 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpper Generalization Bounds for Neural Oscillators
Mar 10, 2026Neural oscillators that originate from the second-order ordinary differential equations (ODEs) have shown competitive performance in learning mappings between dynamic loads and responses of complex nonlinear structural systems. Despite this empirical success, theoretically quantifying the generalization capacities of their neural network architectures remains undeveloped. In this study, the neural oscillator consisting of a second-order ODE followed by a multilayer perceptron (MLP) is considered. Its upper probably approximately correct (PAC) generalization bound for approximating causal and uniformly continuous operators between continuous temporal function spaces and that for approximating the uniformly asymptotically incrementally stable second-order dynamical systems are derived by leveraging the Rademacher complexity framework. The theoretical results show that the estimation errors grow polynomially with respect to both the MLP size and the time length, thereby avoiding the curse of parametric complexity. Furthermore, the derived error bounds demonstrate that constraining the Lipschitz constants of the MLPs via loss function regularization can improve the generalization ability of the neural oscillator. A numerical study considering a Bouc-Wen nonlinear system under stochastic seismic excitation validates the theoretically predicted power laws of the estimation errors with respect to the sample size and time length, and confirms the effectiveness of constraining MLPs' matrix and vector norms in enhancing the performance of the neural oscillator under limited training data.
Asymptotically Independent Markov Sampling: a new MCMC scheme for Bayesian Inference
Oct 09, 2011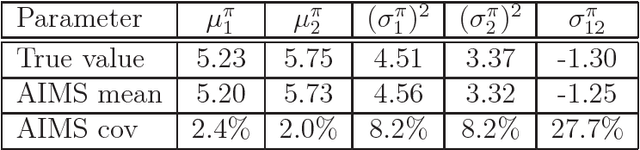

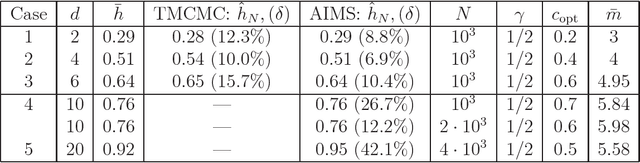
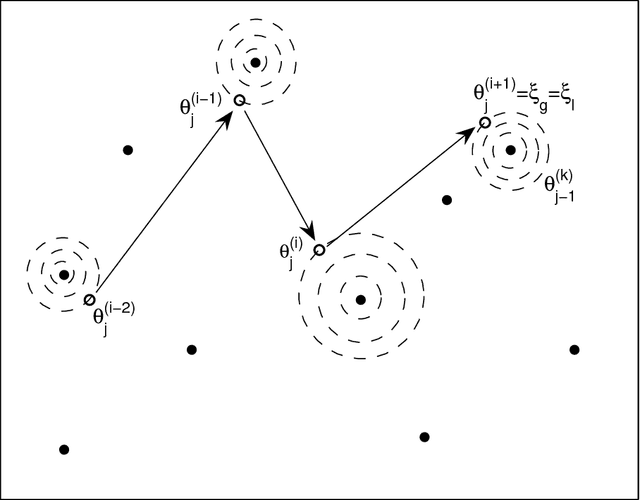
In Bayesian statistics, many problems can be expressed as the evaluation of the expectation of a quantity of interest with respect to the posterior distribution. Standard Monte Carlo method is often not applicable because the encountered posterior distributions cannot be sampled directly. In this case, the most popular strategies are the importance sampling method, Markov chain Monte Carlo, and annealing. In this paper, we introduce a new scheme for Bayesian inference, called Asymptotically Independent Markov Sampling (AIMS), which is based on the above methods. We derive important ergodic properties of AIMS. In particular, it is shown that, under certain conditions, the AIMS algorithm produces a uniformly ergodic Markov chain. The choice of the free parameters of the algorithm is discussed and recommendations are provided for this choice, both theoretically and heuristically based. The efficiency of AIMS is demonstrated with three numerical examples, which include both multi-modal and higher-dimensional target posterior distributions.