 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Spectral Wavelets on Dynamic Graphs to Capture Global Interactions
Nov 22, 2022



Learning on evolving(dynamic) graphs has caught the attention of researchers as static methods exhibit limited performance in this setting. The existing methods for dynamic graphs learn spatial features by local neighborhood aggregation, which essentially only captures the low pass signals and local interactions. In this work, we go beyond current approaches to incorporate global features for effectively learning representations of a dynamically evolving graph. We propose to do so by capturing the spectrum of the dynamic graph. Since static methods to learn the graph spectrum would not consider the history of the evolution of the spectrum as the graph evolves with time, we propose a novel approach to learn the graph wavelets to capture this evolving spectra. Further, we propose a framework that integrates the dynamically captured spectra in the form of these learnable wavelets into spatial features for incorporating local and global interactions. Experiments on eight standard datasets show that our method significantly outperforms related methods on various tasks for dynamic graphs.
Contrastive Representation Learning for Conversational Question Answering over Knowledge Graphs
Oct 09, 2022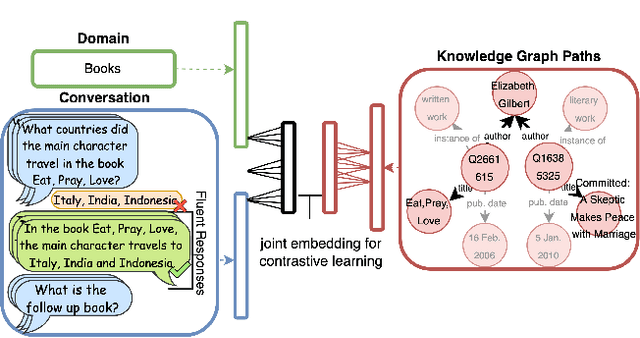
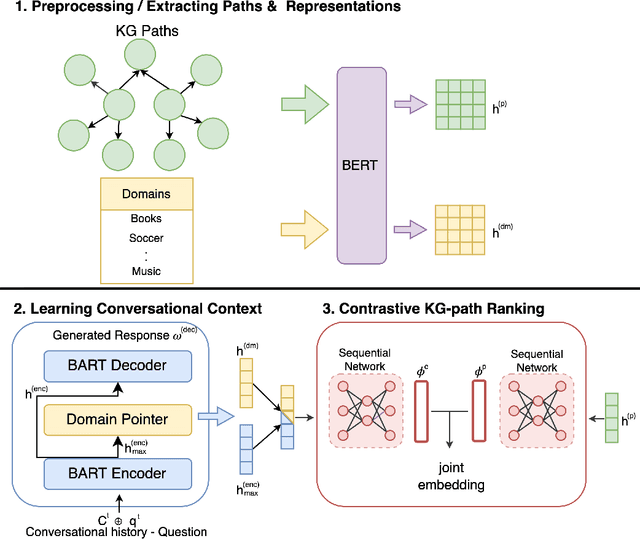
This paper addresses the task of conversational question answering (ConvQA) over knowledge graphs (KGs). The majority of existing ConvQA methods rely on full supervision signals with a strict assumption of the availability of gold logical forms of queries to extract answers from the KG. However, creating such a gold logical form is not viable for each potential question in a real-world scenario. Hence, in the case of missing gold logical forms, the existing information retrieval-based approaches use weak supervision via heuristics or reinforcement learning, formulating ConvQA as a KG path ranking problem. Despite missing gold logical forms, an abundance of conversational contexts, such as entire dialog history with fluent responses and domain information, can be incorporated to effectively reach the correct KG path. This work proposes a contrastive representation learning-based approach to rank KG paths effectively. Our approach solves two key challenges. Firstly, it allows weak supervision-based learning that omits the necessity of gold annotations. Second, it incorporates the conversational context (entire dialog history and domain information) to jointly learn its homogeneous representation with KG paths to improve contrastive representations for effective path ranking. We evaluate our approach on standard datasets for ConvQA, on which it significantly outperforms existing baselines on all domains and overall. Specifically, in some cases, the Mean Reciprocal Rank (MRR) and Hit@5 ranking metrics improve by absolute 10 and 18 points, respectively, compared to the state-of-the-art performance.
