 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Question Answering Datasets Into Natural Language Inference Datasets
Sep 11, 2018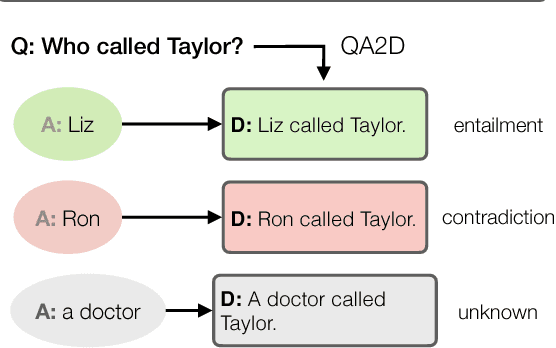
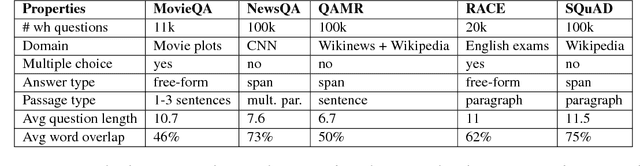

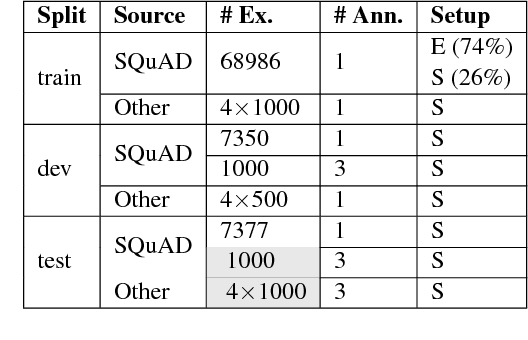
Existing datasets for natural language inference (NLI) have propelled research on language understanding. We propose a new method for automatically deriving NLI datasets from the growing abundance of large-scale question answering datasets. Our approach hinges on learning a sentence transformation model which converts question-answer pairs into their declarative forms. Despite being primarily trained on a single QA dataset, we show that it can be successfully applied to a variety of other QA resources. Using this system, we automatically derive a new freely available dataset of over 500k NLI examples (QA-NLI), and show that it exhibits a wide range of inference phenomena rarely seen in previous NLI datasets.
Generating Sentences by Editing Prototypes
Sep 07, 2018We propose a new generative model of sentences that first samples a prototype sentence from the training corpus and then edits it into a new sentence. Compared to traditional models that generate from scratch either left-to-right or by first sampling a latent sentence vector, our prototype-then-edit model improves perplexity on language modeling and generates higher quality outputs according to human evaluation. Furthermore, the model gives rise to a latent edit vector that captures interpretable semantics such as sentence similarity and sentence-level analogies.
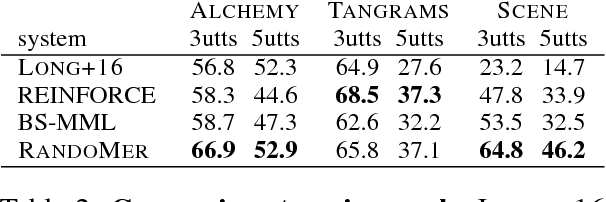
Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration
Feb 24, 2018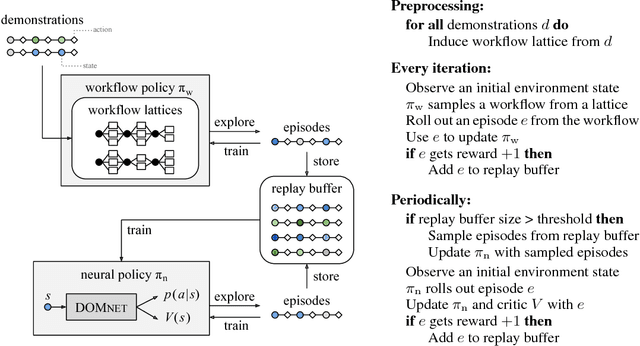

