 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Adversarial Networks
Jul 09, 2017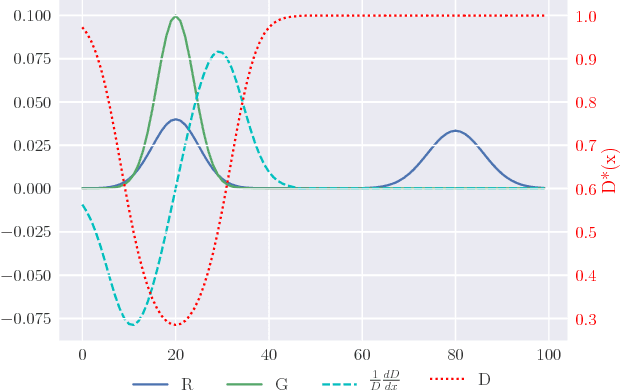
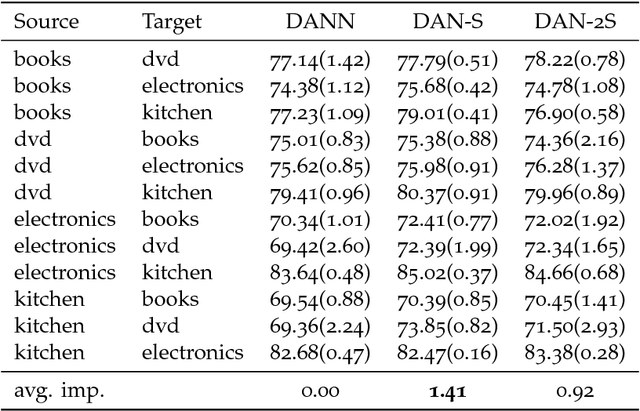
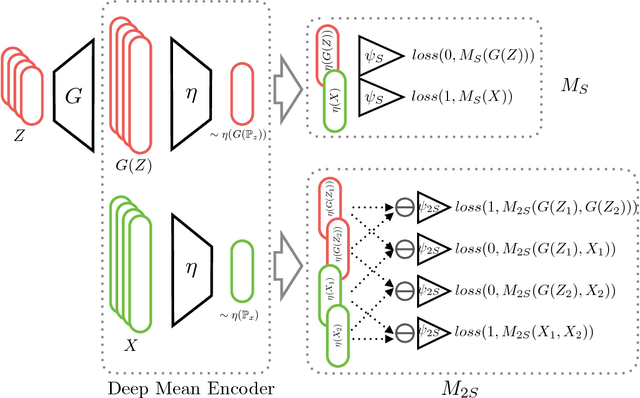

We propose a framework for adversarial training that relies on a sample rather than a single sample point as the fundamental unit of discrimination. Inspired by discrepancy measures and two-sample tests between probability distributions, we propose two such distributional adversaries that operate and predict on samples, and show how they can be easily implemented on top of existing models. Various experimental results show that generators trained with our distributional adversaries are much more stable and are remarkably less prone to mode collapse than traditional models trained with pointwise prediction discriminators. The application of our framework to domain adaptation also results in considerable improvement over recent state-of-the-art.