 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Real-time Audio-Visual Speech Enhancement
Dec 16, 2021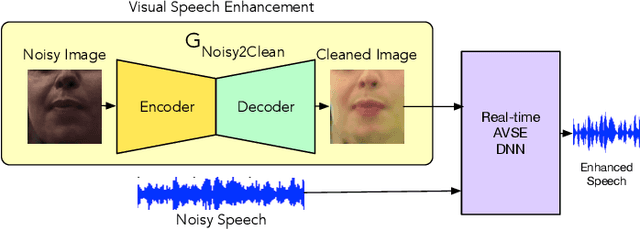
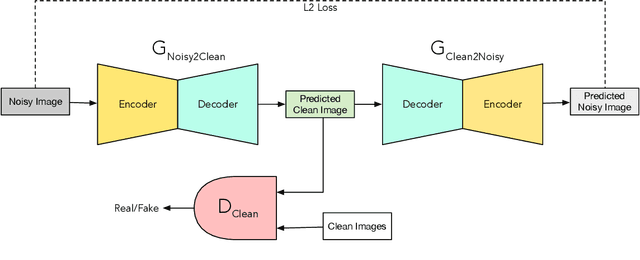

The human brain contextually exploits heterogeneous sensory information to efficiently perform cognitive tasks including vision and hearing. For example, during the cocktail party situation, the human auditory cortex contextually integrates audio-visual (AV) cues in order to better perceive speech. Recent studies have shown that AV speech enhancement (SE) models can significantly improve speech quality and intelligibility in very low signal to noise ratio (SNR) environments as compared to audio-only SE models. However, despite significant research in the area of AV SE, development of real-time processing models with low latency remains a formidable technical challenge. In this paper, we present a novel framework for low latency speaker-independent AV SE that can generalise on a range of visual and acoustic noises. In particular, a generative adversarial networks (GAN) is proposed to address the practical issue of visual imperfections in AV SE. In addition, we propose a deep neural network based real-time AV SE model that takes into account the cleaned visual speech output from GAN to deliver more robust SE. The proposed framework is evaluated on synthetic and real noisy AV corpora using objective speech quality and intelligibility metrics and subjective listing tests. Comparative simulation results show that our real time AV SE framework outperforms state-of-the-art SE approaches, including recent DNN based SE models.
Towards Intelligibility-Oriented Audio-Visual Speech Enhancement
Nov 18, 2021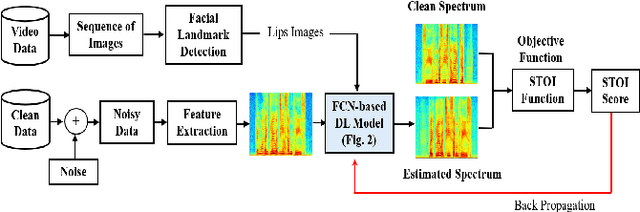
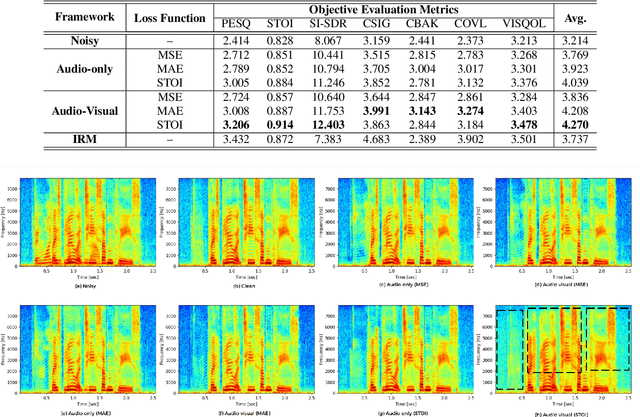
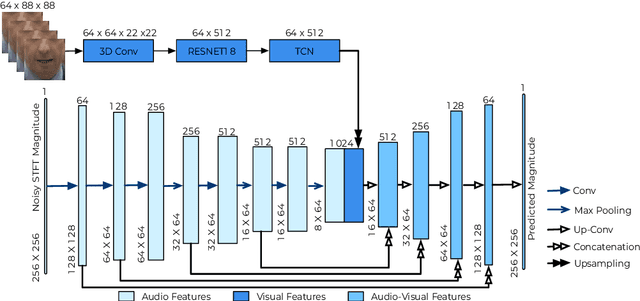
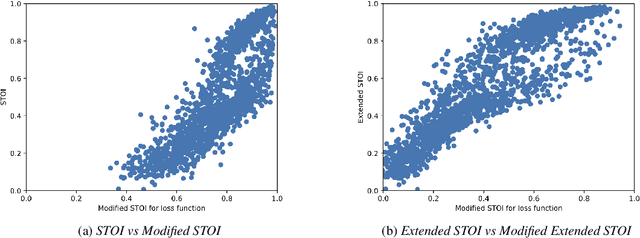
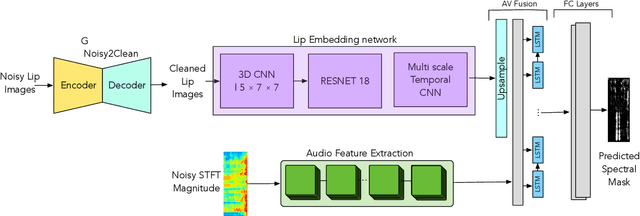
