 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing a personalized learning path using genetic algorithms approach
Apr 22, 2021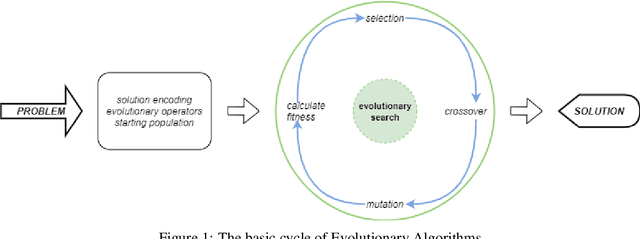
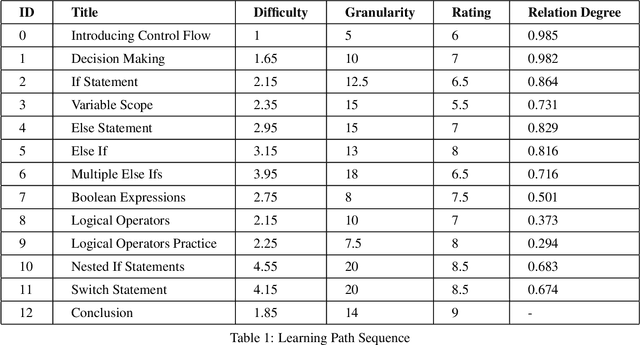
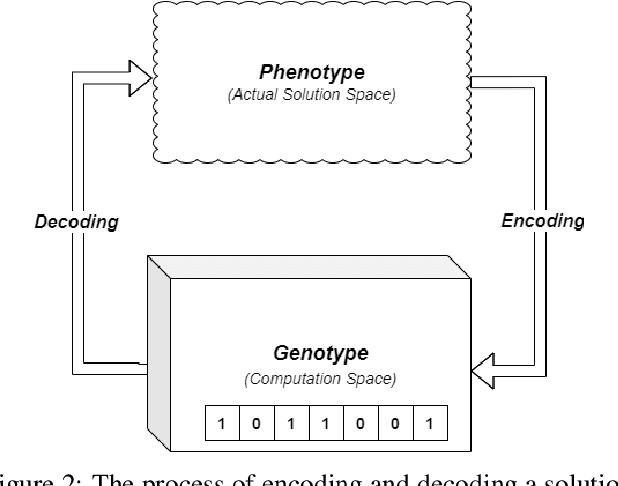
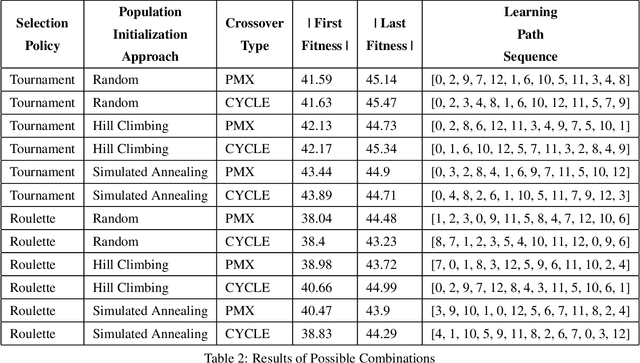
A substantial disadvantage of traditional learning is that all students follow the same learning sequence, but not all of them have the same background of knowledge, the same preferences, the same learning goals, and the same needs. Traditional teaching resources, such as textbooks, in most cases pursue students to follow fixed sequences during the learning process, thus impairing their performance. Learning sequencing is an important research issue as part of the learning process because no fixed learning paths will be appropriate for all learners. For this reason, many research papers are focused on the development of mechanisms to offer personalization on learning paths, considering the learner needs, interests, behaviors, and abilities. In most cases, these researchers are totally focused on the student's preferences, ignoring the level of difficulty and the relation degree that exists between various concepts in a course. This research paper presents the possibility of constructing personalized learning paths using genetic algorithm-based model, encountering the level of difficulty and relation degree of the constituent concepts of a course. The experimental results shows that the genetic algorithm is suitable to generate optimal learning paths based on learning object difficulty level, duration, rating, and relation degree between each learning object as elementary parts of the sequence of the learning path. From these results compared to the quality of the traditional learning path, we observed that even the quality of the weakest learning path generated by our GA approach is in a favor compared to quality of the traditional learning path, with a difference of 3.59\%, while the highest solution generated in the end resulted 8.34\% in favor of our proposal compared to the traditional learning paths.
