 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComptonUNet: A Deep Learning Model for GRB Localization with Compton Cameras under Noisy and Low-Statistic Conditions
Feb 19, 2026Gamma-ray bursts (GRBs) are among the most energetic transient phenomena in the universe and serve as powerful probes for high-energy astrophysical processes. In particular, faint GRBs originating from a distant universe may provide unique insights into the early stages of star formation. However, detecting and localizing such weak sources remains challenging owing to low photon statistics and substantial background noise. Although recent machine learning models address individual aspects of these challenges, they often struggle to balance the trade-off between statistical robustness and noise suppression. Consequently, we propose ComptonUNet, a hybrid deep learning framework that jointly processes raw data and reconstructs images for robust GRB localization. ComptonUNet was designed to operate effectively under conditions of limited photon statistics and strong background contamination by combining the statistical efficiency of direct reconstruction models with the denoising capabilities of image-based architectures. We perform realistic simulations of GRB-like events embedded in background environments representative of low-Earth orbit missions to evaluate the performance of ComptonUNet. Our results demonstrate that ComptonUNet significantly outperforms existing approaches, achieving improved localization accuracy across a wide range of low-statistic and high-background scenarios.
Video Motion Capture from the Part Confidence Maps of Multi-Camera Images by Spatiotemporal Filtering Using the Human Skeletal Model
Dec 10, 2019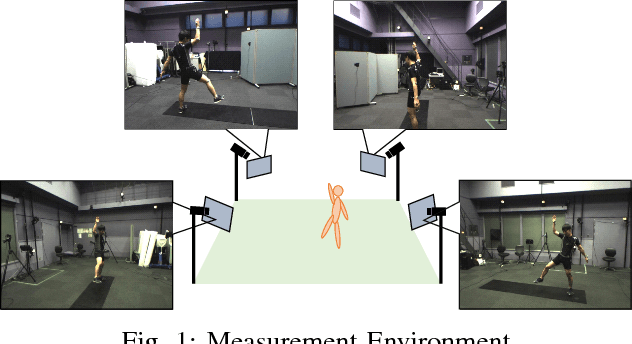

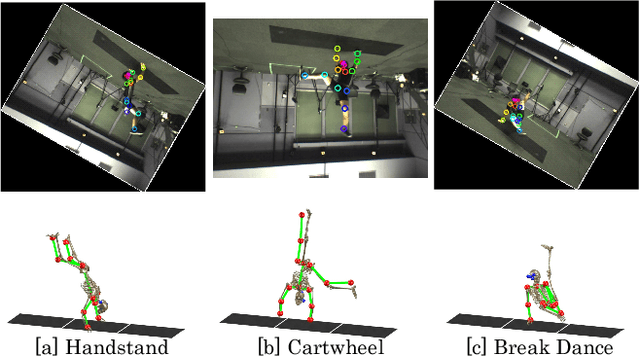
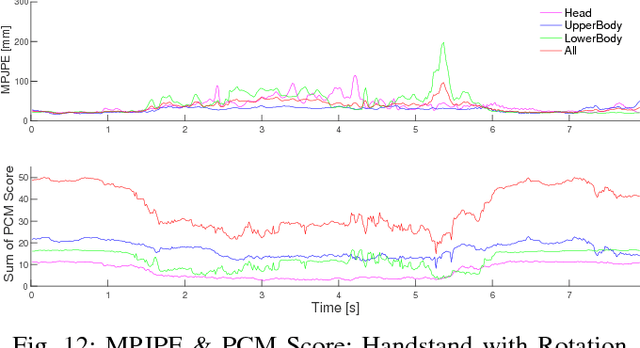
This paper discusses video motion capture, namely, 3D reconstruction of human motion from multi-camera images. After the Part Confidence Maps are computed from each camera image, the proposed spatiotemporal filter is applied to deliver the human motion data with accuracy and smoothness for human motion analysis. The spatiotemporal filter uses the human skeleton and mixes temporal smoothing in two-time inverse kinematics computations. The experimental results show that the mean per joint position error was 26.1mm for regular motions and 38.8mm for inverted motions.