 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExemplars can Reciprocate Principal Components
Apr 07, 2021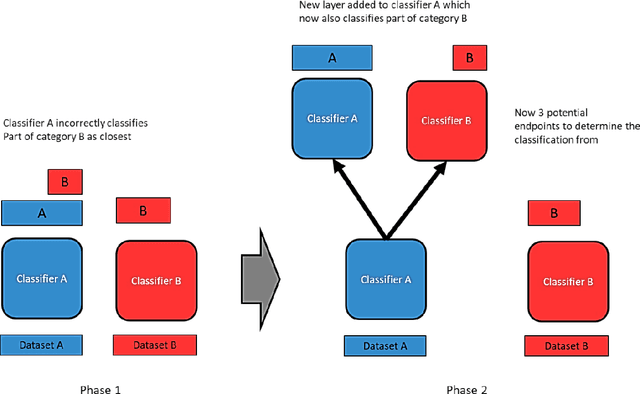
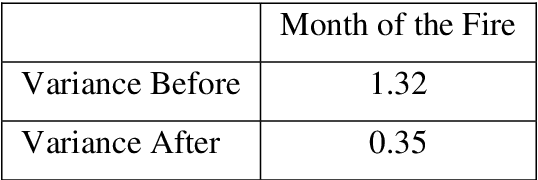

This paper presents a clustering algorithm that is an extension of the Category Trees algorithm. Category Trees is a clustering method that creates tree structures that branch on category type and not feature. The development in this paper is to consider a secondary order of clustering that is not the category to which the data row belongs, but the tree, representing a single classifier, that it is eventually clustered with. Each tree branches to store subsets of other categories, but the rows in those subsets may also be related. This paper is therefore concerned with looking at that second level of clustering between the other category subsets, to try to determine if there is any consistency over it. It is argued that Principal Components may be a related and reciprocal type of structure, and there is an even bigger question about the relation between exemplars and principal components, in general. The theory is demonstrated using the Portugal Forest Fires dataset as a case study. The Category Trees are then combined with other Self-Organising algorithms from the author and it is suggested that they all belong to the same family type, which is an Entropy-style of classifier.
New Ideas for Brain Modelling 7
Nov 04, 2020
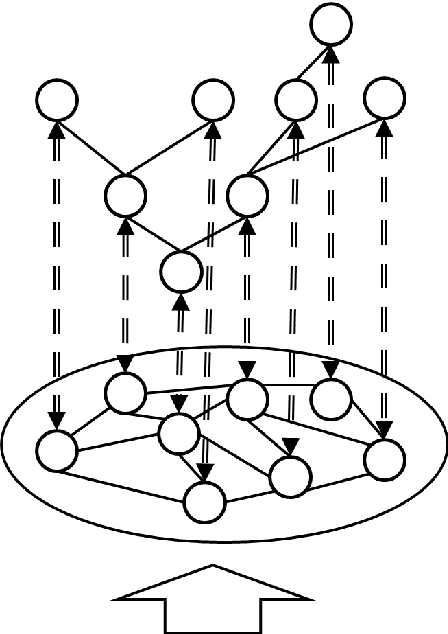
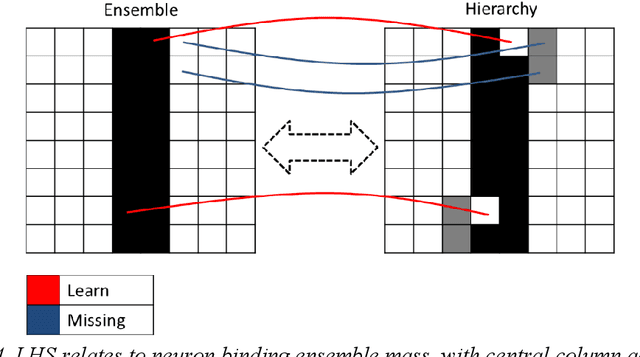
This paper further integrates the cognitive model, making it mathematically similar. The theory is that if the model stores information which can be transposed in consistent ways, then that will result in knowledge and some level of intelligence. The main constraints are time and the conservation of energy, but the information transpositions are also very limited. As part of the design, patterns have to become distinct and that is realised by unique paths through the neural structures. The design may now also define uniqueness through the pattern result and not just its links. The earlier designs are still consistent. The between-level boundaries have been moved slightly, but the functionality remains the same, with aggregations and increasing complexity through the layers. The two main models differ in their upper level only. One provides a propositional logic for mutually inclusive or exclusive pattern groups and sequences, while the other provides a behaviour script that is constructed from node types. It can be seen that these two views are complimentary and would allow some control over the behaviour that might get selected.
