 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonolingual versus Multilingual BERTology for Vietnamese Extractive Multi-Document Summarization
Aug 31, 2021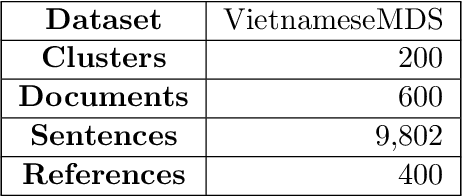
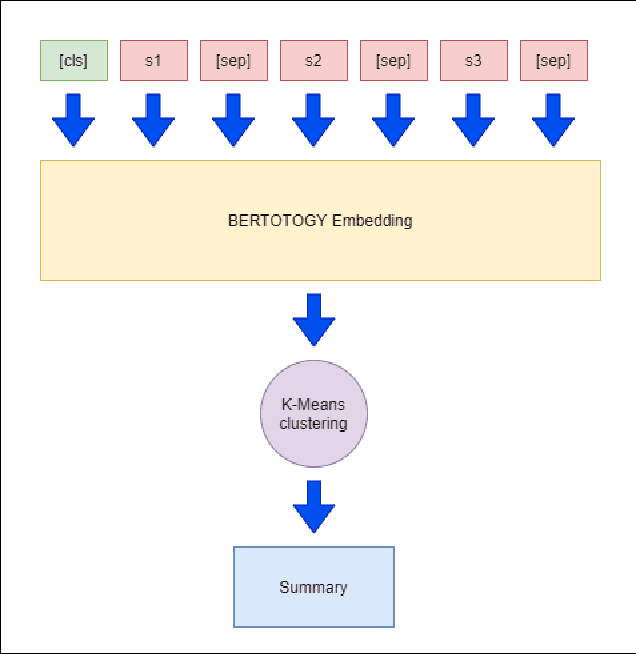
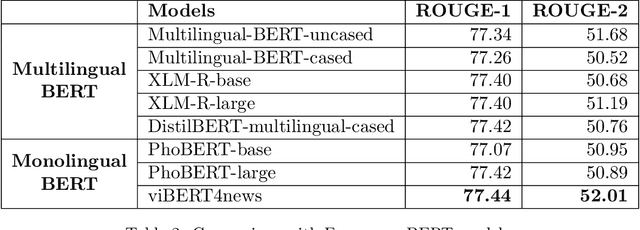
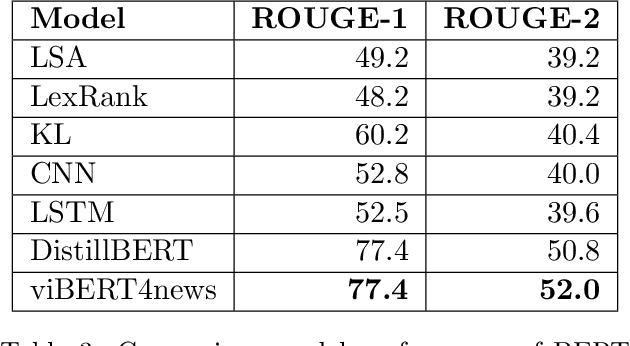
Recent researches have demonstrated that BERT shows potential in a wide range of natural language processing tasks. It is adopted as an encoder for many state-of-the-art automatic summarizing systems, which achieve excellent performance. However, so far, there is not much work done for Vietnamese. In this paper, we showcase how BERT can be implemented for extractive text summarization in Vietnamese. We introduce a novel comparison between different multilingual and monolingual BERT models. The experiment results indicate that monolingual models produce promising results compared to other multilingual models and previous text summarizing models for Vietnamese.