An Answer Verbalization Dataset for Conversational Question Answerings over Knowledge Graphs
Aug 13, 2022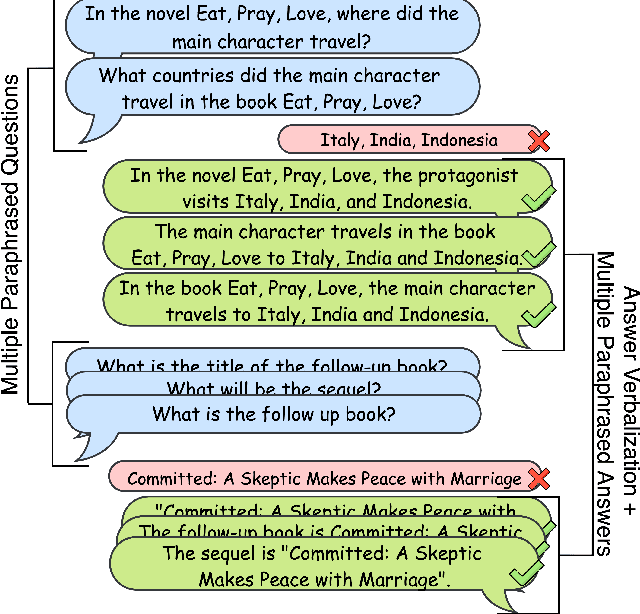

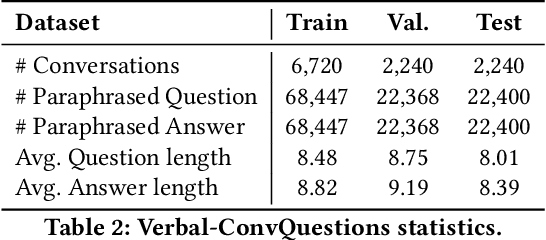
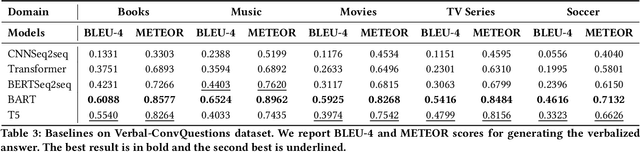
We introduce a new dataset for conversational question answering over Knowledge Graphs (KGs) with verbalized answers. Question answering over KGs is currently focused on answer generation for single-turn questions (KGQA) or multiple-tun conversational question answering (ConvQA). However, in a real-world scenario (e.g., voice assistants such as Siri, Alexa, and Google Assistant), users prefer verbalized answers. This paper contributes to the state-of-the-art by extending an existing ConvQA dataset with multiple paraphrased verbalized answers. We perform experiments with five sequence-to-sequence models on generating answer responses while maintaining grammatical correctness. We additionally perform an error analysis that details the rates of models' mispredictions in specified categories. Our proposed dataset extended with answer verbalization is publicly available with detailed documentation on its usage for wider utility.