An Entropy Equation for Energy
Jul 07, 2020This paper describes an entropy equation, but one that should be used for measuring energy and not information. In relation to the human brain therefore, both of these quantities can be used to represent the stored information. The human brain makes use of energy efficiency to form its structures, which is likely to be linked to the neuron wiring. This energy efficiency can also be used as the basis for a clustering algorithm, which is described in a different paper. This paper is more of a discussion about global properties, where the rules used for the clustering algorithm can also create the entropy equation E = (mean * variance). This states that work is done through the energy released by the 'change' in entropy. The equation is so simplistic and generic that it can offer arguments for completely different domains, where the journey ends with a discussion about global energy properties in physics and beyond. A comparison with Einstein's relativity equation is made and also the audacious suggestion that a black hole has zero-energy inside.
New Ideas for Brain Modelling 6
May 11, 2020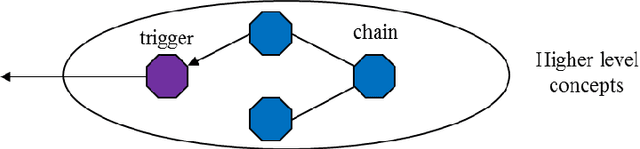

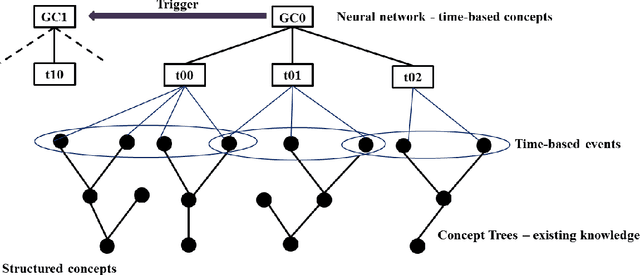

This paper describes implementation details for a 3-level cognitive model, described in the paper series. The whole architecture is now modular, with different levels using different types of information. The ensemble-hierarchy relationship is maintained and placed in the bottom optimising and middle aggregating levels, to store memory objects and their relations. The top-level cognitive layer has been re-designed to model the Cognitive Process Language (CPL) of an earlier paper, by refactoring it into a network structure with a light scheduler. The cortex brain region is thought to be hierarchical - clustering from simple to more complex features. The refactored network might therefore challenge conventional thinking on that brain region. It is also argued that the function and structure in particular, of the new top level, is similar to the psychology theory of chunking. The model is still only a framework and does not have enough information for real intelligence. But a framework is now implemented over the whole design and so can give a more complete picture about the potential for results.
How the Brain might use Division
Mar 24, 2020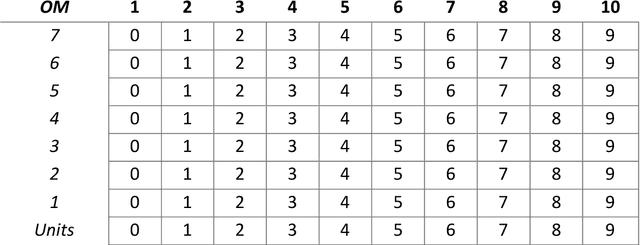
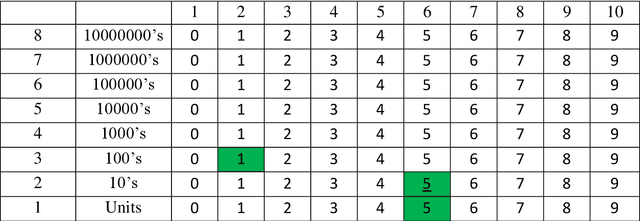
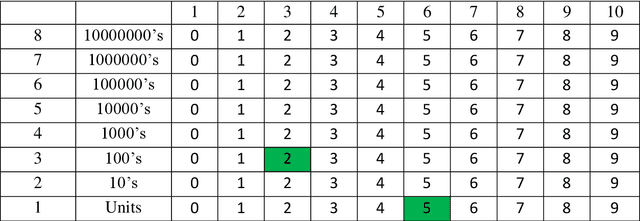
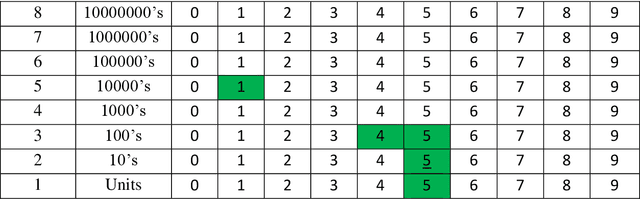
One of the most fundamental questions in Biology or Artificial Intelligence is how the human brain performs mathematical functions. How does a neural architecture that may organise itself mostly through statistics, know what to do? One possibility is to extract the problem to something more abstract. This becomes clear when thinking about how the brain handles large numbers, for example to the power of something, when simply summing to an answer is not feasible. In this paper, the author suggests that the maths question can be answered more easily if the problem is changed into one of symbol manipulation and not just number counting. If symbols can be compared and manipulated, maybe without understanding completely what they are, then the mathematical operations become relative and some of them might even be rote learned. The proposed system may also be suggested as an alternative to the traditional computer binary system. Any of the actual maths still breaks down into binary operations, while a more symbolic level above that can manipulate the numbers and reduce the problem size, thus making the binary operations simpler. An interesting result of looking at this is the possibility of a new fractal equation resulting from division, that can be used as a measure of good fit and would help the brain decide how to solve something through self-replacement and a comparison with this good fit.