VinaFood21: A Novel Dataset for Evaluating Vietnamese Food Recognition
Aug 06, 2021Vietnam is such an attractive tourist destination with its stunning and pristine landscapes and its top-rated unique food and drink. Among thousands of Vietnamese dishes, foreigners and native people are interested in easy-to-eat tastes and easy-to-do recipes, along with reasonable prices, mouthwatering flavors, and popularity. Due to the diversity and almost all the dishes have significant similarities and the lack of quality Vietnamese food datasets, it is hard to implement an auto system to classify Vietnamese food, therefore, make people easier to discover Vietnamese food. This paper introduces a new Vietnamese food dataset named VinaFood21, which consists of 13,950 images corresponding to 21 dishes. We use 10,044 images for model training and 6,682 test images to classify each food in the VinaFood21 dataset and achieved an average accuracy of 74.81% when fine-tuning CNN EfficientNet-B0. (https://github.com/nguyenvd-uit/uit-together-dataset)
Sentence Extraction-Based Machine Reading Comprehension for Vietnamese
Jun 11, 2021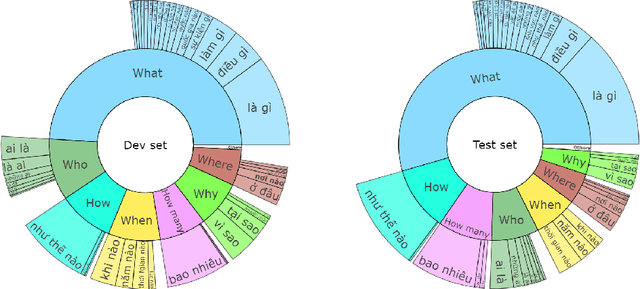
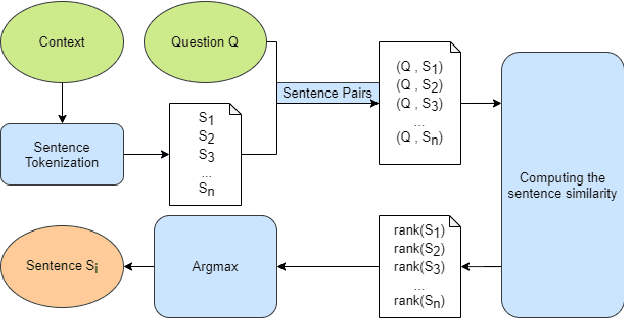
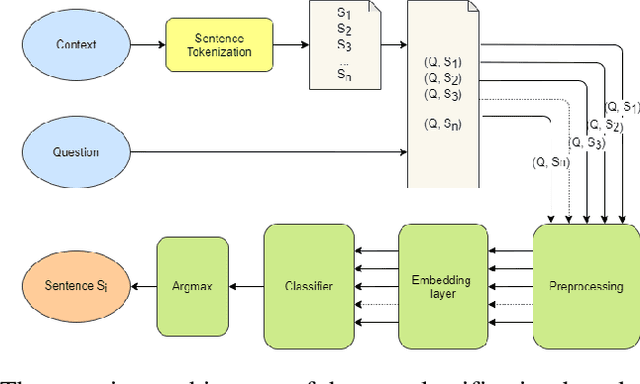
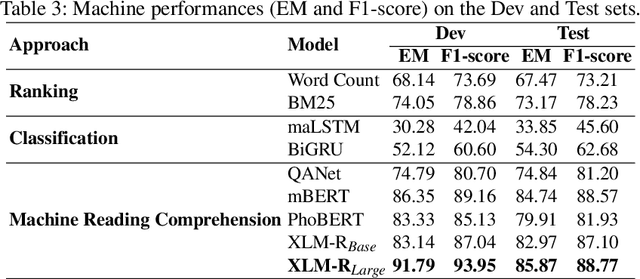
The development of natural language processing (NLP) in general and machine reading comprehension in particular has attracted the great attention of the research community. In recent years, there are a few datasets for machine reading comprehension tasks in Vietnamese with large sizes, such as UIT-ViQuAD and UIT-ViNewsQA. However, the datasets are not diverse in answers to serve the research. In this paper, we introduce UIT-ViWikiQA, the first dataset for evaluating sentence extraction-based machine reading comprehension in the Vietnamese language. The UIT-ViWikiQA dataset is converted from the UIT-ViQuAD dataset, consisting of comprises 23.074 question-answers based on 5.109 passages of 174 Wikipedia Vietnamese articles. We propose a conversion algorithm to create the dataset for sentence extraction-based machine reading comprehension and three types of approaches for sentence extraction-based machine reading comprehension in Vietnamese. Our experiments show that the best machine model is XLM-R_Large, which achieves an exact match (EM) of 85.97% and an F1-score of 88.77% on our dataset. Besides, we analyze experimental results in terms of the question type in Vietnamese and the effect of context on the performance of the MRC models, thereby showing the challenges from the UIT-ViWikiQA dataset that we propose to the language processing community.