Plumber: A Modular Framework to Create Information Extraction Pipelines
Jun 03, 2022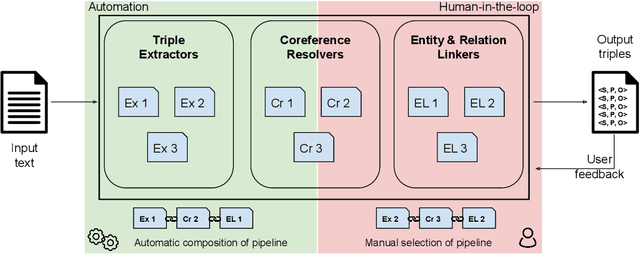
Information Extraction (IE) tasks are commonly studied topics in various domains of research. Hence, the community continuously produces multiple techniques, solutions, and tools to perform such tasks. However, running those tools and integrating them within existing infrastructure requires time, expertise, and resources. One pertinent task here is triples extraction and linking, where structured triples are extracted from a text and aligned to an existing Knowledge Graph (KG). In this paper, we present PLUMBER, the first framework that allows users to manually and automatically create suitable IE pipelines from a community-created pool of tools to perform triple extraction and alignment on unstructured text. Our approach provides an interactive medium to alter the pipelines and perform IE tasks. A short video to show the working of the framework for different use-cases is available online under: https://www.youtube.com/watch?v=XC9rJNIUv8g
Investigating Expressiveness of Transformer in Spectral Domain for Graphs
Jan 27, 2022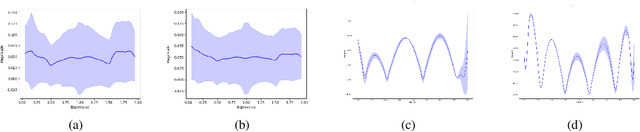
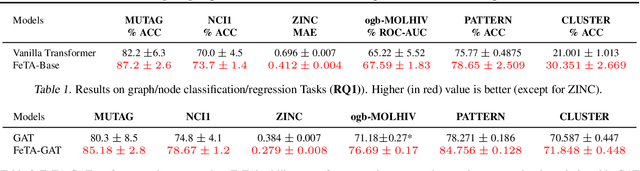
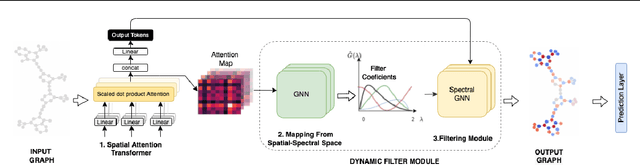
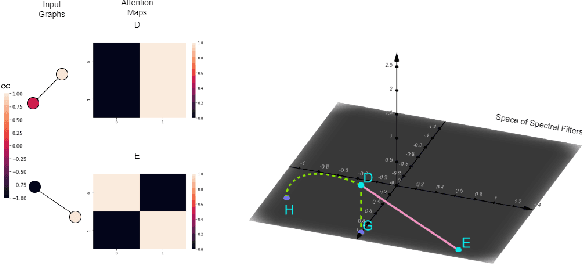
Transformers have been proven to be inadequate for graph representation learning. To understand this inadequacy, there is need to investigate if spectral analysis of transformer will reveal insights on its expressive power. Similar studies already established that spectral analysis of Graph neural networks (GNNs) provides extra perspectives on their expressiveness. In this work, we systematically study and prove the link between the spatial and spectral domain in the realm of the transformer. We further provide a theoretical analysis that the spatial attention mechanism in the transformer cannot effectively capture the desired frequency response, thus, inherently limiting its expressiveness in spectral space. Therefore, we propose FeTA, a framework that aims to perform attention over the entire graph spectrum analogous to the attention in spatial space. Empirical results suggest that FeTA provides homogeneous performance gain against vanilla transformer across all tasks on standard benchmarks and can easily be extended to GNN based models with low-pass characteristics (e.g., GAT). Furthermore, replacing the vanilla transformer model with FeTA in recently proposed position encoding schemes has resulted in comparable or better performance than transformer and GNN baselines.
