 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary-by-Mask: Few-Shot Instance Segmentation with Mask-Conditioned Boundary Learning for Texture-Poor Industrial Parts
Jun 19, 2026Recent advances in large pre-trained models have led to remarkable progress in instance segmentation on general images. However, industrial scenarios remain challenging. Instance definitions are often application-specific and inconsistent, and the domain gap from general imagery is substantial due to weak textures and limited contextual cues. Consequently, a direct application of existing models is unreliable. We propose Boundary-by-Mask, a few-shot instance segmentation framework that supervises boundaries instead of interior appearance. Given a few RGB images and corresponding instance masks, the method extracts rich visual features using a foundation-model encoder and trains a lightweight Signed Distance Function (SDF) head to predict boundary-aware distance maps. Segmentation masks are obtained through an SDF-to-mask reconstruction process. By explicitly estimating contours, the framework achieves reliable instance separation even on low-texture and color-uniform surfaces. The instance definition is conditioned by the instance mask. Replacing the mask specifies the segmentation target, such as the whole object or a sub-part. A pixel-wise shallow MLP head enables rapid training. Experiments on industrial parts and food items with ambiguous boundaries show strong few-shot generalization, robustness in feature-poor conditions, and precise control over mask-level targets.
Animated Stickies: Fast Video Projection Mapping onto a Markerless Plane through a Direct Closed-Loop Alignment
Aug 30, 2019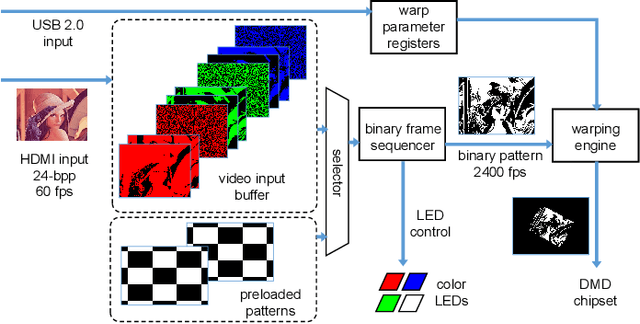
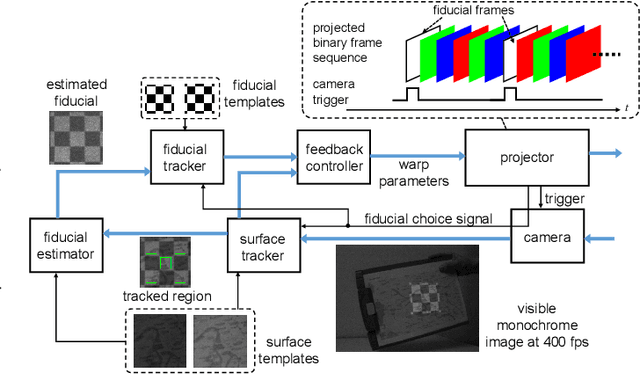


This paper presents a fast projection mapping method for moving image content projected onto a markerless planar surface using a low-latency Digital Micromirror Device (DMD) projector. By adopting a closed-loop alignment approach, in which not only the surface texture but also the projected image is tracked by a camera, the proposed method is free from a calibration or position adjustment between the camera and projector. We designed fiducial patterns to be inserted into a fast flapping sequence of binary frames of the DMD projector, which allows the simultaneous tracking of the surface texture and a fiducial geometry separate from a single image captured by the camera. The proposed method implemented on a CPU runs at 400 fps and enables arbitrary video contents to be "stuck" onto a variety of textured surfaces.