SA2SL: From Aspect-Based Sentiment Analysis to Social Listening System for Business Intelligence
Jun 10, 2021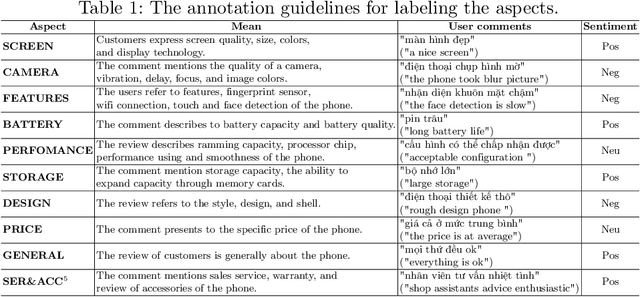
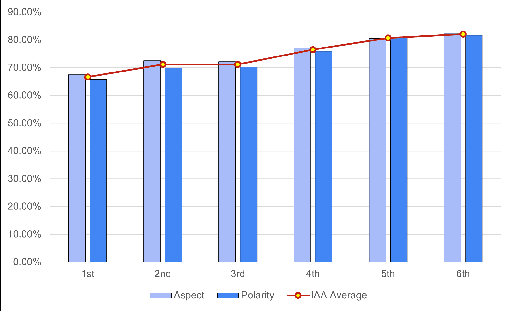
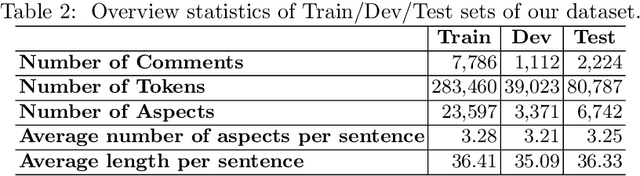
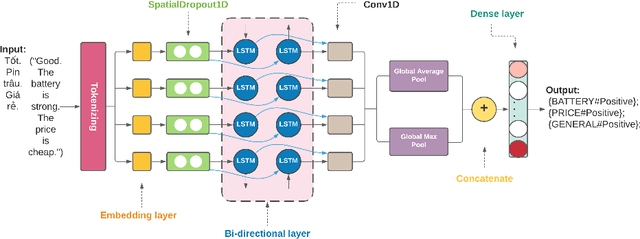
In this paper, we present a process of building a social listening system based on aspect-based sentiment analysis in Vietnamese from creating a dataset to building a real application. Firstly, we create UIT-ViSFD, a Vietnamese Smartphone Feedback Dataset as a new benchmark corpus built based on a strict annotation schemes for evaluating aspect-based sentiment analysis, consisting of 11,122 human-annotated comments for mobile e-commerce, which is freely available for research purposes. We also present a proposed approach based on the Bi-LSTM architecture with the fastText word embeddings for the Vietnamese aspect based sentiment task. Our experiments show that our approach achieves the best performances with the F1-score of 84.48% for the aspect task and 63.06% for the sentiment task, which performs several conventional machine learning and deep learning systems. Last but not least, we build SA2SL, a social listening system based on the best performance model on our dataset, which will inspire more social listening systems in future.
