 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Continual Learning in a Unified Visual Environment
Dec 12, 2017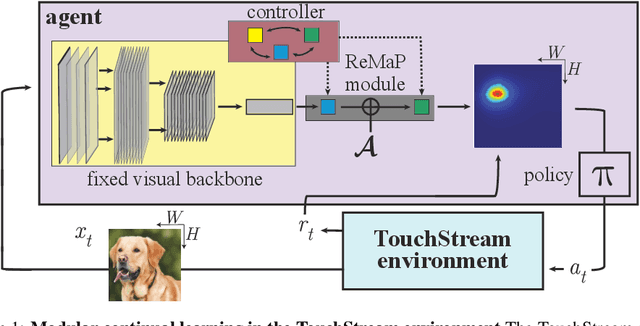

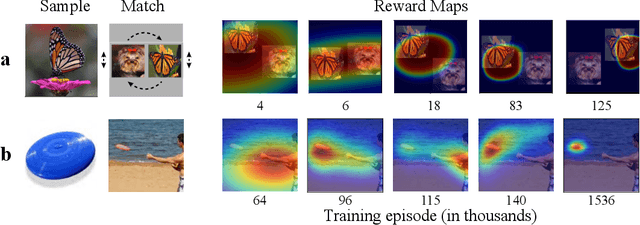
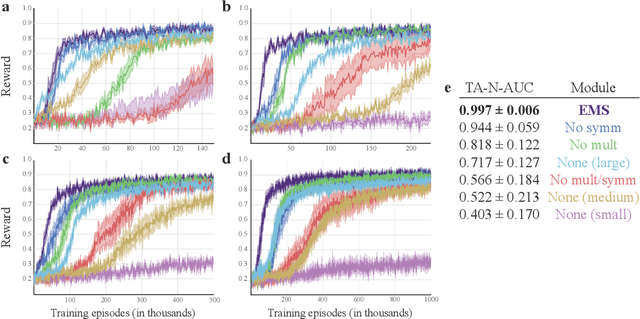
A core aspect of human intelligence is the ability to learn new tasks quickly and switch between them flexibly. Here, we describe a modular continual reinforcement learning paradigm inspired by these abilities. We first introduce a visual interaction environment that allows many types of tasks to be unified in a single framework. We then describe a reward map prediction scheme that learns new tasks robustly in the very large state and action spaces required by such an environment. We investigate how properties of module architecture influence efficiency of task learning, showing that a module motif incorporating specific design principles (e.g. early bottlenecks, low-order polynomial nonlinearities, and symmetry) significantly outperforms more standard neural network motifs, needing fewer training examples and fewer neurons to achieve high levels of performance. Finally, we present a meta-controller architecture for task switching based on a dynamic neural voting scheme, which allows new modules to use information learned from previously-seen tasks to substantially improve their own learning efficiency.
A Useful Motif for Flexible Task Learning in an Embodied Two-Dimensional Visual Environment
Jun 22, 2017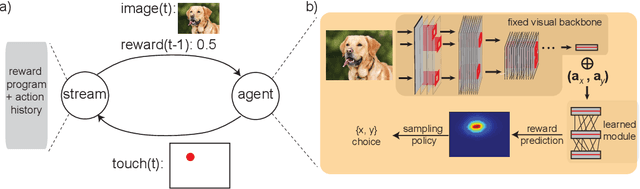
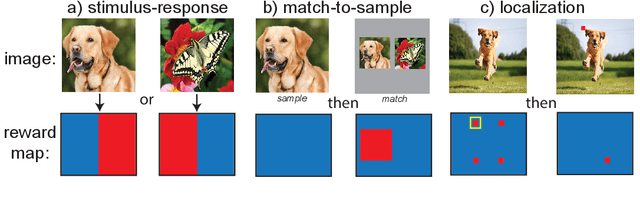
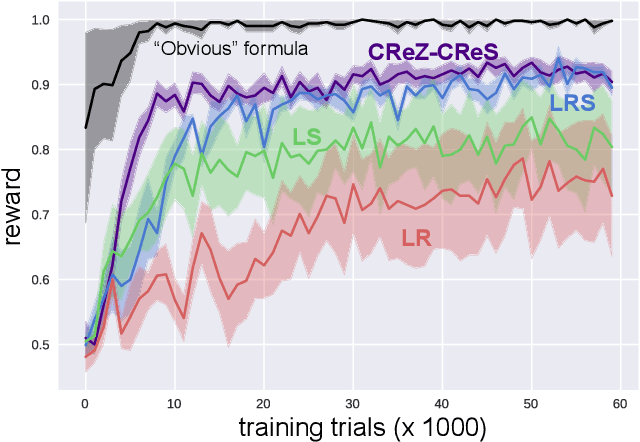
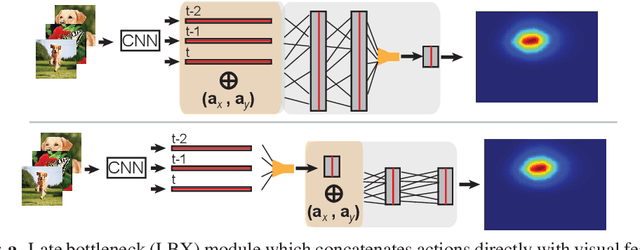
Animals (especially humans) have an amazing ability to learn new tasks quickly, and switch between them flexibly. How brains support this ability is largely unknown, both neuroscientifically and algorithmically. One reasonable supposition is that modules drawing on an underlying general-purpose sensory representation are dynamically allocated on a per-task basis. Recent results from neuroscience and artificial intelligence suggest the role of the general purpose visual representation may be played by a deep convolutional neural network, and give some clues how task modules based on such a representation might be discovered and constructed. In this work, we investigate module architectures in an embodied two-dimensional touchscreen environment, in which an agent's learning must occur via interactions with an environment that emits images and rewards, and accepts touches as input. This environment is designed to capture the physical structure of the task environments that are commonly deployed in visual neuroscience and psychophysics. We show that in this context, very simple changes in the nonlinear activations used by such a module can significantly influence how fast it is at learning visual tasks and how suitable it is for switching to new tasks.