Spatiotemporal Learning of Dynamic Gestures from 3D Point Cloud Data
Apr 24, 2018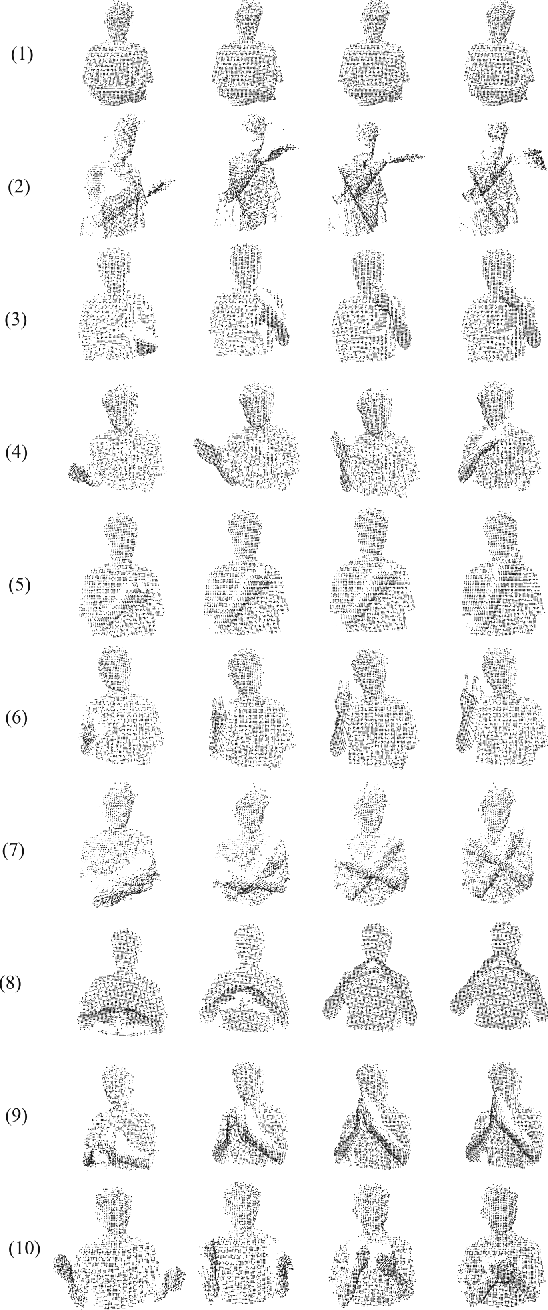
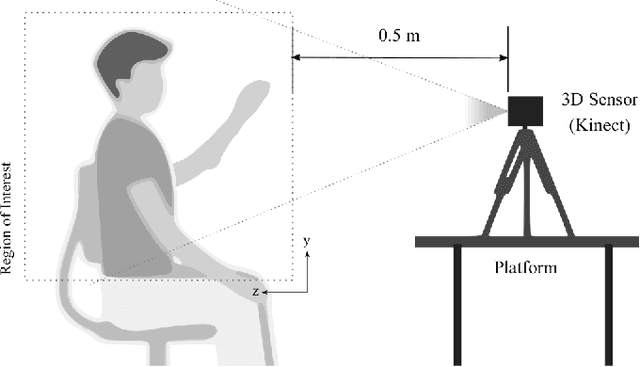
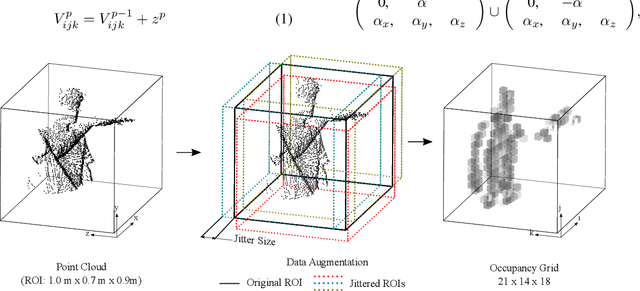
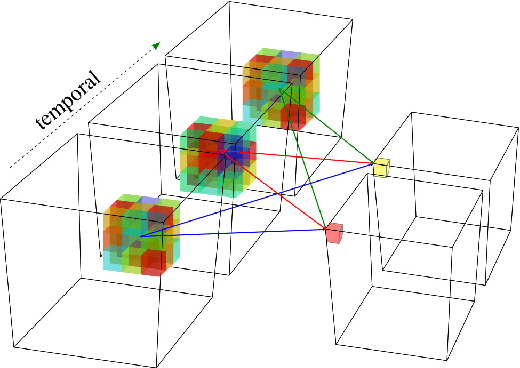
In this paper, we demonstrate an end-to-end spatiotemporal gesture learning approach for 3D point cloud data using a new gestures dataset of point clouds acquired from a 3D sensor. Nine classes of gestures were learned from gestures sample data. We mapped point cloud data into dense occupancy grids, then time steps of the occupancy grids are used as inputs into a 3D convolutional neural network which learns the spatiotemporal features in the data without explicit modeling of gesture dynamics. We also introduced a 3D region of interest jittering approach for point cloud data augmentation. This resulted in an increased classification accuracy of up to 10% when the augmented data is added to the original training data. The developed model is able to classify gestures from the dataset with 84.44% accuracy. We propose that point cloud data will be a more viable data type for scene understanding and motion recognition, as 3D sensors become ubiquitous in years to come.