Conversational Machine Reading Comprehension for Vietnamese Healthcare Texts
May 21, 2021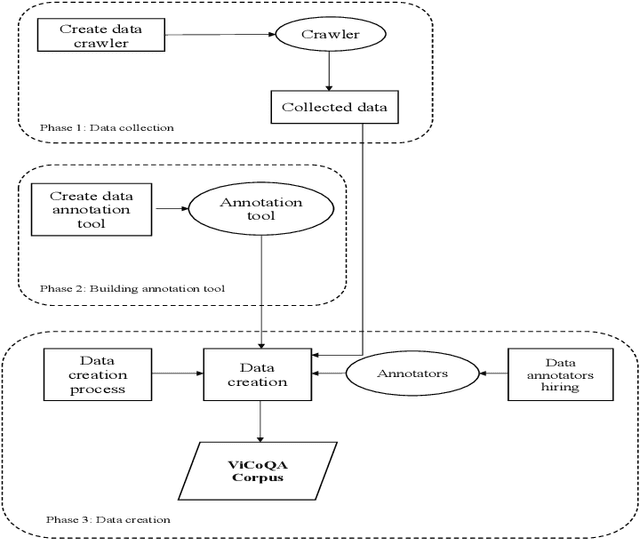
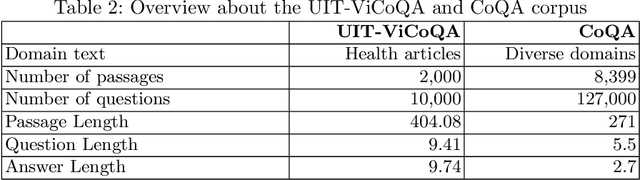
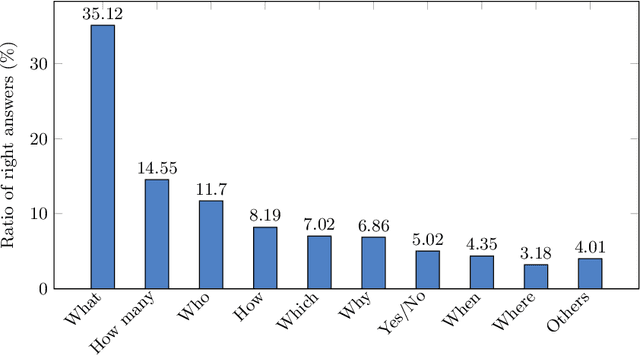

Machine reading comprehension (MRC) is a sub-field in natural language processing that aims to help computers understand unstructured texts and then answer questions related to them. In practice, conversation is an essential way to communicate and transfer information. To help machines understand conversation texts, we present UIT-ViCoQA - a new corpus for conversational machine reading comprehension in the Vietnamese language. This corpus consists of 10,000 questions with answers to over 2,000 conversations about health news articles. Then, we evaluate several baseline approaches for conversational machine comprehension on the UIT-ViCoQA corpus. The best model obtains an F1 score of 45.27%, which is 30.91 points behind human performance (76.18%), indicating that there is ample room for improvement.
Vietnamese Open-domain Complaint Detection in E-Commerce Websites
May 10, 2021
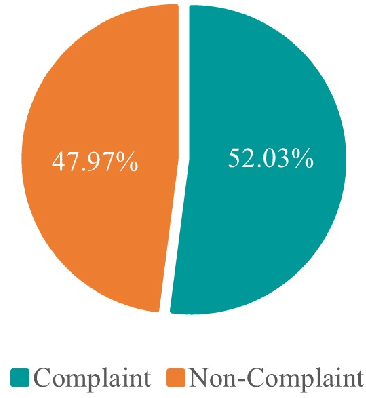
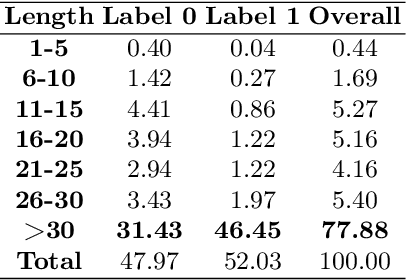
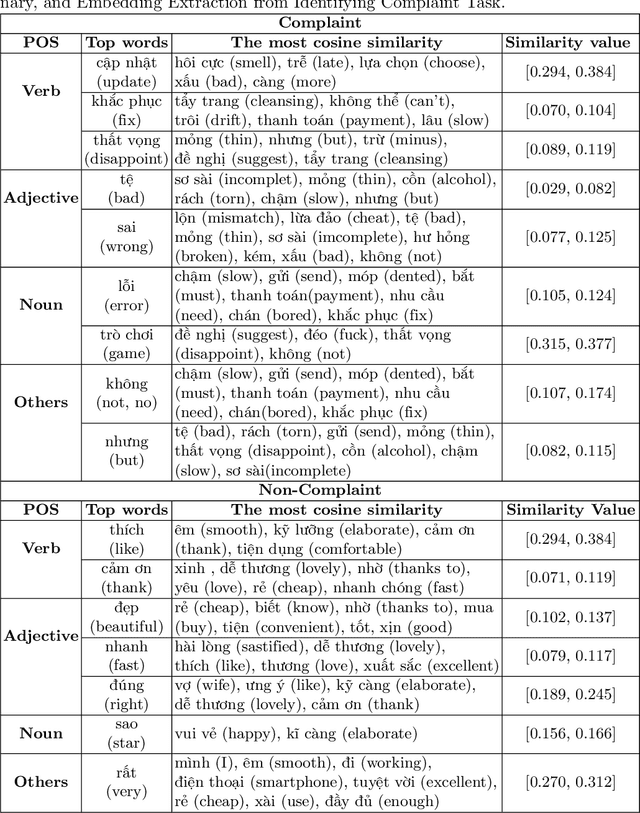