Triple Classification for Scholarly Knowledge Graph Completion
Nov 23, 2021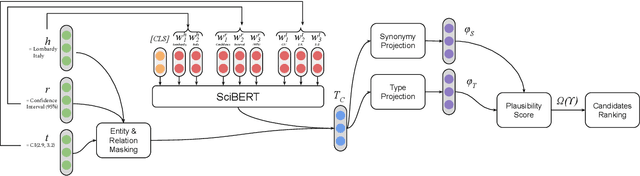

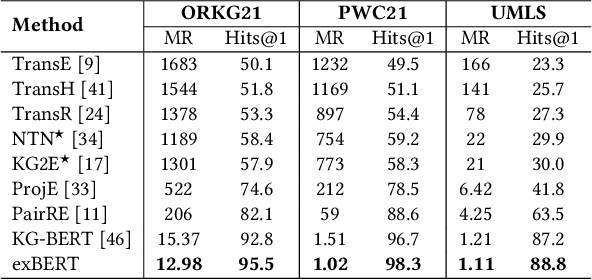
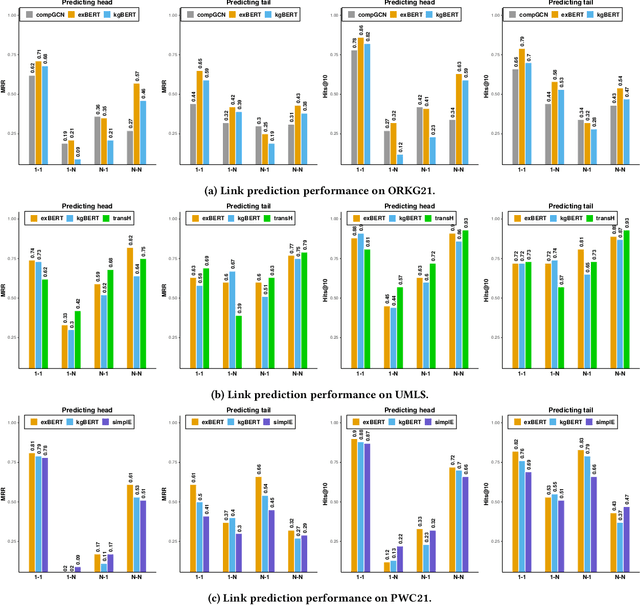
Scholarly Knowledge Graphs (KGs) provide a rich source of structured information representing knowledge encoded in scientific publications. With the sheer volume of published scientific literature comprising a plethora of inhomogeneous entities and relations to describe scientific concepts, these KGs are inherently incomplete. We present exBERT, a method for leveraging pre-trained transformer language models to perform scholarly knowledge graph completion. We model triples of a knowledge graph as text and perform triple classification (i.e., belongs to KG or not). The evaluation shows that exBERT outperforms other baselines on three scholarly KG completion datasets in the tasks of triple classification, link prediction, and relation prediction. Furthermore, we present two scholarly datasets as resources for the research community, collected from public KGs and online resources.
HopfE: Knowledge Graph Representation Learning using Inverse Hopf Fibrations
Aug 12, 2021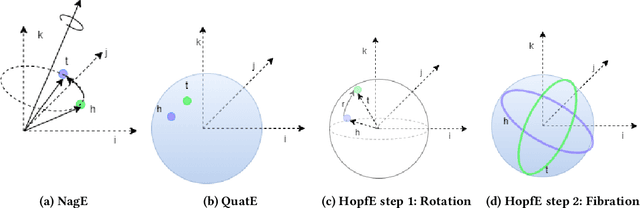

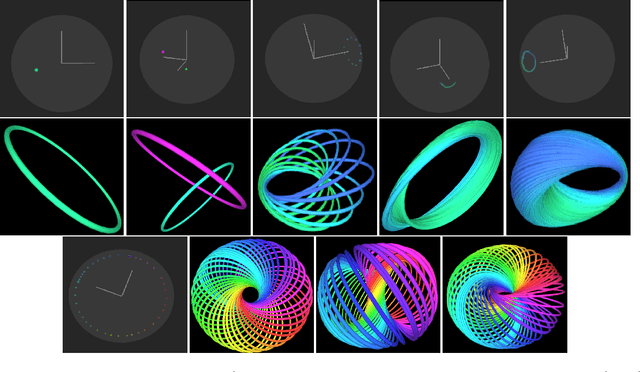
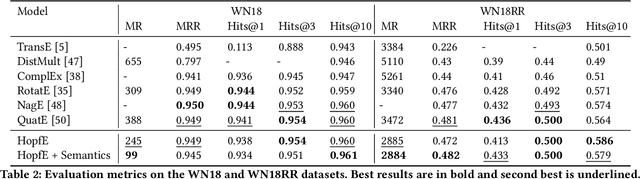
Recently, several Knowledge Graph Embedding (KGE) approaches have been devised to represent entities and relations in dense vector space and employed in downstream tasks such as link prediction. A few KGE techniques address interpretability, i.e., mapping the connectivity patterns of the relations (i.e., symmetric/asymmetric, inverse, and composition) to a geometric interpretation such as rotations. Other approaches model the representations in higher dimensional space such as four-dimensional space (4D) to enhance the ability to infer the connectivity patterns (i.e., expressiveness). However, modeling relation and entity in a 4D space often