 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure over Pixels: Learning Variable-Length Visual Programs
May 28, 2026Discrete visual tokenizers translate images into ordered sequences of codes, providing a natural representation for structural description of scenes. Yet existing adaptive tokenizers either require post-hoc search or select among a discrete set of pre-trained rates, rather than learning a continuous per-image sequence length coupled to the model and scene, and they typically train against pixel reconstruction, emphasizing texture rather than structure. We propose STROP, a discrete visual tokenizer architecture that forms structural scene representations and simultaneously learns how long an image's visual program should be. Using a four-phase curriculum supervised by local rate--distortion probes against frozen DINOv3 features, STROP optimizes a dedicated length head that estimates the active prefix length in a single forward pass. By bypassing pixel-level reconstruction gradients, the codebook is shaped entirely by the quality of higher-level latent representations. Program length grows with scene complexity, and signs of compositional structure emerge both in downstream dense-prediction transfer and in direct inspection of the learned code vocabulary.
Physics-Informed Spectral Modeling for Hyperspectral Imaging
Aug 29, 2025We present PhISM, a physics-informed deep learning architecture that learns without supervision to explicitly disentangle hyperspectral observations and model them with continuous basis functions. \mname outperforms prior methods on several classification and regression benchmarks, requires limited labeled data, and provides additional insights thanks to interpretable latent representation.
Generative Learning of Differentiable Object Models for Compositional Interpretation of Complex Scenes
Jun 09, 2025This study builds on the architecture of the Disentangler of Visual Priors (DVP), a type of autoencoder that learns to interpret scenes by decomposing the perceived objects into independent visual aspects of shape, size, orientation, and color appearance. These aspects are expressed as latent parameters which control a differentiable renderer that performs image reconstruction, so that the model can be trained end-to-end with gradient using reconstruction loss. In this study, we extend the original DVP so that it can handle multiple objects in a scene. We also exploit the interpretability of its latent by using the decoder to sample additional training examples and devising alternative training modes that rely on loss functions defined not only in the image space, but also in the latent space. This significantly facilitates training, which is otherwise challenging due to the presence of extensive plateaus in the image-space reconstruction loss. To examine the performance of this approach, we propose a new benchmark featuring multiple 2D objects, which subsumes the previously proposed Multi-dSprites dataset while being more parameterizable. We compare the DVP extended in these ways with two baselines (MONet and LIVE) and demonstrate its superiority in terms of reconstruction quality and capacity to decompose overlapping objects. We also analyze the gradients induced by the considered loss functions, explain how they impact the efficacy of training, and discuss the limitations of differentiable rendering in autoencoders and the ways in which they can be addressed.
Learning Semantics-aware Search Operators for Genetic Programming
Feb 06, 2025Fitness landscapes in test-based program synthesis are known to be extremely rugged, with even minimal modifications of programs often leading to fundamental changes in their behavior and, consequently, fitness values. Relying on fitness as the only guidance in iterative search algorithms like genetic programming is thus unnecessarily limiting, especially when combined with purely syntactic search operators that are agnostic about their impact on program behavior. In this study, we propose a semantics-aware search operator that steers the search towards candidate programs that are valuable not only actually (high fitness) but also only potentially, i.e. are likely to be turned into high-quality solutions even if their current fitness is low. The key component of the method is a graph neural network that learns to model the interactions between program instructions and processed data, and produces a saliency map over graph nodes that represents possible search decisions. When applied to a suite of symbolic regression benchmarks, the proposed method outperforms conventional tree-based genetic programming and the ablated variant of the method.