Customer product reviews play a role in improving the quality of products and services for business organizations or their brands. Complaining is an attitude that expresses dissatisfaction with an event or a product not meeting customer expectations. In this paper, we build a Open-domain Complaint Detection dataset (UIT-ViOCD), including 5,485 human-annotated reviews on four categories about product reviews on e-commerce sites. After the data collection phase, we proceed to the annotation task and achieve the inter-annotator agreement Am of 87%. Then, we present an extensive methodology for the research purposes and achieve 92.16% by F1-score for identifying complaints. With the results, in the future, we aim to build a system for open-domain complaint detection in E-commerce websites.
UIT-E10dot3 at SemEval-2021 Task 5: Toxic Spans Detection with Named Entity Recognition and Question-Answering Approaches
Apr 15, 2021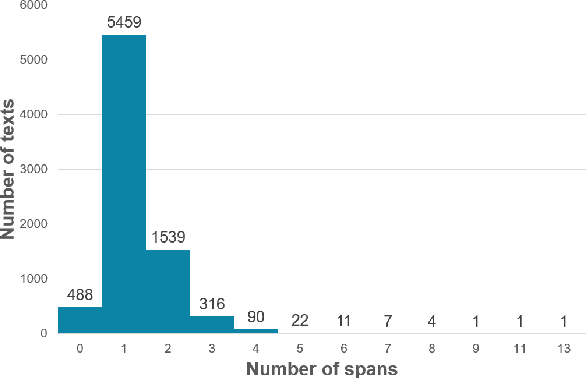

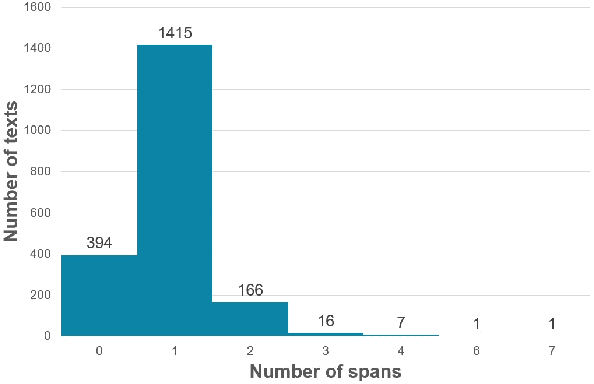

The increment of toxic comments on online space is causing tremendous effects on other vulnerable users. For this reason, considerable efforts are made to deal with this, and SemEval-2021 Task 5: Toxic Spans Detection is one of those. This task asks competitors to extract spans that have toxicity from the given texts, and we have done several analyses to understand its structure before doing experiments. We solve this task by two approaches, Named Entity Recognition with spaCy library and Question-Answering with RoBERTa combining with ToxicBERT, and the former gains the highest F1-score of 66.99%.
