 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to be Reproducible: Custom Loss Design for Robust Neural Networks
Jan 02, 2026To enhance the reproducibility and reliability of deep learning models, we address a critical gap in current training methodologies: the lack of mechanisms that ensure consistent and robust performance across runs. Our empirical analysis reveals that even under controlled initialization and training conditions, the accuracy of the model can exhibit significant variability. To address this issue, we propose a Custom Loss Function (CLF) that reduces the sensitivity of training outcomes to stochastic factors such as weight initialization and data shuffling. By fine-tuning its parameters, CLF explicitly balances predictive accuracy with training stability, leading to more consistent and reliable model performance. Extensive experiments across diverse architectures for both image classification and time series forecasting demonstrate that our approach significantly improves training robustness without sacrificing predictive performance. These results establish CLF as an effective and efficient strategy for developing more stable, reliable and trustworthy neural networks.
Examining the Effect of Implementation Factors on Deep Learning Reproducibility
Dec 11, 2023Reproducing published deep learning papers to validate their conclusions can be difficult due to sources of irreproducibility. We investigate the impact that implementation factors have on the results and how they affect reproducibility of deep learning studies. Three deep learning experiments were ran five times each on 13 different hardware environments and four different software environments. The analysis of the 780 combined results showed that there was a greater than 6% accuracy range on the same deterministic examples introduced from hardware or software environment variations alone. To account for these implementation factors, researchers should run their experiments multiple times in different hardware and software environments to verify their conclusions are not affected.
Sources of Irreproducibility in Machine Learning: A Review
Apr 15, 2022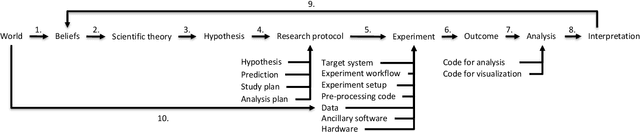
Lately, several benchmark studies have shown that the state of the art in some of the sub-fields of machine learning actually has not progressed despite progress being reported in the literature. The lack of progress is partly caused by the irreproducibility of many model comparison studies. Model comparison studies are conducted that do not control for many known sources of irreproducibility. This leads to results that cannot be verified by third parties. Our objective is to provide an overview of the sources of irreproducibility that are reported in the literature. We review the literature to provide an overview and a taxonomy in addition to a discussion on the identified sources of irreproducibility. Finally, we identify three lines of further inquiry.