 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Computational Power of Linear Transformers and Their Recurrent and Self-Referential Extensions
Oct 24, 2023Recent studies of the computational power of recurrent neural networks (RNNs) reveal a hierarchy of RNN architectures, given real-time and finite-precision assumptions. Here we study auto-regressive Transformers with linearised attention, a.k.a. linear Transformers (LTs) or Fast Weight Programmers (FWPs). LTs are special in the sense that they are equivalent to RNN-like sequence processors with a fixed-size state, while they can also be expressed as the now-popular self-attention networks. We show that many well-known results for the standard Transformer directly transfer to LTs/FWPs. Our formal language recognition experiments demonstrate how recently proposed FWP extensions such as recurrent FWPs and self-referential weight matrices successfully overcome certain limitations of the LT, e.g., allowing for generalisation on the parity problem. Our code is public.
Approximating Two-Layer Feedforward Networks for Efficient Transformers
Oct 23, 2023How to reduce compute and memory requirements of neural networks (NNs) without sacrificing performance? Many recent works use sparse Mixtures of Experts (MoEs) to build resource-efficient large language models (LMs). Here we introduce several novel perspectives on MoEs, presenting a general framework that unifies various methods to approximate two-layer NNs (e.g., feedforward blocks of Transformers), including product-key memories (PKMs). Leveraging insights from this framework, we propose methods to improve both MoEs and PKMs. Unlike prior work that compares MoEs with dense baselines under the compute-equal condition, our evaluation condition is parameter-equal, which is crucial to properly evaluate LMs. We show that our MoEs are competitive with the dense Transformer-XL on both the WikiText-103 and enwiki8 datasets at two different scales, while being much more resource efficient. This demonstrates that MoEs are relevant not only to extremely large LMs but also to any-scale resource-efficient LMs. Our code is public.
Exploring the Promise and Limits of Real-Time Recurrent Learning
May 30, 2023



Real-time recurrent learning (RTRL) for sequence-processing recurrent neural networks (RNNs) offers certain conceptual advantages over backpropagation through time (BPTT). RTRL requires neither caching past activations nor truncating context, and enables online learning. However, RTRL's time and space complexity make it impractical. To overcome this problem, most recent work on RTRL focuses on approximation theories, while experiments are often limited to diagnostic settings. Here we explore the practical promise of RTRL in more realistic settings. We study actor-critic methods that combine RTRL and policy gradients, and test them in several subsets of DMLab-30, ProcGen, and Atari-2600 environments. On DMLab memory tasks, our system trained on fewer than 1.2 B environmental frames is competitive with or outperforms well-known IMPALA and R2D2 baselines trained on 10 B frames. To scale to such challenging tasks, we focus on certain well-known neural architectures with element-wise recurrence, allowing for tractable RTRL without approximation. We also discuss rarely addressed limitations of RTRL in real-world applications, such as its complexity in the multi-layer case.
Mindstorms in Natural Language-Based Societies of Mind
May 26, 2023



Both Minsky's "society of mind" and Schmidhuber's "learning to think" inspire diverse societies of large multimodal neural networks (NNs) that solve problems by interviewing each other in a "mindstorm." Recent implementations of NN-based societies of minds consist of large language models (LLMs) and other NN-based experts communicating through a natural language interface. In doing so, they overcome the limitations of single LLMs, improving multimodal zero-shot reasoning. In these natural language-based societies of mind (NLSOMs), new agents -- all communicating through the same universal symbolic language -- are easily added in a modular fashion. To demonstrate the power of NLSOMs, we assemble and experiment with several of them (having up to 129 members), leveraging mindstorms in them to solve some practical AI tasks: visual question answering, image captioning, text-to-image synthesis, 3D generation, egocentric retrieval, embodied AI, and general language-based task solving. We view this as a starting point towards much larger NLSOMs with billions of agents-some of which may be humans. And with this emergence of great societies of heterogeneous minds, many new research questions have suddenly become paramount to the future of artificial intelligence. What should be the social structure of an NLSOM? What would be the (dis)advantages of having a monarchical rather than a democratic structure? How can principles of NN economies be used to maximize the total reward of a reinforcement learning NLSOM? In this work, we identify, discuss, and try to answer some of these questions.
Contrastive Training of Complex-Valued Autoencoders for Object Discovery
May 25, 2023