Existing deep learning (DL) based speech enhancement approaches are generally optimised to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in real noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions and integration of audio-visual (AV) information for more robust speech enhancement (SE). In this paper, we introduce DL based I-O SE algorithms exploiting AV information, which is a novel and previously unexplored research direction. Specifically, we present a fully convolutional AV SE model that uses a modified short-time objective intelligibility (STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of AV modalities with an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed I-O AV SE framework outperforms audio-only (AO) and AV models trained with conventional distance-based loss functions, in terms of standard objective evaluation measures when dealing with unseen speakers and noises.
A Novel Context-Aware Multimodal Framework for Persian Sentiment Analysis
Mar 03, 2021
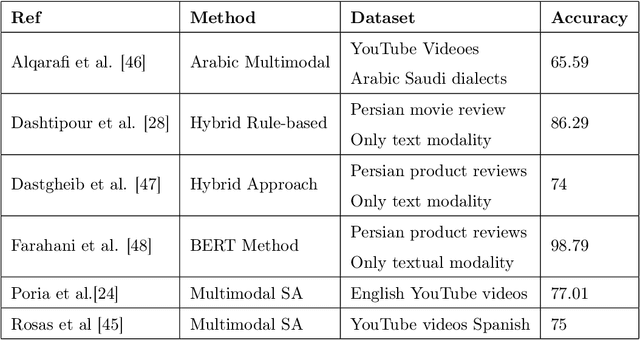
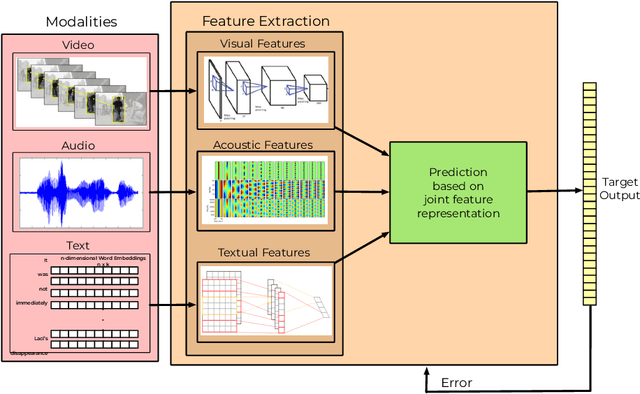
Most recent works on sentiment analysis have exploited the text modality. However, millions of hours of video recordings posted on social media platforms everyday hold vital unstructured information that can be exploited to more effectively gauge public perception. Multimodal sentiment analysis offers an innovative solution to computationally understand and harvest sentiments from videos by contextually exploiting audio, visual and textual cues. In this paper, we, firstly, present a first of its kind Persian multimodal dataset comprising more than 800 utterances, as a benchmark resource for researchers to evaluate multimodal sentiment analysis approaches in Persian language. Secondly, we present a novel context-aware multimodal sentiment analysis framework, that simultaneously exploits acoustic, visual and textual cues to more accurately determine the expressed sentiment. We employ both decision-level (late) and feature-level (early) fusion methods to integrate affective cross-modal information. Experimental results demonstrate that the contextual integration of multimodal features such as textual, acoustic and visual features deliver better performance (91.39%) compared to unimodal features (89.24%).
