 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular Design beyond Training Data with Novel Extended Objective Functionals of Generative AI Models Driven by Quantum Annealing Computer
Feb 17, 2026Deep generative modeling to stochastically design small molecules is an emerging technology for accelerating drug discovery and development. However, one major issue in molecular generative models is their lower frequency of drug-like compounds. To resolve this problem, we developed a novel framework for optimization of deep generative models integrated with a D-Wave quantum annealing computer, where our Neural Hash Function (NHF) presented herein is used both as the regularization and binarization schemes simultaneously, of which the latter is for transformation between continuous and discrete signals of the classical and quantum neural networks, respectively, in the error evaluation (i.e., objective) function. The compounds generated via the quantum-annealing generative models exhibited higher quality in both validity and drug-likeness than those generated via the fully-classical models, and was further indicated to exceed even the training data in terms of drug-likeness features, without any restraints and conditions to deliberately induce such an optimization. These results indicated an advantage of quantum annealing to aim at a stochastic generator integrated with our novel neural network architectures, for the extended performance of feature space sampling and extraction of characteristic features in drug design.
Blang: Bayesian declarative modelling of arbitrary data structures
Dec 22, 2019
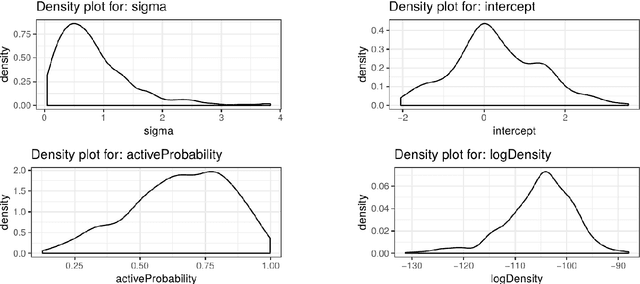
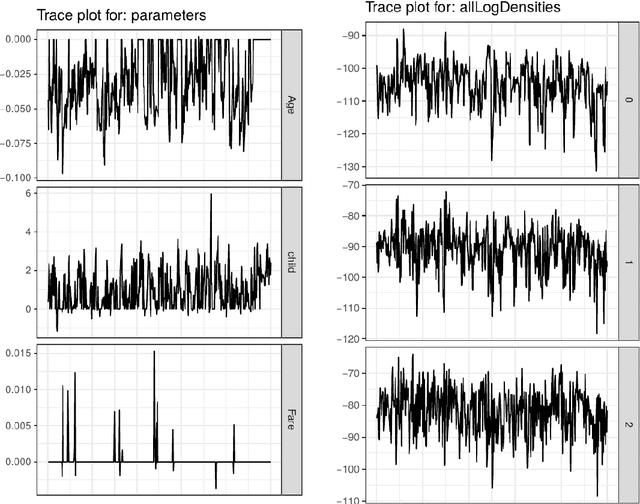
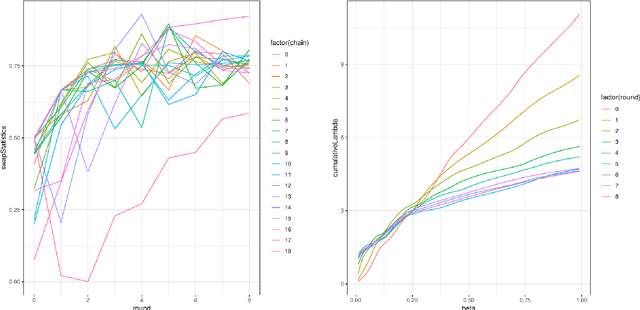
Consider a Bayesian inference problem where a variable of interest does not take values in a Euclidean space. These "non-standard" data structures are in reality fairly common. They are frequently used in problems involving latent discrete factor models, networks, and domain specific problems such as sequence alignments and reconstructions, pedigrees, and phylogenies. In principle, Bayesian inference should be particularly well-suited in such scenarios, as the Bayesian paradigm provides a principled way to obtain confidence assessment for random variables of any type. However, much of the recent work on making Bayesian analysis more accessible and computationally efficient has focused on inference in Euclidean spaces. In this paper, we introduce Blang, a domain specific language (DSL) and library aimed at bridging this gap. Blang allows users to perform Bayesian analysis on arbitrary data types while using a declarative syntax similar to BUGS. Blang is augmented with intuitive language additions to invent data types of the user's choosing. To perform inference at scale on such arbitrary state spaces, Blang leverages recent advances in parallelizable, non-reversible Markov chain Monte Carlo methods.