 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D scene reconstruction from monocular spherical video with motion parallax
Jun 14, 2022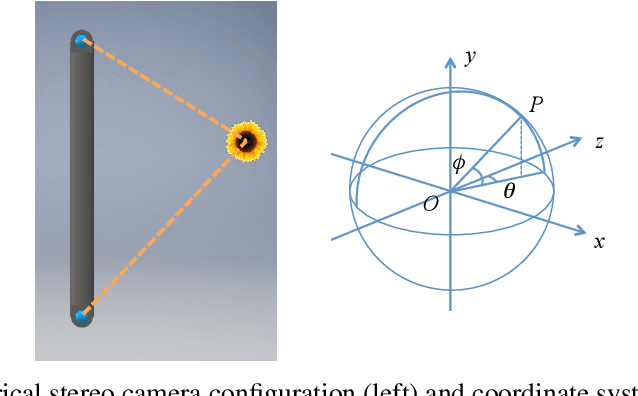
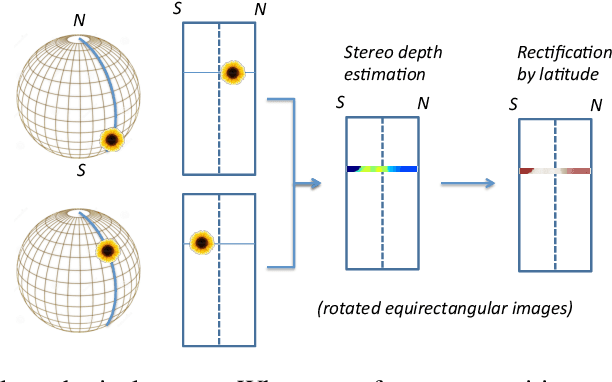

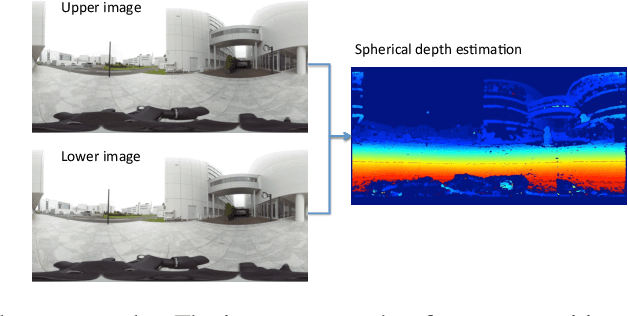
In this paper, we describe a method to capture nearly entirely spherical (360 degree) depth information using two adjacent frames from a single spherical video with motion parallax. After illustrating a spherical depth information retrieval using two spherical cameras, we demonstrate monocular spherical stereo by using stabilized first-person video footage. Experiments demonstrated that the depth information was retrieved on up to 97% of the entire sphere in solid angle. At a speed of 30 km/h, we were able to estimate the depth of an object located over 30 m from the camera. We also reconstructed the 3D structures (point cloud) using the obtained depth data and confirmed the structures can be clearly observed. We can apply this method to 3D structure retrieval of surrounding environments such as 1) previsualization, location hunting/planning of a film, 2) real scene/computer graphics synthesis and 3) motion capture. Thanks to its simplicity, this method can be applied to various videos. As there is no pre-condition other than to be a 360 video with motion parallax, we can use any 360 videos including those on the Internet to reconstruct the surrounding environments. The cameras can be lightweight enough to be mounted on a drone. We also demonstrated such applications.
Attempt to Predict Failure Case Classification in a Failure Database by using Neural Network Models
Sep 01, 2021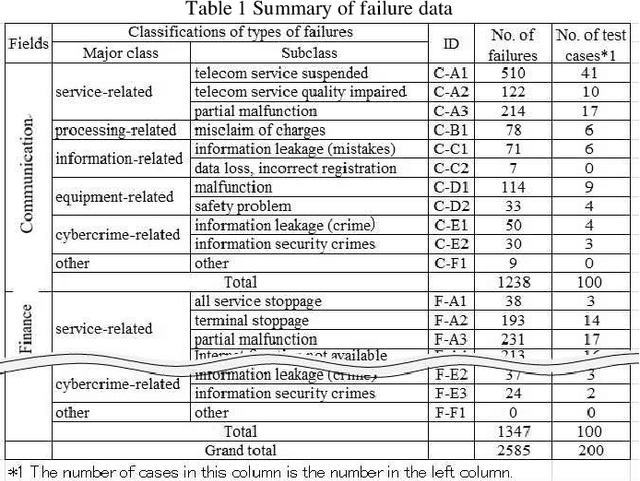
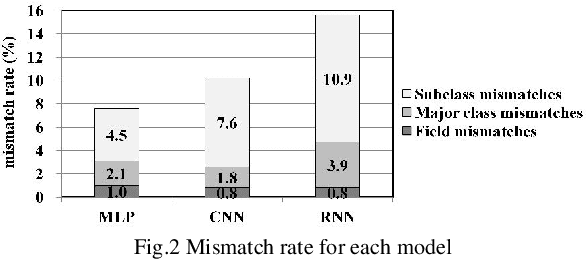
With the recent progress of information technology, the use of networked information systems has rapidly expanded. Electronic commerce and electronic payments between banks and companies, and online shopping and social networking services used by the general public are examples of such systems. Therefore, in order to maintain and improve the dependability of these systems, we are constructing a failure database from past failure cases. When importing new failure cases to the database, it is necessary to classify these cases according to failure type. The problems are the accuracy and efficiency of the classification. Especially when working with multiple individuals, unification of classification is required. Therefore, we are attempting to automate classification using machine learning. As evaluation models, we selected the multilayer perceptron (MLP), the convolutional neural network (CNN), and the recurrent neural network (RNN), which are models that use neural networks. As a result, the optimal model in terms of accuracy is first the MLP followed by the CNN, and the processing time of the classification is practical.