AV Speech Enhancement Challenge using a Real Noisy Corpus
Sep 30, 2019

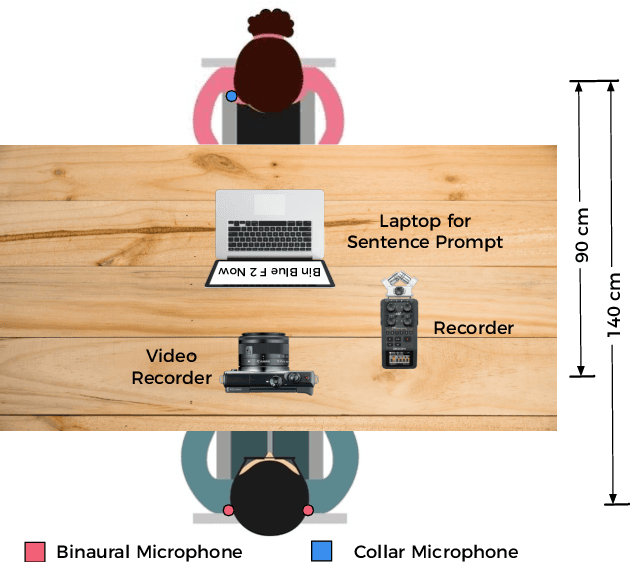
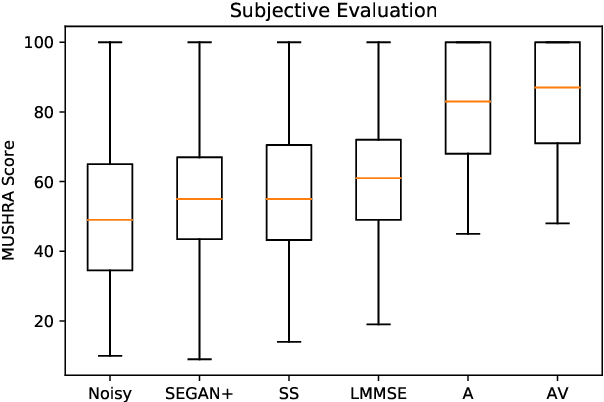
This paper presents, a first of its kind, audio-visual (AV) speech enhacement challenge in real-noisy settings. A detailed description of the AV challenge, a novel real noisy AV corpus (ASPIRE), benchmark speech enhancement task, and baseline performance results are outlined. The latter are based on training a deep neural architecture on a synthetic mixture of Grid corpus and ChiME3 noises (consisting of bus, pedestrian, cafe, and street noises) and testing on the ASPIRE corpus. Subjective evaluations of five different speech enhancement algorithms (including SEAGN, spectrum subtraction (SS) , log-minimum mean-square error (LMMSE), audio-only CochleaNet, and AV CochleaNet) are presented as baseline results. The aim of the multi-modal challenge is to provide a timely opportunity for comprehensive evaluation of novel AV speech enhancement algorithms, using our new benchmark, real-noisy AV corpus and specified performance metrics. This will promote AV speech processing research globally, stimulate new ground-breaking multi-modal approaches, and attract interest from companies, academics and researchers working in AV speech technologies and applications. We encourage participants (through a challenge website sign-up) from both the speech and hearing research communities, to benefit from their complementary approaches to AV speech in noise processing.
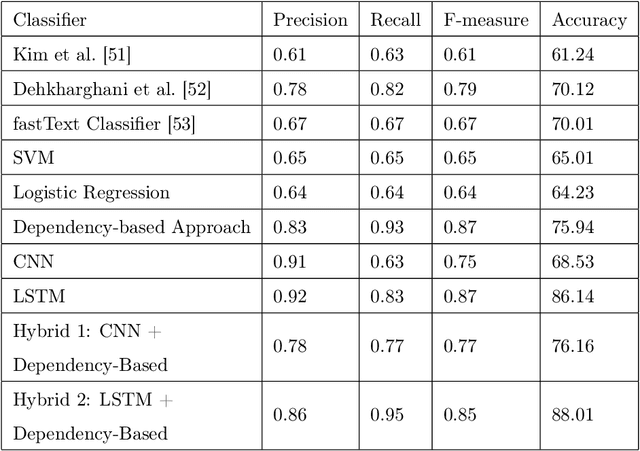
A Hybrid Persian Sentiment Analysis Framework: Integrating Dependency Grammar Based Rules and Deep Neural Networks
Sep 30, 2019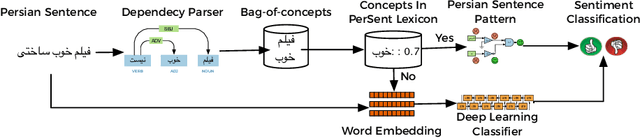

Social media hold valuable, vast and unstructured information on public opinion that can be utilized to improve products and services. The automatic analysis of such data, however, requires a deep understanding of natural language. Current sentiment analysis approaches are mainly based on word co-occurrence frequencies, which are inadequate in most practical cases. In this work, we propose a novel hybrid framework for concept-level sentiment analysis in Persian language, that integrates linguistic rules and deep learning to optimize polarity detection. When a pattern is triggered, the framework allows sentiments to flow from words to concepts based on symbolic dependency relations. When no pattern is triggered, the framework switches to its subsymbolic counterpart and leverages deep neural networks (DNN) to perform the classification. The proposed framework outperforms state-of-the-art approaches (including support vector machine, and logistic regression) and DNN classifiers (long short-term memory, and Convolutional Neural Networks) with a margin of 10-15% and 3-4% respectively, using benchmark Persian product and hotel reviews corpora.
