 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Hidden-State Dynamics as a Signature of Internal Reasoning in Large Language Models
May 03, 2026Large reasoning models (LRMs) generate extended solutions, yet it remains unclear whether these traces reflect substantive internal computation or merely verbosity and overthinking. Although recent hidden-state analyses suggest that internal representations carry correctness-related signals, their coarse aggregations may obscure the token and layer structure underlying reasoning computation. We investigate hidden-state transitions across decoding steps and layers, and identify a distinct spatiotemporal pattern in LRMs: successful trajectories exhibit broad temporal dynamics with localized layer-wise concentration, while this structure is weaker in non-reasoning models and knowledge-heavy domains. We formalize this characteristic as Spatiotemporal Amplitude of Latent Transition (StALT), a training-free trajectory statistic that summarizes temporal changes between adjacent tokens weighted by within-token layer saliency. Across diverse models and benchmarks, StALT reliably separates correct from incorrect trajectories in reasoning-intensive regimes, providing a competitive label-free correctness signal alongside strong output-space and length-based baselines. Intervention analyses further show that this spatiotemporal amplitude responds systematically to manipulations that increase or reduce the demand for internal reasoning, supporting its association with latent reasoning dynamics in LRMs. These findings provide empirical evidence that LRMs exhibit measurable hidden-state dynamics and offer a practical probe for understanding internal computation beyond output-based evaluation.
The Geometry of Dialogue: Graphing Language Models to Reveal Synergistic Teams for Multi-Agent Collaboration
Oct 30, 2025While a multi-agent approach based on large language models (LLMs) represents a promising strategy to surpass the capabilities of single models, its success is critically dependent on synergistic team composition. However, forming optimal teams is a significant challenge, as the inherent opacity of most models obscures the internal characteristics necessary for effective collaboration. In this paper, we propose an interaction-centric framework for automatic team composition that does not require any prior knowledge including their internal architectures, training data, or task performances. Our method constructs a "language model graph" that maps relationships between models from the semantic coherence of pairwise conversations, and then applies community detection to identify synergistic model clusters. Our experiments with diverse LLMs demonstrate that the proposed method discovers functionally coherent groups that reflect their latent specializations. Priming conversations with specific topics identified synergistic teams which outperform random baselines on downstream benchmarks and achieve comparable accuracy to that of manually-curated teams based on known model specializations. Our findings provide a new basis for the automated design of collaborative multi-agent LLM teams.
STDP enhances learning by backpropagation in a spiking neural network
Feb 21, 2021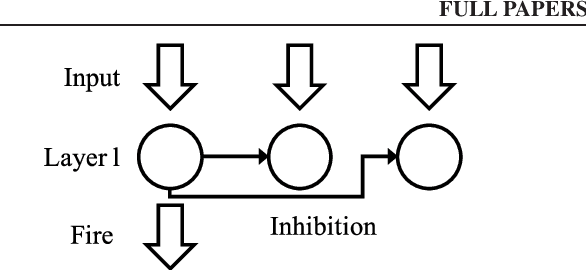
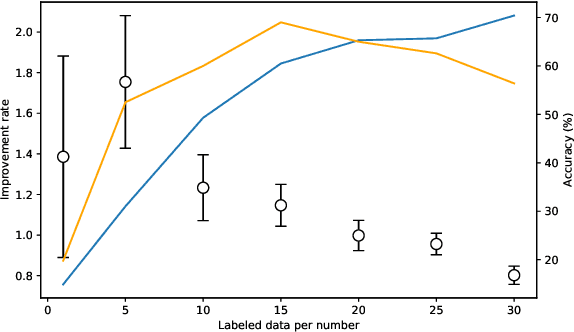
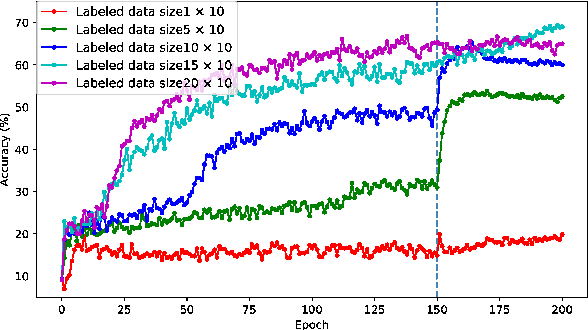
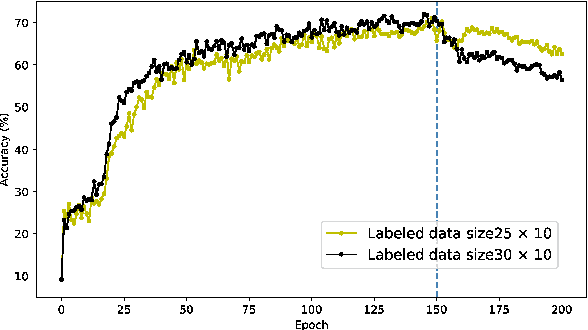
A semi-supervised learning method for spiking neural networks is proposed. The proposed method consists of supervised learning by backpropagation and subsequent unsupervised learning by spike-timing-dependent plasticity (STDP), which is a biologically plausible learning rule. Numerical experiments show that the proposed method improves the accuracy without additional labeling when a small amount of labeled data is used. This feature has not been achieved by existing semi-supervised learning methods of discriminative models. It is possible to implement the proposed learning method for event-driven systems. Hence, it would be highly efficient in real-time problems if it were implemented on neuromorphic hardware. The results suggest that STDP plays an important role other than self-organization when applied after supervised learning, which differs from the previous method of using STDP as pre-training interpreted as self-organization.