A Large-scale Dataset for Hate Speech Detection on Vietnamese Social Media Texts
Apr 05, 2021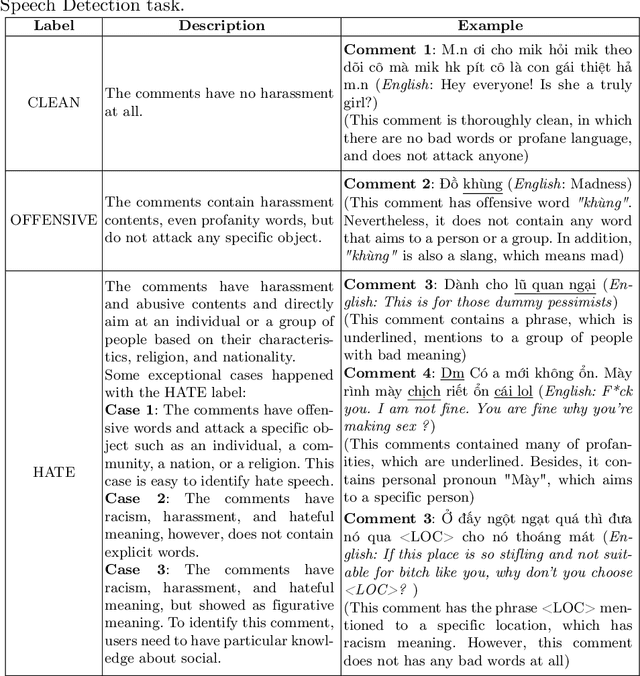
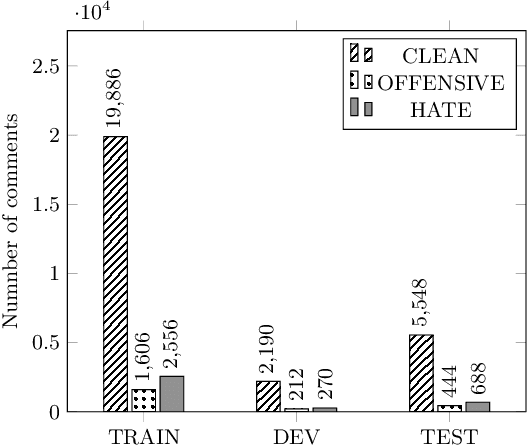

In recent years, Vietnam witnesses the mass development of social network users on different social platforms such as Facebook, Youtube, Instagram, and Tiktok. On social medias, hate speech has become a critical problem for social network users. To solve this problem, we introduce the ViHSD - a human-annotated dataset for automatically detecting hate speech on the social network. This dataset contains over 30,000 comments, each comment in the dataset has one of three labels: CLEAN, OFFENSIVE, or HATE. Besides, we introduce the data creation process for annotating and evaluating the quality of the dataset. Finally, we evaluated the dataset by deep learning models and transformer models.
Constructive and Toxic Speech Detection for Open-domain Social Media Comments in Vietnamese
Mar 24, 2021

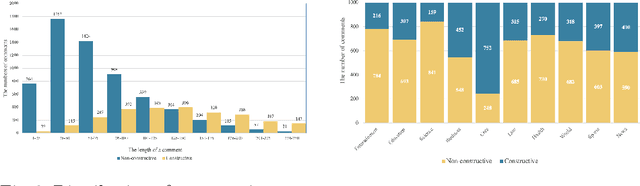

The rise of social media has led to the increasing of comments on online forums. However, there still exists some invalid comments which were not informative for users. Moreover, those comments are also quite toxic and harmful to people. In this paper, we create a dataset for classifying constructive and toxic speech detection, named UIT-ViCTSD (Vietnamese Constructive and Toxic Speech Detection dataset) with 10,000 human-annotated comments. For these tasks, we proposed a system for constructive and toxic speech detection with the state-of-the-art transfer learning model in Vietnamese NLP as PhoBERT. With this system, we achieved 78.59% and 59.40% F1-score for identifying constructive and toxic comments separately. Besides, to have an objective assessment for the dataset, we implement a variety of baseline models as traditional Machine Learning and Deep Neural Network-Based models. With the results, we can solve some problems on the online discussions and develop the framework for identifying constructiveness and toxicity Vietnamese social media comments automatically.