CochleaNet: A Robust Language-independent Audio-Visual Model for Speech Enhancement
Sep 23, 2019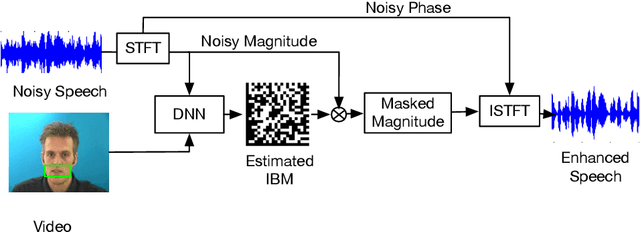
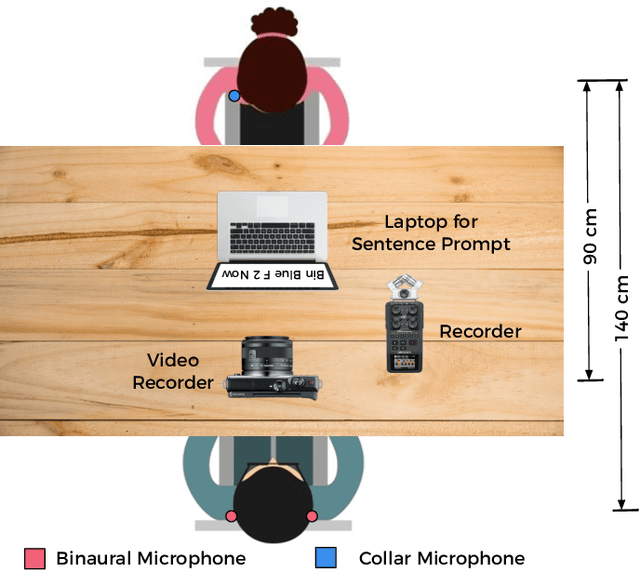
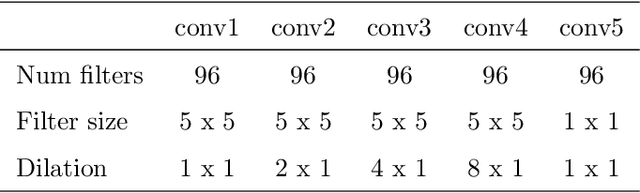
Noisy situations cause huge problems for suffers of hearing loss as hearing aids often make the signal more audible but do not always restore the intelligibility. In noisy settings, humans routinely exploit the audio-visual (AV) nature of the speech to selectively suppress the background noise and to focus on the target speaker. In this paper, we present a causal, language, noise and speaker independent AV deep neural network (DNN) architecture for speech enhancement (SE). The model exploits the noisy acoustic cues and noise robust visual cues to focus on the desired speaker and improve the speech intelligibility. To evaluate the proposed SE framework a first of its kind AV binaural speech corpus, called ASPIRE, is recorded in real noisy environments including cafeteria and restaurant. We demonstrate superior performance of our approach in terms of objective measures and subjective listening tests over the state-of-the-art SE approaches as well as recent DNN based SE models. In addition, our work challenges a popular belief that a scarcity of multi-language large vocabulary AV corpus and wide variety of noises is a major bottleneck to build a robust language, speaker and noise independent SE systems. We show that a model trained on synthetic mixture of Grid corpus (with 33 speakers and a small English vocabulary) and ChiME 3 Noises (consisting of only bus, pedestrian, cafeteria, and street noises) generalise well not only on large vocabulary corpora but also on completely unrelated languages (such as Mandarin), wide variety of speakers and noises.
