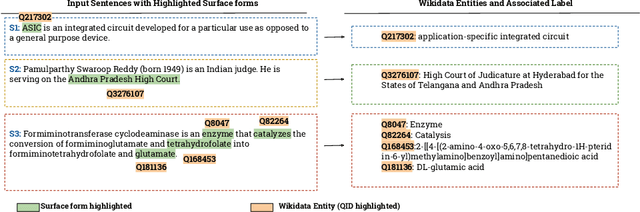
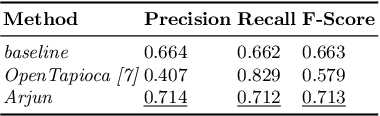
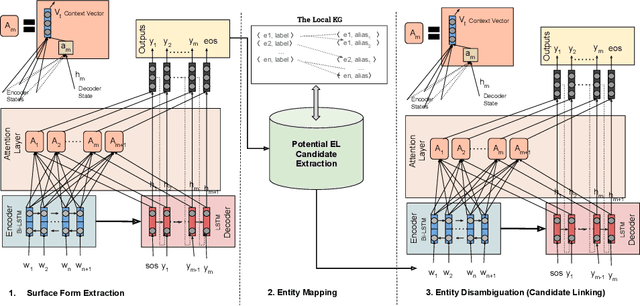
The Entity Linking (EL) approaches have been a long-standing research field and find applicability in various use cases such as semantic search, text annotation, question answering, etc. Although effective and robust, current approaches are still limited to particular knowledge repositories (e.g. Wikipedia) or specific knowledge graphs (e.g. Freebase, DBpedia, and YAGO). The collaborative knowledge graphs such as Wikidata excessively rely on the crowd to author the information. Since the crowd is not bound to a standard protocol for assigning entity titles, the knowledge graph is populated by non-standard, noisy, long or even sometimes awkward titles. The issue of long, implicit, and nonstandard entity representations is a challenge in EL approaches for gaining high precision and recall. In this paper, we advance the state-of-the-art approaches by developing a context-aware attentive neural network approach for entity linking on Wikidata. Our approach contributes by exploiting the sufficient context from a Knowledge Graph as a source of background knowledge, which is then fed into the neural network. This approach demonstrates merit to address challenges associated with entity titles (multi-word, long, implicit, case-sensitive). Our experimental study shows $\approx$8\% improvements over the baseline approach, and significantly outperform an end to end approach for Wikidata entity linking. This work, first of its kind, opens a new direction for the research community to pay attention to developing context-aware EL approaches for collaborative knowledge graphs.