 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale When Needed: Adaptive Neuron-level Mixed Precision Quantization Aware Training
May 24, 2026Deploying deep neural networks on resource-constrained 6G edge devices demands aggressive compression with minimal accuracy loss. Quantization-Aware Training (QAT) has emerged as a leading compression approach; however, existing mixed-precision methods typically operate at coarse layer- or channel-level granularity. These methods often rely on heuristic or search-based bit-allocation strategies, which may overlook fine-grained variability at the neuron level. We propose Neuron-Level Mixed-Precision QAT (NMP-QAT), where each neuron independently learns its own discrete precision during training. Starting from low-bit precision, NMP-QAT expands bit-width only when training signals demand it, via differentiable surrogates and straight-through estimators, while preserving a fully discrete inference graph. This adaptability extends to both weights and activations, reducing memory movement. Evaluated on telecom and non-telecom datasets across MLP and tabular foundation model architectures, NMP-QAT achieves superior compression-accuracy trade-offs over mixed-precision QAT baselines, making it well-suited for Green AI deployments at the network edge.
When to restart? Exploring escalating restarts on convergence
Mar 04, 2026Learning rate scheduling plays a critical role in the optimization of deep neural networks, directly influencing convergence speed, stability, and generalization. While existing schedulers such as cosine annealing, cyclical learning rates, and warm restarts have shown promise, they often rely on fixed or periodic triggers that are agnostic to the training dynamics, such as stagnation or convergence behavior. In this work, we propose a simple yet effective strategy, which we call Stochastic Gradient Descent with Escalating Restarts (SGD-ER). It adaptively increases the learning rate upon convergence. Our method monitors training progress and triggers restarts when stagnation is detected, linearly escalating the learning rate to escape sharp local minima and explore flatter regions of the loss landscape. We evaluate SGD-ER across CIFAR-10, CIFAR-100, and TinyImageNet on a range of architectures including ResNet-18/34/50, VGG-16, and DenseNet-101. Compared to standard schedulers, SGD-ER improves test accuracy by 0.5-4.5%, demonstrating the benefit of convergence-aware escalating restarts for better local optima.
Unlearning Clients, Features and Samples in Vertical Federated Learning
Jan 23, 2025



Federated Learning (FL) has emerged as a prominent distributed learning paradigm. Within the scope of privacy preservation, information privacy regulations such as GDPR entitle users to request the removal (or unlearning) of their contribution from a service that is hosting the model. For this purpose, a server hosting an ML model must be able to unlearn certain information in cases such as copyright infringement or security issues that can make the model vulnerable or impact the performance of a service based on that model. While most unlearning approaches in FL focus on Horizontal FL (HFL), where clients share the feature space and the global model, Vertical FL (VFL) has received less attention from the research community. VFL involves clients (passive parties) sharing the sample space among them while not having access to the labels. In this paper, we explore unlearning in VFL from three perspectives: unlearning clients, unlearning features, and unlearning samples. To unlearn clients and features we introduce VFU-KD which is based on knowledge distillation (KD) while to unlearn samples, VFU-GA is introduced which is based on gradient ascent. To provide evidence of approximate unlearning, we utilize Membership Inference Attack (MIA) to audit the effectiveness of our unlearning approach. Our experiments across six tabular datasets and two image datasets demonstrate that VFU-KD and VFU-GA achieve performance comparable to or better than both retraining from scratch and the benchmark R2S method in many cases, with improvements of $(0-2\%)$. In the remaining cases, utility scores remain comparable, with a modest utility loss ranging from $1-5\%$. Unlike existing methods, VFU-KD and VFU-GA require no communication between active and passive parties during unlearning. However, they do require the active party to store the previously communicated embeddings.
Customized Video QoE Estimation with Algorithm-Agnostic Transfer Learning
Mar 12, 2020



The development of QoE models by means of Machine Learning (ML) is challenging, amongst others due to small-size datasets, lack of diversity in user profiles in the source domain, and too much diversity in the target domains of QoE models. Furthermore, datasets can be hard to share between research entities, as the machine learning models and the collected user data from the user studies may be IPR- or GDPR-sensitive. This makes a decentralized learning-based framework appealing for sharing and aggregating learned knowledge in-between the local models that map the obtained metrics to the user QoE, such as Mean Opinion Scores (MOS). In this paper, we present a transfer learning-based ML model training approach, which allows decentralized local models to share generic indicators on MOS to learn a generic base model, and then customize the generic base model further using additional features that are unique to those specific localized (and potentially sensitive) QoE nodes. We show that the proposed approach is agnostic to specific ML algorithms, stacked upon each other, as it does not necessitate the collaborating localized nodes to run the same ML algorithm. Our reproducible results reveal the advantages of stacking various generic and specific models with corresponding weight factors. Moreover, we identify the optimal combination of algorithms and weight factors for the corresponding localized QoE nodes.
Privacy Preserving QoE Modeling using Collaborative Learning
Jun 26, 2019
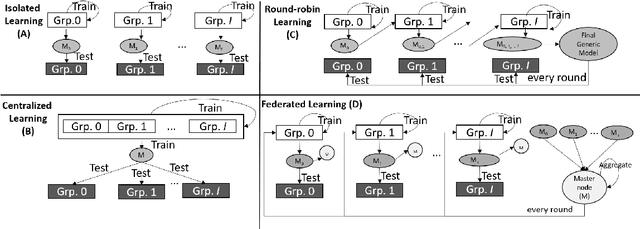


Machine Learning based Quality of Experience (QoE) models potentially suffer from over-fitting due to limitations including low data volume, and limited participant profiles. This prevents models from becoming generic. Consequently, these trained models may under-perform when tested outside the experimented population. One reason for the limited datasets, which we refer in this paper as small QoE data lakes, is due to the fact that often these datasets potentially contain user sensitive information and are only collected throughout expensive user studies with special user consent. Thus, sharing of datasets amongst researchers is often not allowed. In recent years, privacy preserving machine learning models have become important and so have techniques that enable model training without sharing datasets but instead relying on secure communication protocols. Following this trend, in this paper, we present Round-Robin based Collaborative Machine Learning model training, where the model is trained in a sequential manner amongst the collaborated partner nodes. We benchmark this work using our customized Federated Learning mechanism as well as conventional Centralized and Isolated Learning methods.