 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Learning of a Graph-Based Neural Network Model Without Backpropagation
Dec 20, 2025



We propose a structural-graph approach to classifying contour images in a few-shot regime without using backpropagation. The core idea is to make structure the carrier of explanations: an image is encoded as an attributed graph (critical points and lines represented as nodes with geometric attributes), and generalization is achieved via the formation of concept attractors (class-level concept graphs). Purpose. To design and experimentally validate an architecture in which class concepts are formed from a handful of examples (5 - 6 per class) through structural and parametric reductions, providing transparent decisions and eliminating backpropagation. Methods. Contour vectorization is followed by constructing a bipartite graph (Point/Line as nodes) with normalized geometric attributes such as coordinates, length, angle, and direction; reductions include the elimination of unstable substructures or noise and the alignment of paths between critical points. Concepts are formed by iterative composition of samples, and classification is performed by selecting the best graph-to-concept match (using approximated GED). Results. On an MNIST subset with 5 - 6 base examples per class (single epoch), we obtain a consistent accuracy of around 82% with full traceability of decisions: misclassifications can be explained by explicit structural similarities. An indicative comparison with SVM, MLP, CNN, as well as metric and meta-learning baselines, is provided. The structural-graph scheme with concept attractors enables few-shot learning without backpropagation and offers built-in explanations through the explicit graph structure. Limitations concern the computational cost of GED and the quality of skeletonization; promising directions include classification-algorithm optimization, work with static scenes, and associative recognition.
Accelerating recurrent neural network training using sequence bucketing and multi-GPU data parallelization
Aug 18, 2017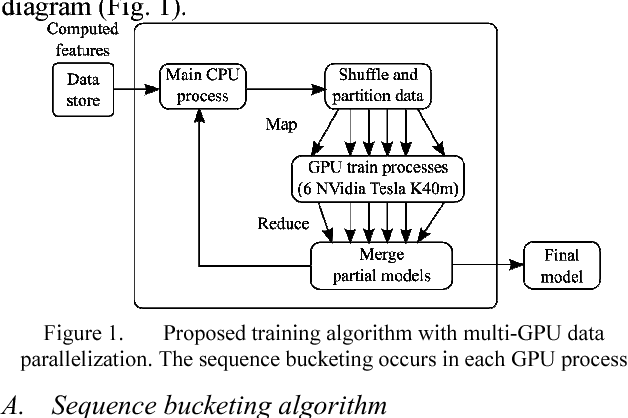
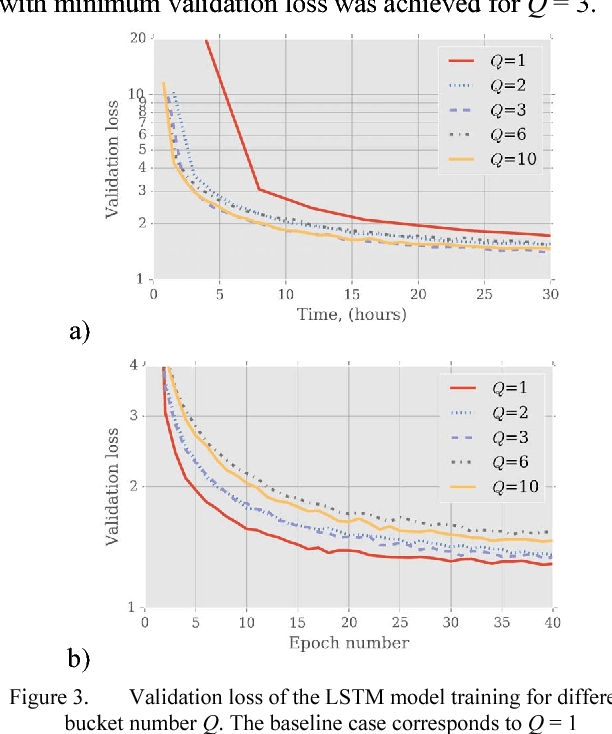
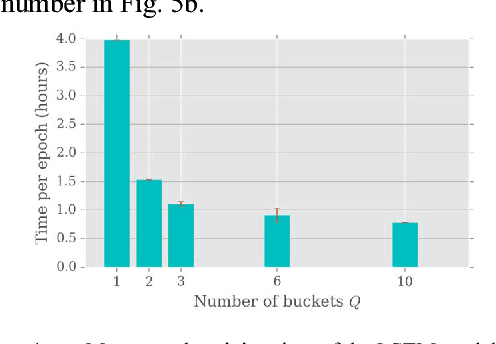
An efficient algorithm for recurrent neural network training is presented. The approach increases the training speed for tasks where a length of the input sequence may vary significantly. The proposed approach is based on the optimal batch bucketing by input sequence length and data parallelization on multiple graphical processing units. The baseline training performance without sequence bucketing is compared with the proposed solution for a different number of buckets. An example is given for the online handwriting recognition task using an LSTM recurrent neural network. The evaluation is performed in terms of the wall clock time, number of epochs, and validation loss value.
* 4 pages, 5 figures, Comments, 2016 IEEE First International Conference on Data Stream Mining & Processing (DSMP), Lviv, 2016