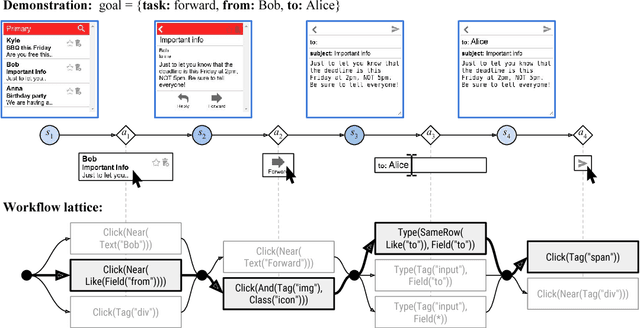
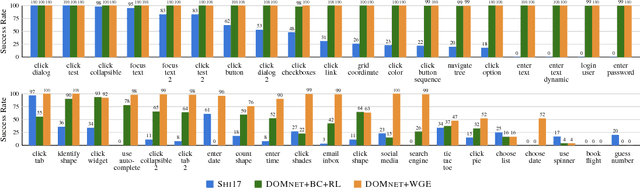
Reinforcement learning (RL) agents improve through trial-and-error, but when reward is sparse and the agent cannot discover successful action sequences, learning stagnates. This has been a notable problem in training deep RL agents to perform web-based tasks, such as booking flights or replying to emails, where a single mistake can ruin the entire sequence of actions. A common remedy is to "warm-start" the agent by pre-training it to mimic expert demonstrations, but this is prone to overfitting. Instead, we propose to constrain exploration using demonstrations. From each demonstration, we induce high-level "workflows" which constrain the allowable actions at each time step to be similar to those in the demonstration (e.g., "Step 1: click on a textbox; Step 2: enter some text"). Our exploration policy then learns to identify successful workflows and samples actions that satisfy these workflows. Workflows prune out bad exploration directions and accelerate the agent's ability to discover rewards. We use our approach to train a novel neural policy designed to handle the semi-structured nature of websites, and evaluate on a suite of web tasks, including the recent World of Bits benchmark. We achieve new state-of-the-art results, and show that workflow-guided exploration improves sample efficiency over behavioral cloning by more than 100x.
From Language to Programs: Bridging Reinforcement Learning and Maximum Marginal Likelihood
Apr 25, 2017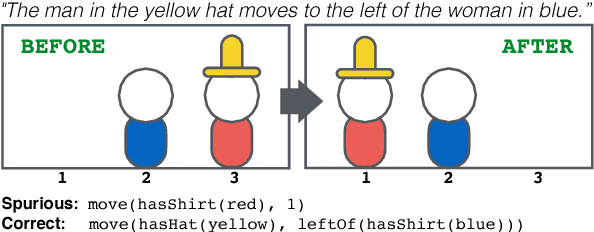

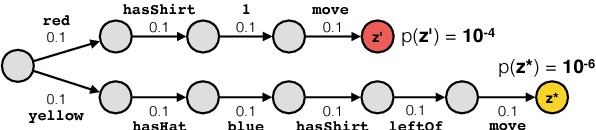
Our goal is to learn a semantic parser that maps natural language utterances into executable programs when only indirect supervision is available: examples are labeled with the correct execution result, but not the program itself. Consequently, we must search the space of programs for those that output the correct result, while not being misled by spurious programs: incorrect programs that coincidentally output the correct result. We connect two common learning paradigms, reinforcement learning (RL) and maximum marginal likelihood (MML), and then present a new learning algorithm that combines the strengths of both. The new algorithm guards against spurious programs by combining the systematic search traditionally employed in MML with the randomized exploration of RL, and by updating parameters such that probability is spread more evenly across consistent programs. We apply our learning algorithm to a new neural semantic parser and show significant gains over existing state-of-the-art results on a recent context-dependent semantic parsing task.
Traversing Knowledge Graphs in Vector Space
Aug 19, 2015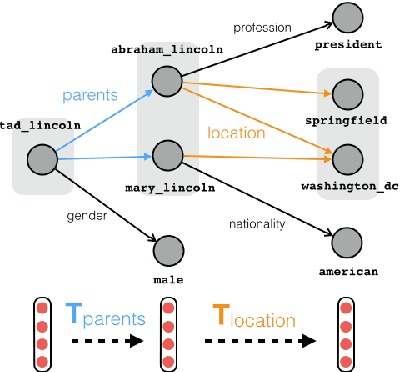
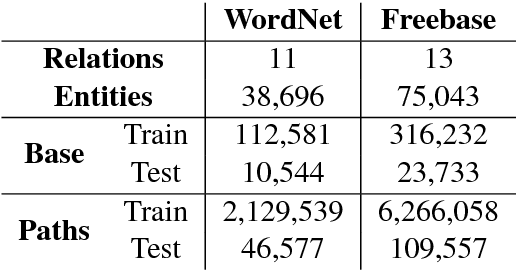
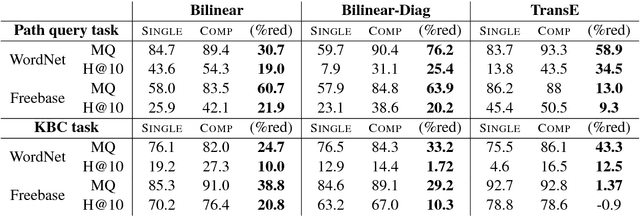
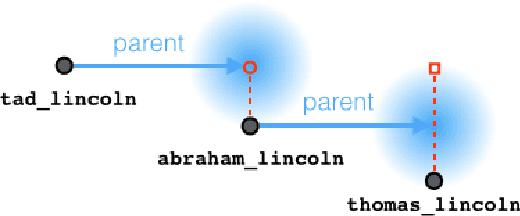
Path queries on a knowledge graph can be used to answer compositional questions such as "What languages are spoken by people living in Lisbon?". However, knowledge graphs often have missing facts (edges) which disrupts path queries. Recent models for knowledge base completion impute missing facts by embedding knowledge graphs in vector spaces. We show that these models can be recursively applied to answer path queries, but that they suffer from cascading errors. This motivates a new "compositional" training objective, which dramatically improves all models' ability to answer path queries, in some cases more than doubling accuracy. On a standard knowledge base completion task, we also demonstrate that compositional training acts as a novel form of structural regularization, reliably improving performance across all base models (reducing errors by up to 43%) and achieving new state-of-the-art results.