Autoassociative Learning of Structural Representations for Modeling and Classification in Medical Imaging
Nov 18, 2024Deep learning architectures based on convolutional neural networks tend to rely on continuous, smooth features. While this characteristics provides significant robustness and proves useful in many real-world tasks, it is strikingly incompatible with the physical characteristic of the world, which, at the scale in which humans operate, comprises crisp objects, typically representing well-defined categories. This study proposes a class of neurosymbolic systems that learn by reconstructing the observed images in terms of visual primitives and are thus forced to form high-level, structural explanations of them. When applied to the task of diagnosing abnormalities in histological imaging, the method proved superior to a conventional deep learning architecture in terms of classification accuracy, while being more transparent.
Learning to Solve Abstract Reasoning Problems with Neurosymbolic Program Synthesis and Task Generation
Oct 06, 2024The ability to think abstractly and reason by analogy is a prerequisite to rapidly adapt to new conditions, tackle newly encountered problems by decomposing them, and synthesize knowledge to solve problems comprehensively. We present TransCoder, a method for solving abstract problems based on neural program synthesis, and conduct a comprehensive analysis of decisions made by the generative module of the proposed architecture. At the core of TransCoder is a typed domain-specific language, designed to facilitate feature engineering and abstract reasoning. In training, we use the programs that failed to solve tasks to generate new tasks and gather them in a synthetic dataset. As each synthetic task created in this way has a known associated program (solution), the model is trained on them in supervised mode. Solutions are represented in a transparent programmatic form, which can be inspected and verified. We demonstrate TransCoder's performance using the Abstract Reasoning Corpus dataset, for which our framework generates tens of thousands of synthetic problems with corresponding solutions and facilitates systematic progress in learning.
Disentangling Visual Priors: Unsupervised Learning of Scene Interpretations with Compositional Autoencoder
Sep 15, 2024Contemporary deep learning architectures lack principled means for capturing and handling fundamental visual concepts, like objects, shapes, geometric transforms, and other higher-level structures. We propose a neurosymbolic architecture that uses a domain-specific language to capture selected priors of image formation, including object shape, appearance, categorization, and geometric transforms. We express template programs in that language and learn their parameterization with features extracted from the scene by a convolutional neural network. When executed, the parameterized program produces geometric primitives which are rendered and assessed for correspondence with the scene content and trained via auto-association with gradient. We confront our approach with a baseline method on a synthetic benchmark and demonstrate its capacity to disentangle selected aspects of the image formation process, learn from small data, correct inference in the presence of noise, and out-of-sample generalization.
Learning Abstract Visual Reasoning via Task Decomposition: A Case Study in Raven Progressive Matrices
Aug 12, 2023



One of the challenges in learning to perform abstract reasoning is that problems are often posed as monolithic tasks, with no intermediate subgoals. In Raven Progressive Matrices (RPM), the task is to choose one of the available answers given a context, where both contexts and answers are composite images featuring multiple objects in various spatial arrangements. As this high-level goal is the only guidance available, learning is challenging and most contemporary solvers tend to be opaque. In this study, we propose a deep learning architecture based on the transformer blueprint which, rather than directly making the above choice, predicts the visual properties of individual objects and their arrangements. The multidimensional predictions obtained in this way are then directly juxtaposed to choose the answer. We consider a few ways in which the model parses the visual input into tokens and several regimes of masking parts of the input in self-supervised training. In experimental assessment, the models not only outperform state-of-the-art methods but also provide interesting insights and partial explanations about the inference. The design of the method also makes it immune to biases that are known to exist in some RPM benchmarks.