comes at the cost of interpretability. This paper proposes HopfE, a novel KGE approach aiming to achieve the interpretability of inferred relations in the four-dimensional space. We first model the structural embeddings in 3D Euclidean space and view the relation operator as an SO(3) rotation. Next, we map the entity embedding vector from a 3D space to a 4D hypersphere using the inverse Hopf Fibration, in which we embed the semantic information from the KG ontology. Thus, HopfE considers the structural and semantic properties of the entities without losing expressivity and interpretability. Our empirical results on four well-known benchmarks achieve state-of-the-art performance for the KG completion task.
VOGUE: Answer Verbalization through Multi-Task Learning
Jun 28, 2021
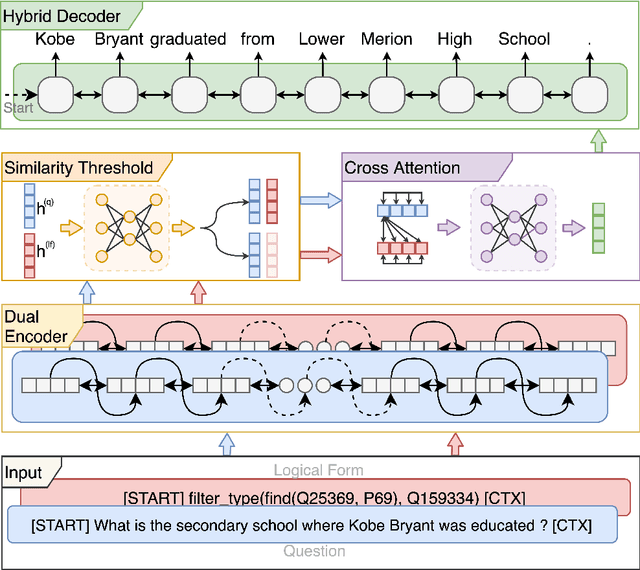
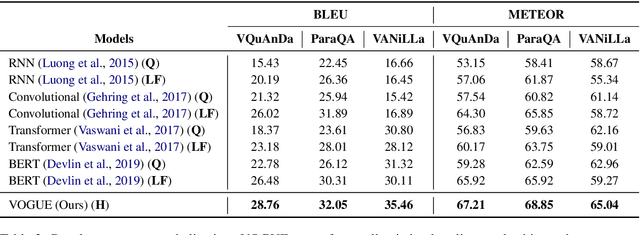
In recent years, there have been significant developments in Question Answering over Knowledge Graphs (KGQA). Despite all the notable advancements, current KGQA systems only focus on answer generation techniques and not on answer verbalization. However, in real-world scenarios (e.g., voice assistants such as Alexa, Siri, etc.), users prefer verbalized answers instead of a generated response. This paper addresses the task of answer verbalization for (complex) question answering over knowledge graphs. In this context, we propose a multi-task-based answer verbalization framework: VOGUE (Verbalization thrOuGh mUlti-task lEarning). The VOGUE framework attempts to generate a verbalized answer using a hybrid approach through a multi-task learning paradigm. Our framework can generate results based on using questions and queries as inputs concurrently. VOGUE comprises four modules that are trained simultaneously through multi-task learning. We evaluate our framework on existing datasets for answer verbalization, and it outperforms all current baselines on both BLEU and METEOR scores.