Exploiting Deep Learning for Persian Sentiment Analysis
Aug 15, 2018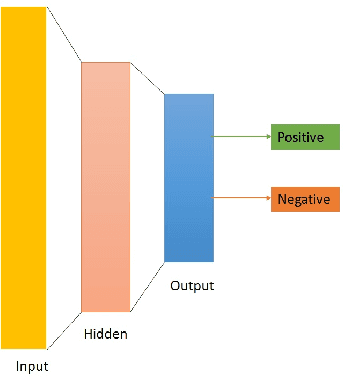
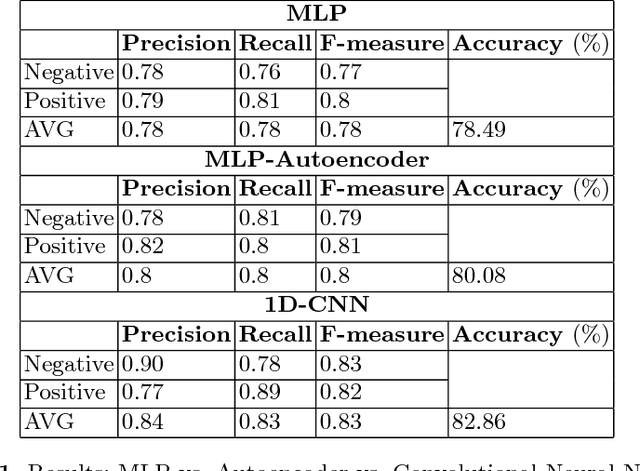
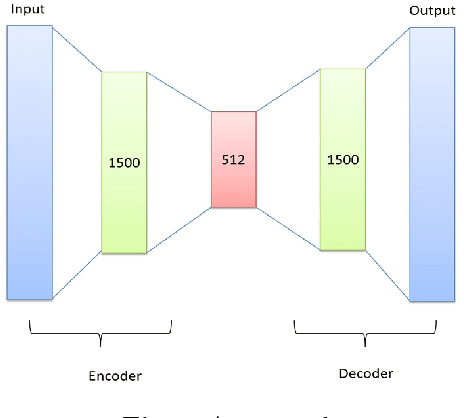
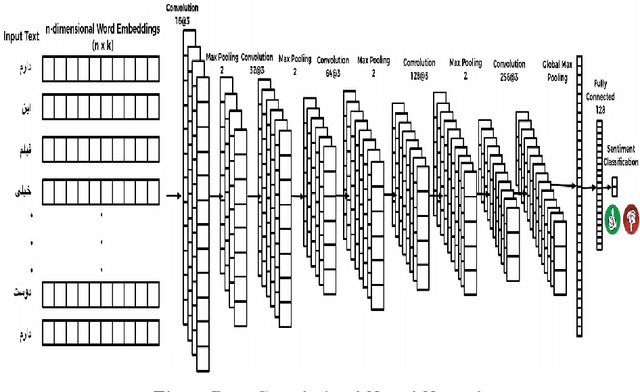
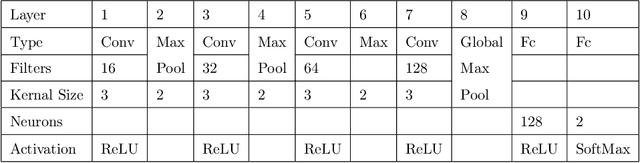
The rise of social media is enabling people to freely express their opinions about products and services. The aim of sentiment analysis is to automatically determine subject's sentiment (e.g., positive, negative, or neutral) towards a particular aspect such as topic, product, movie, news etc. Deep learning has recently emerged as a powerful machine learning technique to tackle a growing demand of accurate sentiment analysis. However, limited work has been conducted to apply deep learning algorithms to languages other than English, such as Persian. In this work, two deep learning models (deep autoencoders and deep convolutional neural networks (CNNs)) are developed and applied to a novel Persian movie reviews dataset. The proposed deep learning models are analyzed and compared with the state-of-the-art shallow multilayer perceptron (MLP) based machine learning model. Simulation results demonstrate the enhanced performance of deep learning over state-of-the-art MLP.