Ain't Nobody Got Time For Coding: Structure-Aware Program Synthesis From Natural Language
Oct 23, 2018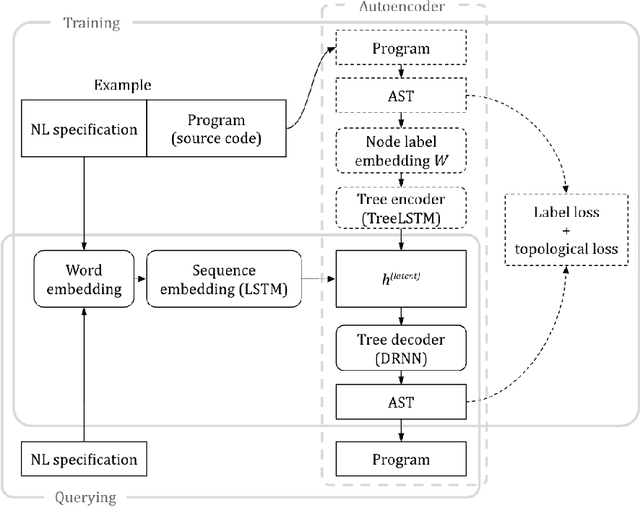
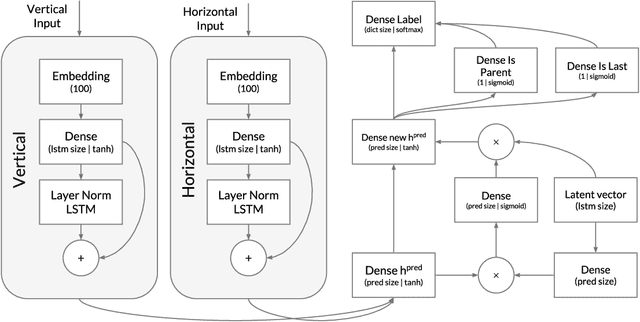
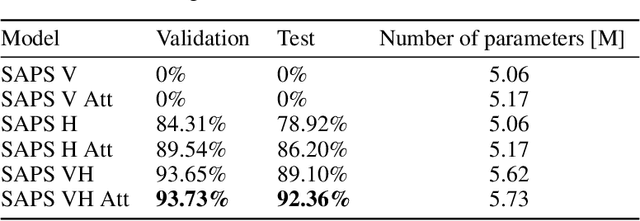
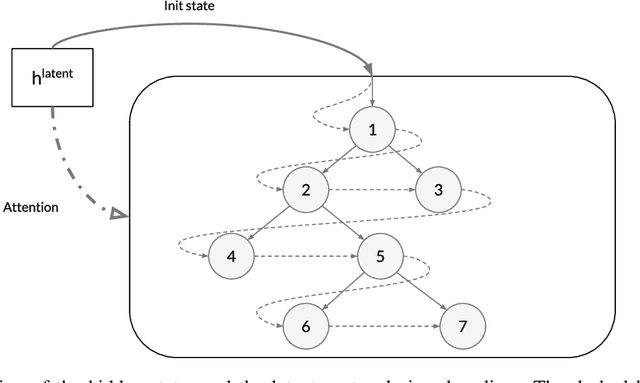
Program synthesis from natural language (NL) is practical for humans and, once technically feasible, would significantly facilitate software development and revolutionize end-user programming. We present SAPS, an end-to-end neural network capable of mapping relatively complex, multi-sentence NL specifications to snippets of executable code. The proposed architecture relies exclusively on neural components, and is built upon a tree2tree autoencoder trained on abstract syntax trees, combined with a pretrained word embedding and a bi-directional multi-layer LSTM for NL processing. The decoder features a doubly-recurrent LSTM with a novel signal propagation scheme and soft attention mechanism. When applied to a large dataset of problems proposed in a previous study, SAPS performs on par with or better than the method proposed there, producing correct programs in over 90% of cases. In contrast to other methods, it does not involve any non-neural components to post-process the resulting programs, and uses a fixed-dimensional latent representation as the only link between the NL analyzer and source code generator.
