 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe use of Recommender Systems in web technology and an in-depth analysis of Cold State problem
Sep 10, 2020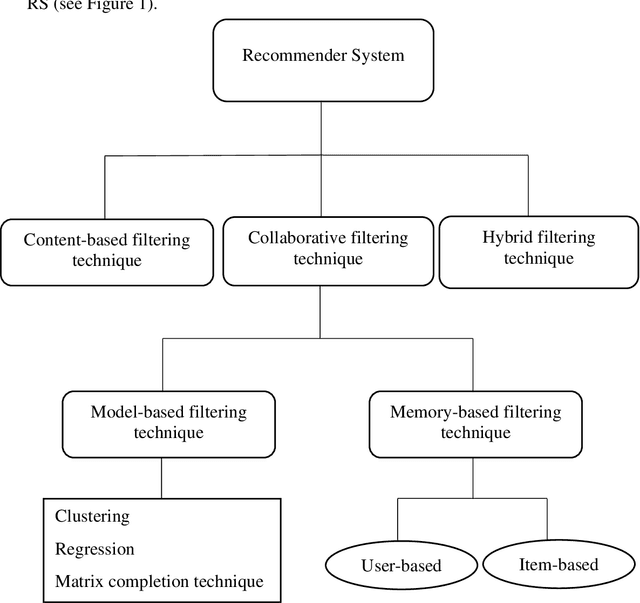
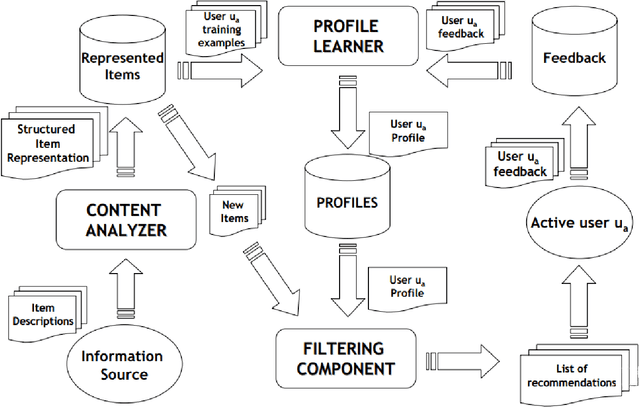
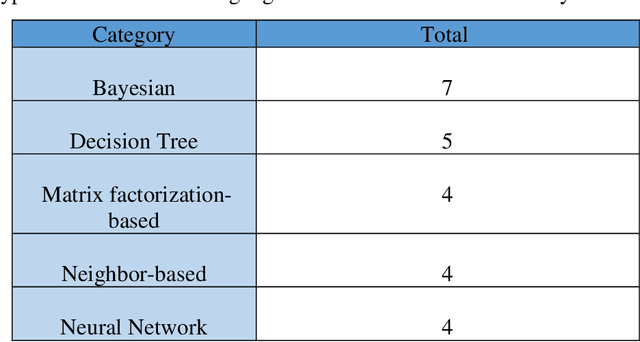
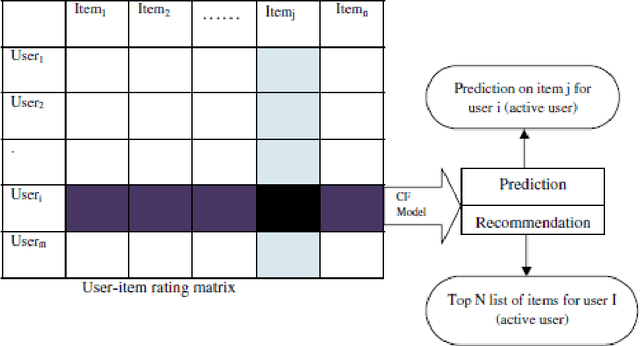
In the WWW (World Wide Web), dynamic development and spread of data has resulted a tremendous amount of information available on the Internet, yet user is unable to find relevant information in a short span of time. Consequently, a system called recommendation system developed to help users find their infromation with ease through their browsing activities. In other words, recommender systems are tools for interacting with large amount of information that provide personalized view for prioritizing items likely to be of keen for users. They have developed over the years in artificial intelligence techniques that include machine learning and data mining amongst many to mention. Furthermore, the recommendation systems have personalized on an e-commerce, on-line applications such as Amazon.com, Netflix, and Booking.com. As a result, this has inspired many researchers to extend the reach of recommendation systems into new sets of challenges and problem areas that are yet to be truly solved, primarily a problem with the case of making a recommendation to a new user that is called cold-state (i.e. cold-start) user problem where the new user might likely not yield much of information searched. Therfore, the purpose of this paper is to tackle the said cold-start problem with a few effecient methods and challenges, as well as identify and overview the current state of recommendation system as a whole
Fraud Detection using Data-Driven approach
Sep 08, 2020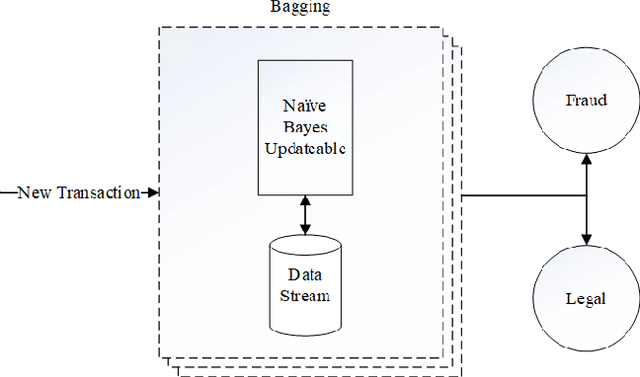
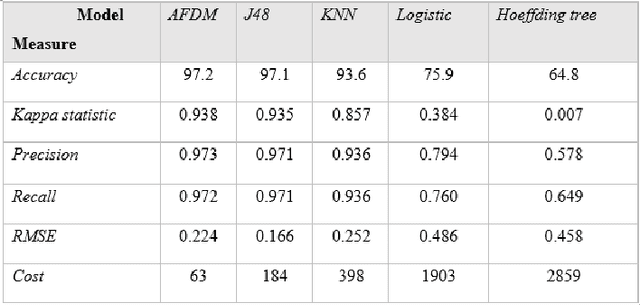
The extensive use of the internet is continuously drifting businesses to incorporate their services in the online environment. One of the first spectrums to embrace this evolution was the banking sector. In fact, the first known online banking service came in 1980. It was deployed from a community bank located in Knoxville, called the United American Bank. Since then, internet banking has been offering ease and efficiency to costumers in completing their daily banking tasks. The ever increasing use of internet banking and a large number of online transactions increased fraudulent behavior also. As if fraud increase was not enough, the massive number of online transactions further increased the data complexity. Modern data sources are not only complex but generated at high speed and in real-time as well. This presents a serious problem and a definite reason why more advanced solutions are desired to protect financial service companies and credit cardholders. Therefore, this research paper aims to construct an efficient fraud detection model which is adaptive to customer behavior changes and tends to decrease fraud manipulation, by detecting and filtering fraud in real-time. In order to achieve this aim, a review of various methods is conducted, adding above a personal experience working in the Banking sector, specifically in the Fraud Detection office. Unlike the majority of reviewed methods, the proposed model in this research paper is able to detect fraud in the moment of occurrence using an incremental classifier. The evaluation of synthetic data, based on fraud scenarios selected in collaboration with domain experts that replicate typical, real-world attacks, shows that this approach correctly ranks complex frauds. In particular, our proposal detects fraudulent behavior and anomalies with up to 97\% detection rate while maintaining a satisfyingly low cost.