Classification of Pedagogical content using conventional machine learning and deep learning model
Jan 18, 2021



The advent of the Internet and a large number of digital technologies has brought with it many different challenges. A large amount of data is found on the web, which in most cases is unstructured and unorganized, and this contributes to the fact that the use and manipulation of this data is quite a difficult process. Due to this fact, the usage of different machine and deep learning techniques for Text Classification has gained its importance, which improved this discipline and made it more interesting for scientists and researchers for further study. This paper aims to classify the pedagogical content using two different models, the K-Nearest Neighbor (KNN) from the conventional models and the Long short-term memory (LSTM) recurrent neural network from the deep learning models. The result indicates that the accuracy of classifying the pedagogical content reaches 92.52 % using KNN model and 87.71 % using LSTM model.
Aspect-Based Sentiment Analysis in Education Domain
Oct 03, 2020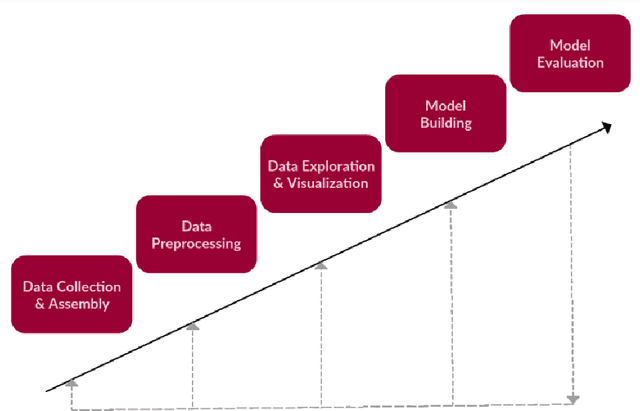
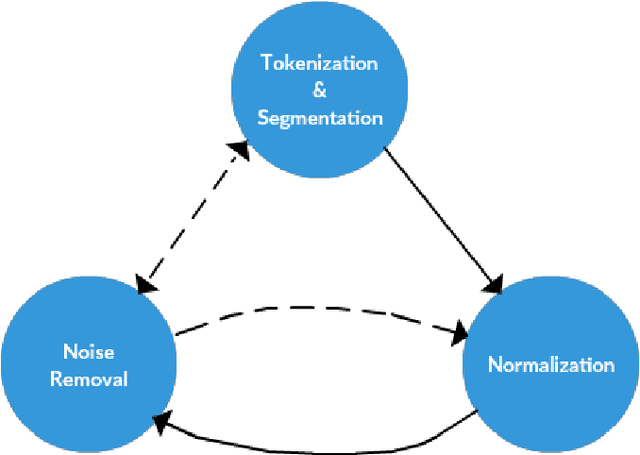
Analysis of a large amount of data has always brought value to institutions and organizations. Lately, people's opinions expressed through text have become a very important aspect of this analysis. In response to this challenge, a natural language processing technique known as Aspect-Based Sentiment Analysis (ABSA) has emerged. Having the ability to extract the polarity for each aspect of opinions separately, ABSA has found itself useful in a wide range of domains. Education is one of the domains in which ABSA can be successfully utilized. Being able to understand and find out what students like and don't like most about a course, professor, or teaching methodology can be of great importance for the respective institutions. While this task represents a unique NLP challenge, many studies have proposed different approaches to tackle the problem. In this work, we present a comprehensive review of the existing work in ABSA with a focus in the education domain. A wide range of methodologies are discussed and conclusions are drawn.