Image Recognition using Region Creep
Sep 24, 2019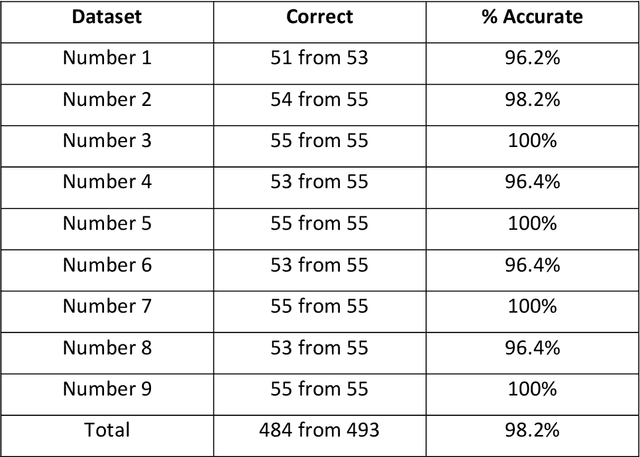

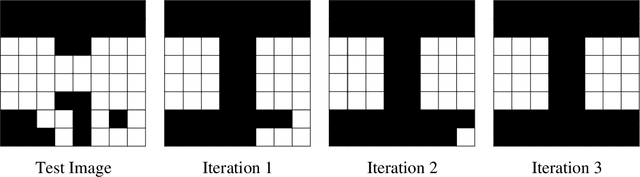
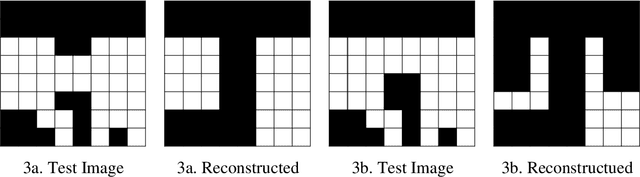
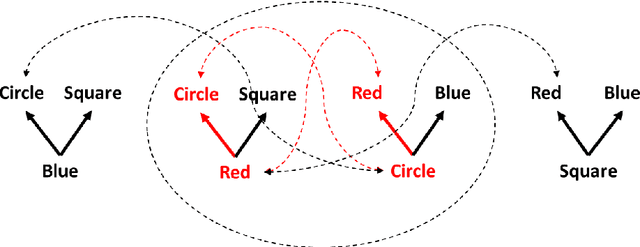
This paper describes a new type of image classifier that uses a shallow architecture with a very quick learning phase. The image is parsed into smaller areas and each area is saved directly for a region, along with the related output category. When a new image is presented, a direct match with each part is made and the best matching areas returned. These areas can overlap with each other and when moving from a region to its neighbours, there is likely to be only small changes in the area image part. It would therefore be possible to guess what the best image part is for one region by cumulating the results of its neighbours. This is in fact an associative feature of the classifier that can re-construct missing or noisy input by substituting the direct match with what the region match suggests and is being called 'Region Creep'. As each area stores the categories it belongs to, the image classification process sums this to return a preferred category for the whole image. The classifier works mostly at a local level and so to give it some type of global picture, rules are added. These rules work at the whole image level and basically state that if one set of pixels are present, another set should be removed or should also be present. While the rules appear to be very specific, most of the construction can be done automatically. Tests on a set of hand-written numbers have produced state-of-the-art results.