Learning to Play Othello with Deep Neural Networks
Nov 17, 2017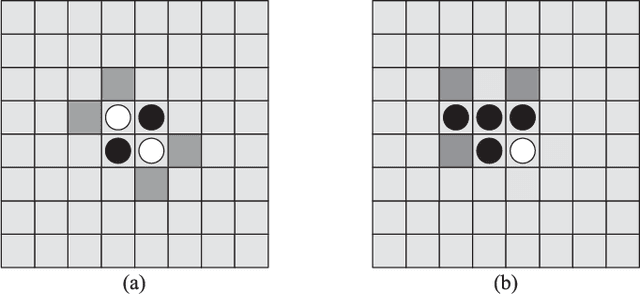
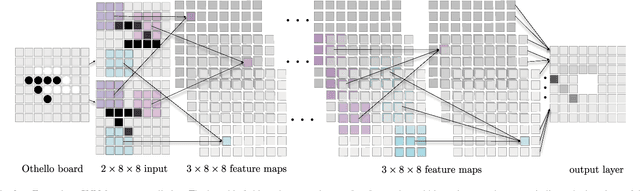
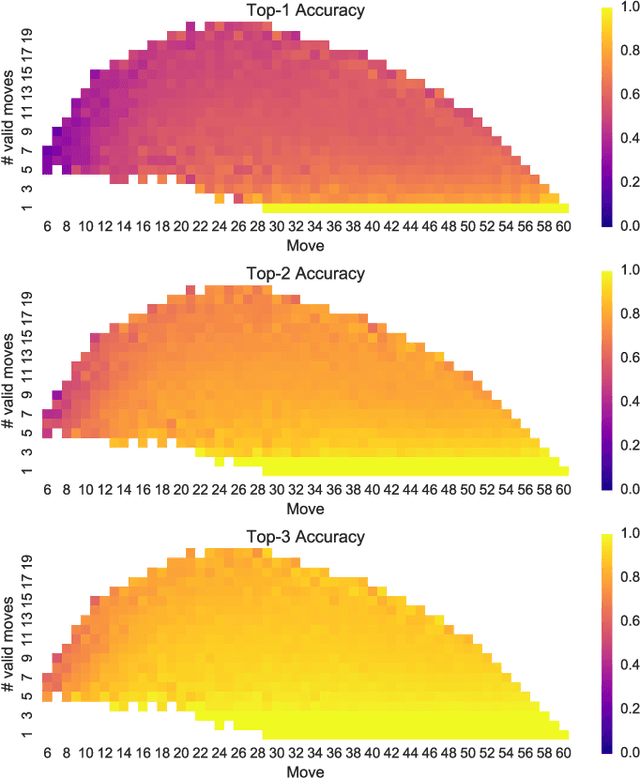
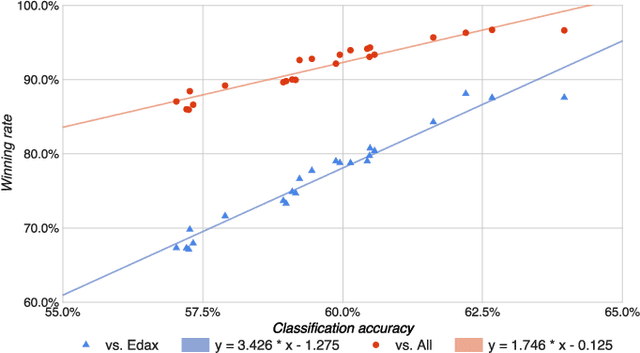
Achieving superhuman playing level by AlphaGo corroborated the capabilities of convolutional neural architectures (CNNs) for capturing complex spatial patterns. This result was to a great extent due to several analogies between Go board states and 2D images CNNs have been designed for, in particular translational invariance and a relatively large board. In this paper, we verify whether CNN-based move predictors prove effective for Othello, a game with significantly different characteristics, including a much smaller board size and complete lack of translational invariance. We compare several CNN architectures and board encodings, augment them with state-of-the-art extensions, train on an extensive database of experts' moves, and examine them with respect to move prediction accuracy and playing strength. The empirical evaluation confirms high capabilities of neural move predictors and suggests a strong correlation between prediction accuracy and playing strength. The best CNNs not only surpass all other 1-ply Othello players proposed to date but defeat (2-ply) Edax, the best open-source Othello player.