 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Specific Pruning with LLM-Sieve: How Many Parameters Does Your Task Really Need?
May 23, 2025



As Large Language Models (LLMs) are increasingly being adopted for narrow tasks - such as medical question answering or sentiment analysis - and deployed in resource-constrained settings, a key question arises: how many parameters does a task actually need? In this work, we present LLM-Sieve, the first comprehensive framework for task-specific pruning of LLMs that achieves 20-75% parameter reduction with only 1-5% accuracy degradation across diverse domains. Unlike prior methods that apply uniform pruning or rely on low-rank approximations of weight matrices or inputs in isolation, LLM-Sieve (i) learns task-aware joint projections to better approximate output behavior, and (ii) employs a Genetic Algorithm to discover differentiated pruning levels for each matrix. LLM-Sieve is fully compatible with LoRA fine-tuning and quantization, and uniquely demonstrates strong generalization across datasets within the same task domain. Together, these results establish a practical and robust mechanism to generate smaller performant task-specific models.
Minimum Cost Active Labeling
Jun 24, 2020
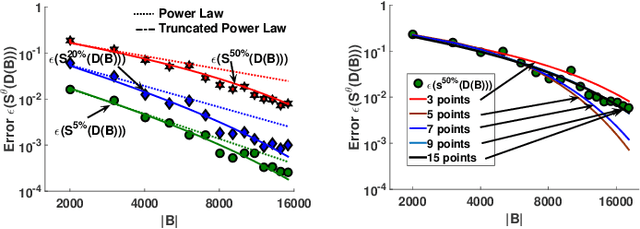
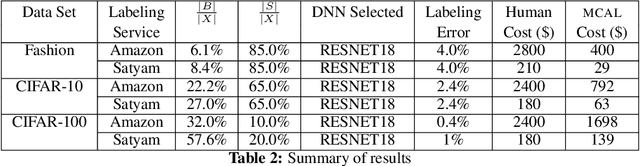
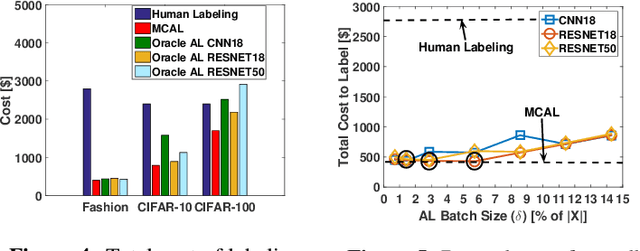
Labeling a data set completely is important for groundtruth generation. In this paper, we consider the problem of minimum-cost labeling: classifying all images in a large data set with a target accuracy bound at minimum dollar cost. Human labeling can be prohibitive, so we train a classifier to accurately label part of the data set. However, training the classifier can be expensive too, particularly with active learning. Our min-cost labeling uses a variant of active learning to learn a model to predict the optimal training set size for the classifier that minimizes overall cost, then uses active learning to train the classifier to maximize the number of samples the classifier can correctly label. We validate our approach on well-known public data sets such as Fashion, CIFAR-10, and CIFAR-100. In some cases, our approach has 6X lower overall cost relative to human labeling, and is always cheaper than the cheapest active learning strategy.
Satyam: Democratizing Groundtruth for Machine Vision
Nov 08, 2018
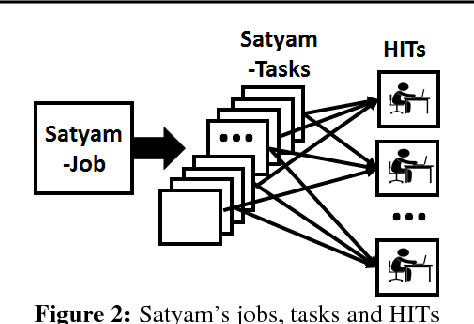
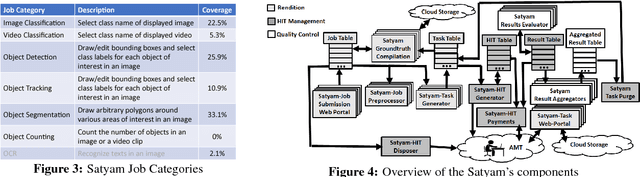

The democratization of machine learning (ML) has led to ML-based machine vision systems for autonomous driving, traffic monitoring, and video surveillance. However, true democratization cannot be achieved without greatly simplifying the process of collecting groundtruth for training and testing these systems. This groundtruth collection is necessary to ensure good performance under varying conditions. In this paper, we present the design and evaluation of Satyam, a first-of-its-kind system that enables a layperson to launch groundtruth collection tasks for machine vision with minimal effort. Satyam leverages a crowdtasking platform, Amazon Mechanical Turk, and automates several challenging aspects of groundtruth collection: creating and launching of custom web-UI tasks for obtaining the desired groundtruth, controlling result quality in the face of spammers and untrained workers, adapting prices to match task complexity, filtering spammers and workers with poor performance, and processing worker payments. We validate Satyam using several popular benchmark vision datasets, and demonstrate that groundtruth obtained by Satyam is comparable to that obtained from trained experts and provides matching ML performance when used for training.