Augmenting Part-of-speech Tagging with Syntactic Information for Vietnamese and Chinese
Feb 24, 2021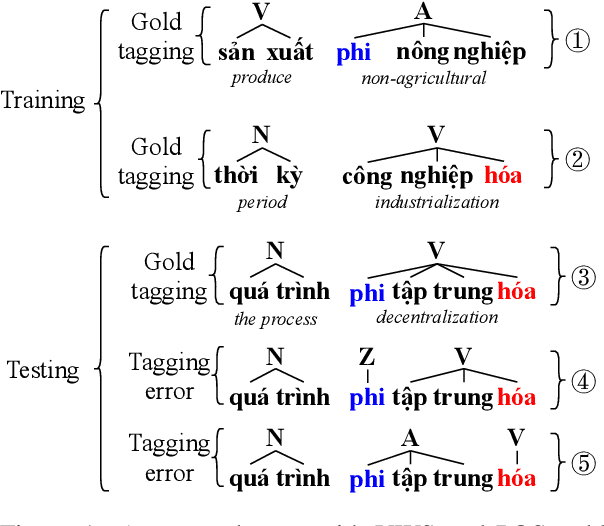
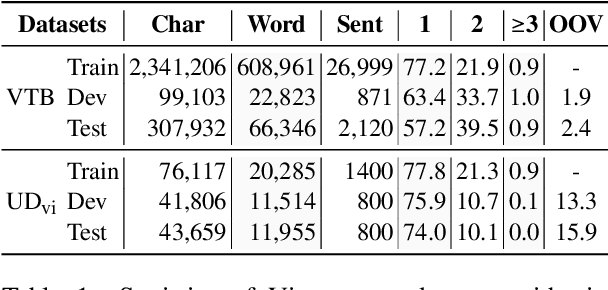
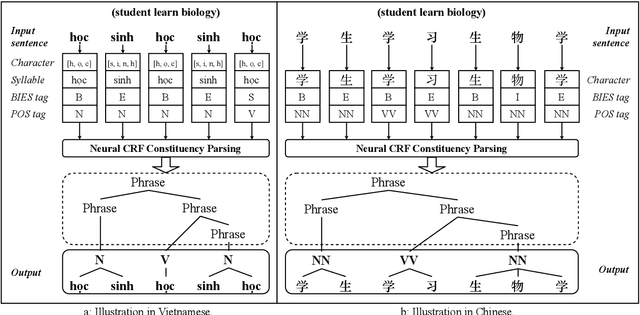
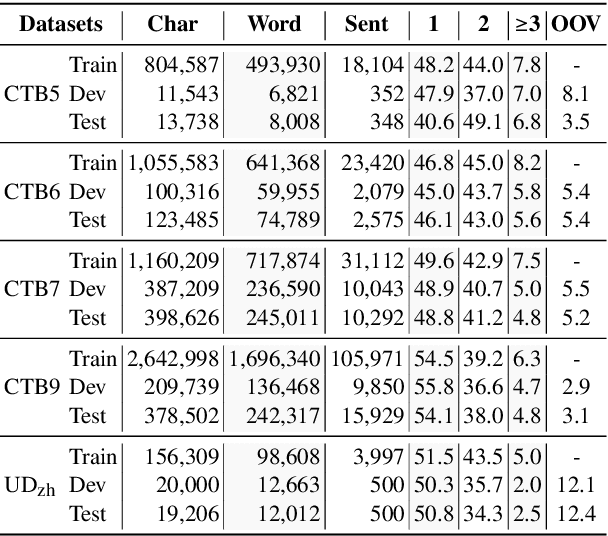
Word segmentation and part-of-speech tagging are two critical preliminary steps for downstream tasks in Vietnamese natural language processing. In reality, people tend to consider also the phrase boundary when performing word segmentation and part of speech tagging rather than solely process word by word from left to right. In this paper, we implement this idea to improve word segmentation and part of speech tagging the Vietnamese language by employing a simplified constituency parser. Our neural model for joint word segmentation and part-of-speech tagging has the architecture of the syllable-based CRF constituency parser. To reduce the complexity of parsing, we replace all constituent labels with a single label indicating for phrases. This model can be augmented with predicted word boundary and part-of-speech tags by other tools. Because Vietnamese and Chinese have some similar linguistic phenomena, we evaluated the proposed model and its augmented versions on three Vietnamese benchmark datasets and six Chinese benchmark datasets. Our experimental results show that the proposed model achieves higher performances than previous works for both languages.