KGPool: Dynamic Knowledge Graph Context Selection for Relation Extraction
Jun 06, 2021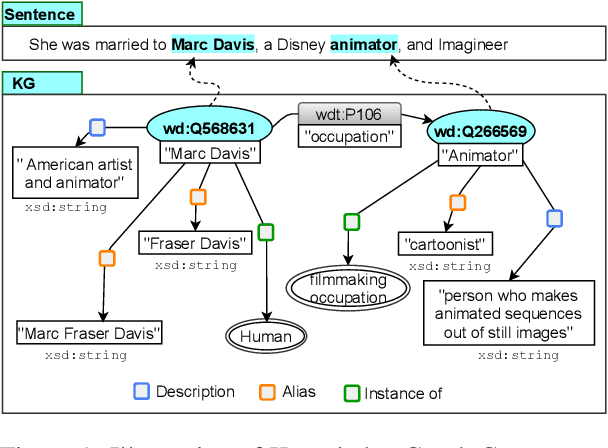
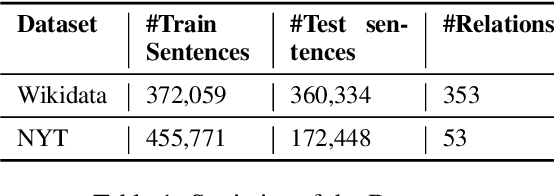
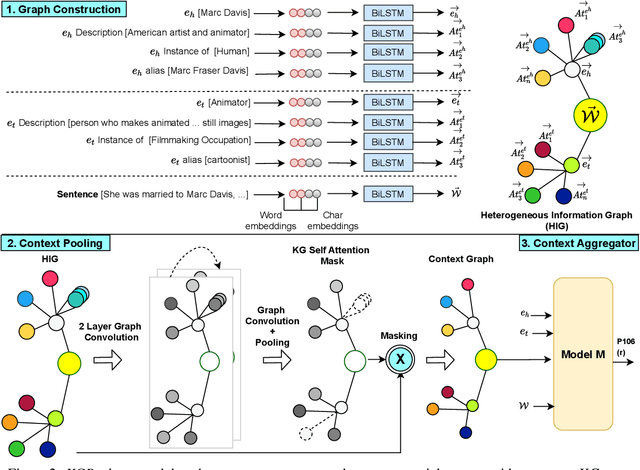
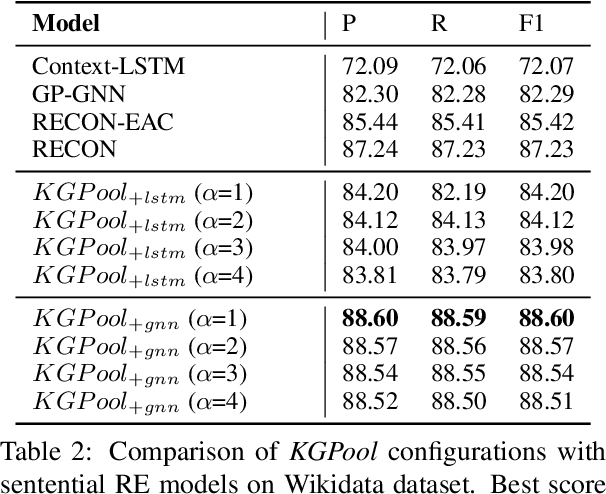
We present a novel method for relation extraction (RE) from a single sentence, mapping the sentence and two given entities to a canonical fact in a knowledge graph (KG). Especially in this presumed sentential RE setting, the context of a single sentence is often sparse. This paper introduces the KGPool method to address this sparsity, dynamically expanding the context with additional facts from the KG. It learns the representation of these facts (entity alias, entity descriptions, etc.) using neural methods, supplementing the sentential context. Unlike existing methods that statically use all expanded facts, KGPool conditions this expansion on the sentence. We study the efficacy of KGPool by evaluating it with different neural models and KGs (Wikidata and NYT Freebase). Our experimental evaluation on standard datasets shows that by feeding the KGPool representation into a Graph Neural Network, the overall method is significantly more accurate than state-of-the-art methods.