A Pattern-Hierarchy Classifier for Reduced Teaching
Apr 16, 2019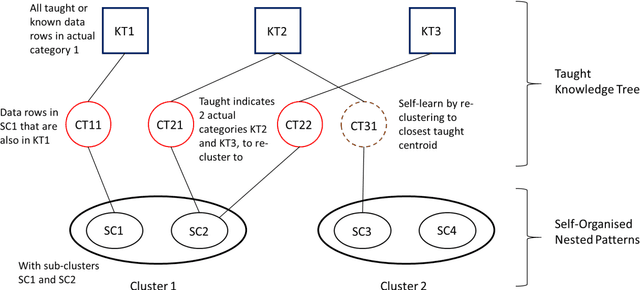
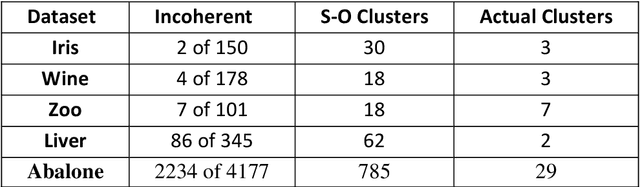
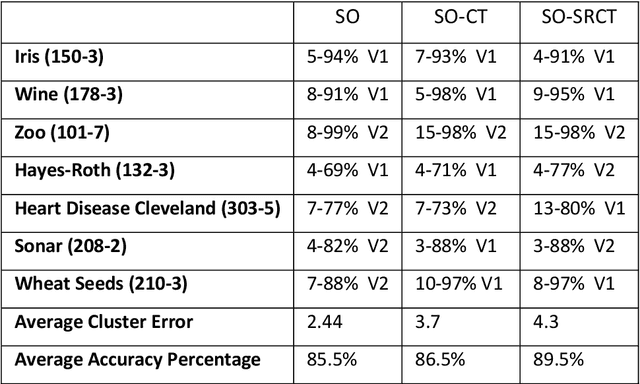
This paper uses a branching classifier mechanism in an unsupervised scenario, to enable it to self-organise data into unknown categories. A teaching phase is then able to help the classifier to learn the true category for each input row, using a reduced number of training steps. The pattern ensembles are learned in an unsupervsised manner that use a closest-distance clustering. This is done without knowing what the actual output category is and leads to each actual category having several clusters associated with it. One measure of success is then that each of these sub-clusters is coherent, which means that every data row in the cluster belongs to the same category. The total number of clusters is also important and a teaching phase can then teach the classifier what the correct actual category is. During this phase, any classifier can also learn or infer correct classifications from some other classifier's knowledge, thereby reducing the required number of presentations. As the information is added, cross-referencing between the two structures allows it to be used more widely. With this process, a unique structure can build up that would not be possible by either method separately. The lower level is a nested ensemble of patterns created by self-organisation. The upper level is a hierarchical tree, where each end node represents a single category only, so there is a transition from mixed ensemble masses to specific categories. The structure also has relations to brain-like modelling.
A Feature-Value Network as a Brain Model
Apr 09, 2019This paper suggests a statistical framework for describing the relations between the physical and conceptual entities of a brain-like model. In particular, features and concept instances are put into context. This may help with understanding or implementing a similar model. The paper suggests that features are in fact the wiring. With this idea, the actual length of the connection is important, because it is related to neuron synchronization. The paper then suggests that the concepts are neuron-based and firing neurons are concept instances. Therefore, features become the static framework of the interconnected neural system and concepts are combinations of these, as determined by an external stimulus and the neural associations. Along with this statistical model, it is possible to propose a simplified design for the neuron itself, but based on the idea that it can vary its input and output signals. Some test results also help to support the theory.
An Experiment with Bands and Dimensions in Classifiers
Nov 06, 2018
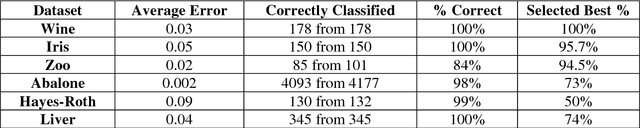


This paper presents a new version of an oscillating error classifier that has added fixed value ranges through bands, for each column or feature of the input dataset. It is shown that some of the data can be correctly classified through using fixed value ranges only, while the rest can be classified by using the classifier technique. It also presents the classifier in terms of a biological model of neurons and neuron links.
New Ideas for Brain Modelling 3
Sep 17, 2018This paper considers a process for the creation and subsequent firing of sequences of neuronal patterns, as might be found in the human brain. The scale is one of larger patterns emerging from an ensemble mass, possibly through some type of energy equation and a reduction procedure. The links between the patterns can be formed naturally, as a residual effect of the pattern creation itself. This paper follows-on closely from the earlier research, including two earlier papers in the series and uses the ideas of entropy and cohesion. With a small addition, it is possible to show how the inter-pattern links can be determined. A compact Grid form of an earlier Counting Mechanism is also demonstrated and may be a new clustering technique. It is possible to explain how a very basic repeating structure can form the arbitrary patterns and activation sequences between them, and a key question of how nodes synchronise may even be answerable.