 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcceleration of the kernel herding algorithm by improved gradient approximation
May 17, 2021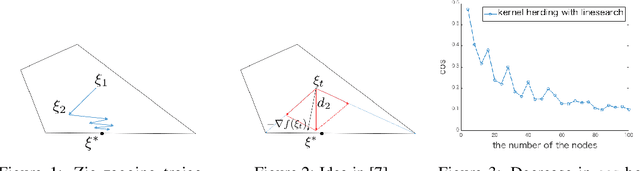
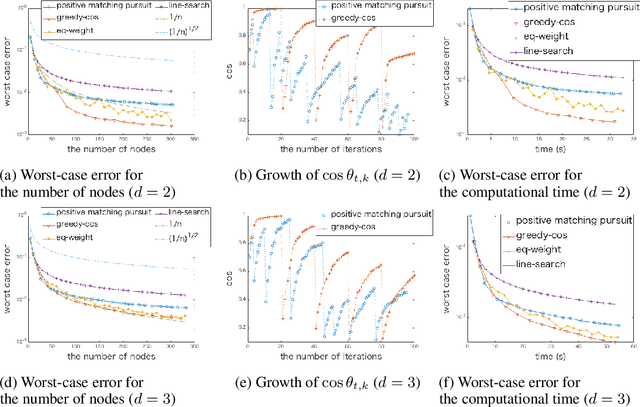
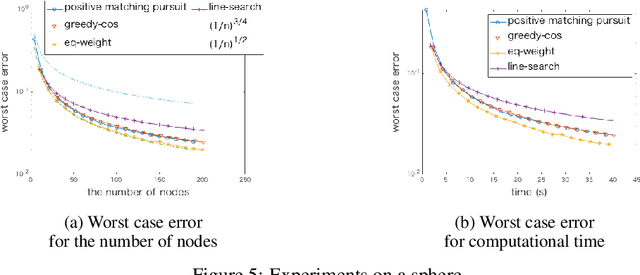
Kernel herding is a method used to construct quadrature formulas in a reproducing kernel Hilbert space. Although there are some advantages of kernel herding, such as numerical stability of quadrature and effective outputs of nodes and weights, the convergence speed of worst-case integration error is slow in comparison to other quadrature methods. To address this problem, we propose two improved versions of the kernel herding algorithm. The fundamental concept of both algorithms involves approximating negative gradients with a positive linear combination of vertex directions. We analyzed the convergence and validity of both algorithms theoretically; in particular, we showed that the approximation of negative gradients directly influences the convergence speed. In addition, we confirmed the accelerated convergence of the worst-case integration error with respect to the number of nodes and computational time through numerical experiments.
Estimation error analysis of deep learning on the regression problem on the variable exponent Besov space
Sep 27, 2020
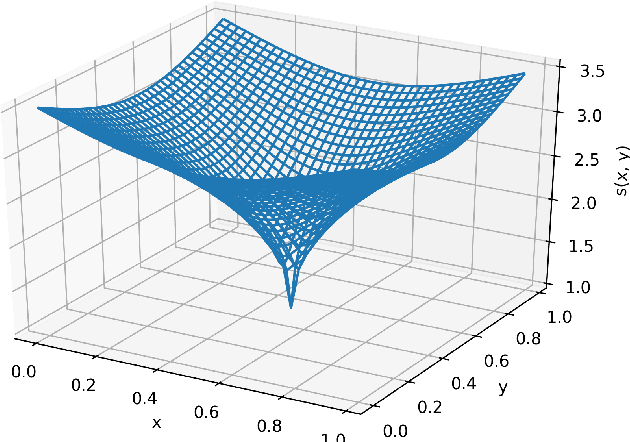
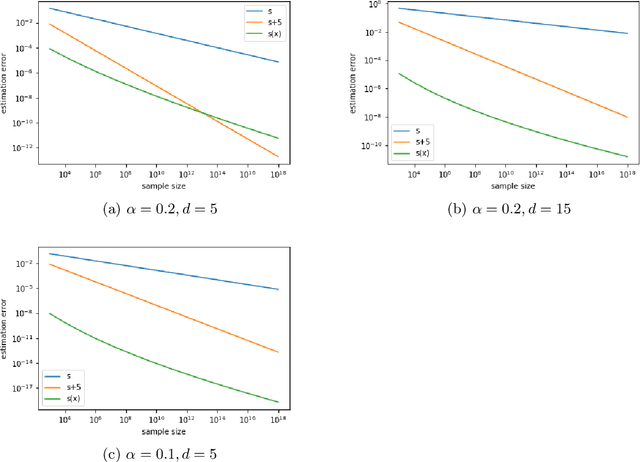
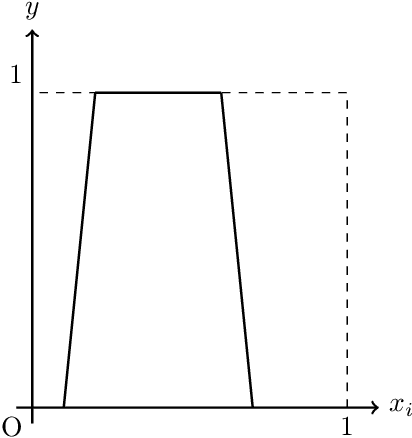
Deep learning has achieved notable success in various fields, including image and speech recognition. One of the factors in the successful performance of deep learning is its high feature extraction ability. In this study, we focus on the adaptivity of deep learning; consequently, we treat the variable exponent Besov space, which has a different smoothness depending on the input location $x$. In other words, the difficulty of the estimation is not uniform within the domain. We analyze the general approximation error of the variable exponent Besov space and the approximation and estimation errors of deep learning. We note that the improvement based on adaptivity is remarkable when the region upon which the target function has less smoothness is small and the dimension is large. Moreover, the superiority to linear estimators is shown with respect to the convergence rate of the estimation error.