Conversational Question Answering over Knowledge Graphs with Transformer and Graph Attention Networks
Apr 04, 2021
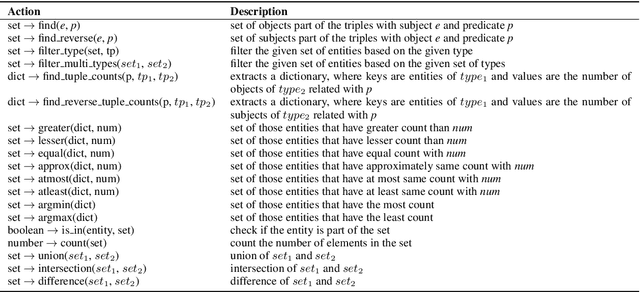
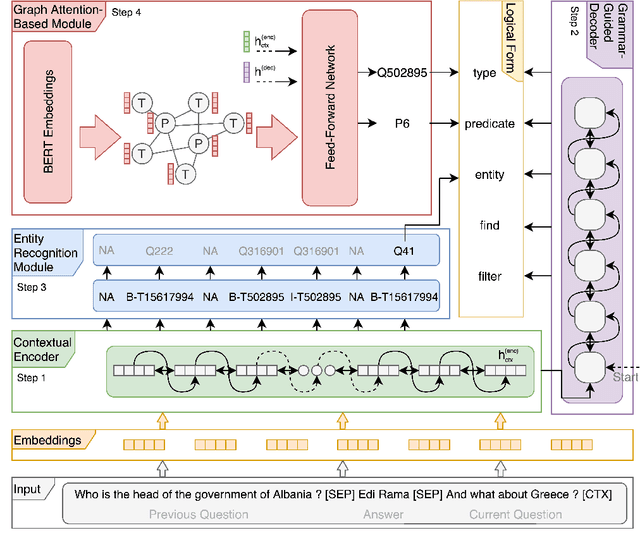
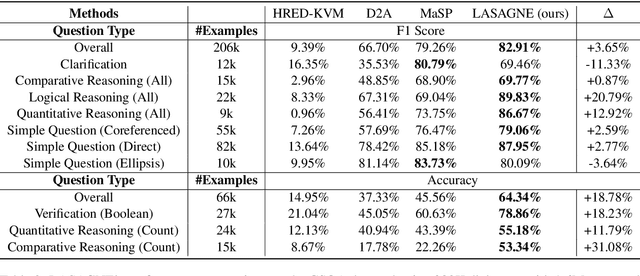
This paper addresses the task of (complex) conversational question answering over a knowledge graph. For this task, we propose LASAGNE (muLti-task semAntic parSing with trAnsformer and Graph atteNtion nEtworks). It is the first approach, which employs a transformer architecture extended with Graph Attention Networks for multi-task neural semantic parsing. LASAGNE uses a transformer model for generating the base logical forms, while the Graph Attention model is used to exploit correlations between (entity) types and predicates to produce node representations. LASAGNE also includes a novel entity recognition module which detects, links, and ranks all relevant entities in the question context. We evaluate LASAGNE on a standard dataset for complex sequential question answering, on which it outperforms existing baseline averages on all question types. Specifically, we show that LASAGNE improves the F1-score on eight out of ten question types; in some cases, the increase in F1-score is more than 20% compared to the state of the art.