 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Trainable Soft Retriever for Low-resource Relation Extraction
Jun 06, 2024This study addresses a crucial challenge in instance-based relation extraction using text generation models: end-to-end training in target relation extraction task is not applicable to retrievers due to the non-differentiable nature of instance selection. We propose a novel End-to-end TRAinable Soft K-nearest neighbor retriever (ETRASK) by the neural prompting method that utilizes a soft, differentiable selection of the $k$ nearest instances. This approach enables the end-to-end training of retrievers in target tasks. On the TACRED benchmark dataset with a low-resource setting where the training data was reduced to 10\%, our method achieved a state-of-the-art F1 score of 71.5\%. Moreover, ETRASK consistently improved the baseline model by adding instances for all settings. These results highlight the efficacy of our approach in enhancing relation extraction performance, especially in resource-constrained environments. Our findings offer a promising direction for future research with extraction and the broader application of text generation in natural language processing.
A Neural Edge-Editing Approach for Document-Level Relation Graph Extraction
Jun 18, 2021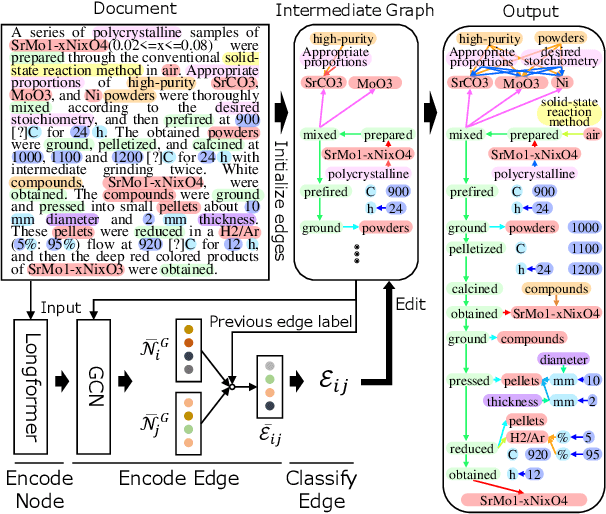
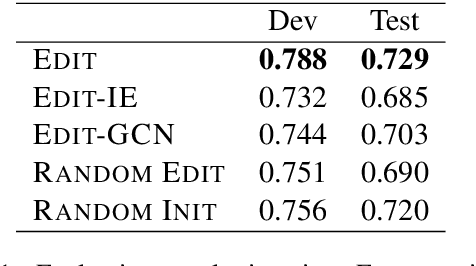
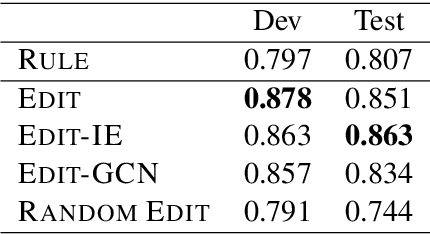
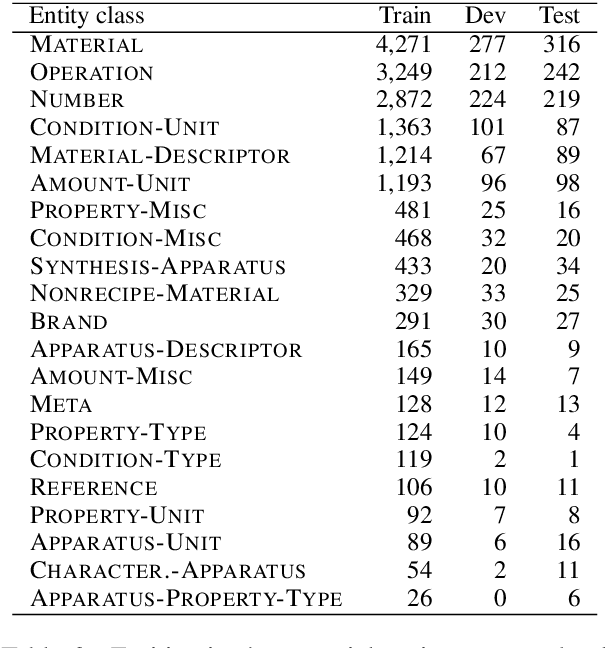
In this paper, we propose a novel edge-editing approach to extract relation information from a document. We treat the relations in a document as a relation graph among entities in this approach. The relation graph is iteratively constructed by editing edges of an initial graph, which might be a graph extracted by another system or an empty graph. The way to edit edges is to classify them in a close-first manner using the document and temporally-constructed graph information; each edge is represented with a document context information by a pretrained transformer model and a graph context information by a graph convolutional neural network model. We evaluate our approach on the task to extract material synthesis procedures from materials science texts. The experimental results show the effectiveness of our approach in editing the graphs initialized by our in-house rule-based system and empty graphs.
Annotating and Extracting Synthesis Process of All-Solid-State Batteries from Scientific Literature
Feb 18, 2020
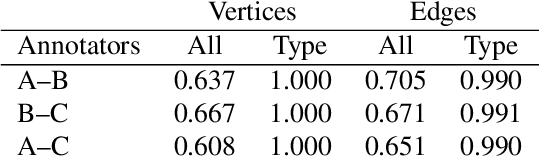
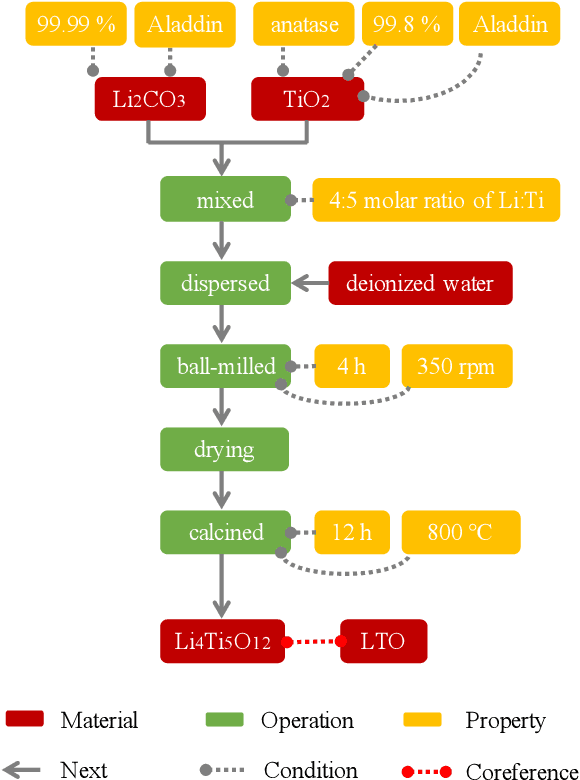

The synthesis process is essential for achieving computational experiment design in the field of inorganic materials chemistry. In this work, we present a novel corpus of the synthesis process for all-solid-state batteries and an automated machine reading system for extracting the synthesis processes buried in the scientific literature. We define the representation of the synthesis processes using flow graphs, and create a corpus from the experimental sections of 243 papers. The automated machine-reading system is developed by a deep learning-based sequence tagger and simple heuristic rule-based relation extractor. Our experimental results demonstrate that the sequence tagger with the optimal setting can detect the entities with a macro-averaged F1 score of 0.826, while the rule-based relation extractor can achieve high performance with a macro-averaged F1 score of 0.887.