Current state-of-the-art object-centric models use slots and attention-based routing for binding. However, this class of models has several conceptual limitations: the number of slots is hardwired; all slots have equal capacity; training has high computational cost; there are no object-level relational factors within slots. Synchrony-based models in principle can address these limitations by using complex-valued activations which store binding information in their phase components. However, working examples of such synchrony-based models have been developed only very recently, and are still limited to toy grayscale datasets and simultaneous storage of less than three objects in practice. Here we introduce architectural modifications and a novel contrastive learning method that greatly improve the state-of-the-art synchrony-based model. For the first time, we obtain a class of synchrony-based models capable of discovering objects in an unsupervised manner in multi-object color datasets and simultaneously representing more than three objects
Accelerating Neural Self-Improvement via Bootstrapping
May 02, 2023Few-shot learning with sequence-processing neural networks (NNs) has recently attracted a new wave of attention in the context of large language models. In the standard N-way K-shot learning setting, an NN is explicitly optimised to learn to classify unlabelled inputs by observing a sequence of NK labelled examples. This pressures the NN to learn a learning algorithm that achieves optimal performance, given the limited number of training examples. Here we study an auxiliary loss that encourages further acceleration of few-shot learning, by applying recently proposed bootstrapped meta-learning to NN few-shot learners: we optimise the K-shot learner to match its own performance achievable by observing more than NK examples, using only NK examples. Promising results are obtained on the standard Mini-ImageNet dataset. Our code is public.
Topological Neural Discrete Representation Learning à la Kohonen
Feb 15, 2023Unsupervised learning of discrete representations from continuous ones in neural networks (NNs) is the cornerstone of several applications today. Vector Quantisation (VQ) has become a popular method to achieve such representations, in particular in the context of generative models such as Variational Auto-Encoders (VAEs). For example, the exponential moving average-based VQ (EMA-VQ) algorithm is often used. Here we study an alternative VQ algorithm based on the learning rule of Kohonen Self-Organising Maps (KSOMs; 1982) of which EMA-VQ is a special case. In fact, KSOM is a classic VQ algorithm which is known to offer two potential benefits over the latter: empirically, KSOM is known to perform faster VQ, and discrete representations learned by KSOM form a topological structure on the grid whose nodes are the discrete symbols, resulting in an artificial version of the topographic map in the brain. We revisit these properties by using KSOM in VQ-VAEs for image processing. In particular, our experiments show that, while the speed-up compared to well-configured EMA-VQ is only observable at the beginning of training, KSOM is generally much more robust than EMA-VQ, e.g., w.r.t. the choice of initialisation schemes. Our code is public.
Learning to Control Rapidly Changing Synaptic Connections: An Alternative Type of Memory in Sequence Processing Artificial Neural Networks
Nov 17, 2022Short-term memory in standard, general-purpose, sequence-processing recurrent neural networks (RNNs) is stored as activations of nodes or "neurons." Generalising feedforward NNs to such RNNs is mathematically straightforward and natural, and even historical: already in 1943, McCulloch and Pitts proposed this as a surrogate to "synaptic modifications" (in effect, generalising the Lenz-Ising model, the first non-sequence processing RNN architecture of the 1920s). A lesser known alternative approach to storing short-term memory in "synaptic connections" -- by parameterising and controlling the dynamics of a context-sensitive time-varying weight matrix through another NN -- yields another "natural" type of short-term memory in sequence processing NNs: the Fast Weight Programmers (FWPs) of the early 1990s. FWPs have seen a recent revival as generic sequence processors, achieving competitive performance across various tasks. They are formally closely related to the now popular Transformers. Here we present them in the context of artificial NNs as an abstraction of biological NNs -- a perspective that has not been stressed enough in previous FWP work. We first review aspects of FWPs for pedagogical purposes, then discuss connections to related works motivated by insights from neuroscience.
CTL++: Evaluating Generalization on Never-Seen Compositional Patterns of Known Functions, and Compatibility of Neural Representations
Oct 12, 2022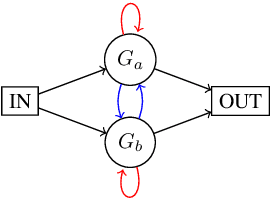
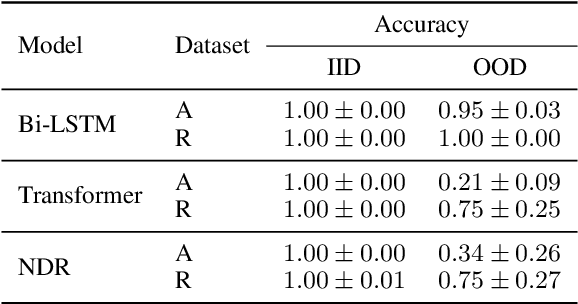
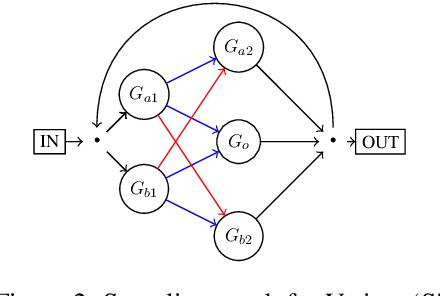
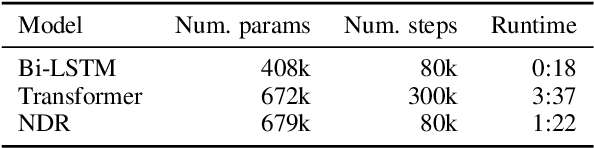
Well-designed diagnostic tasks have played a key role in studying the failure of neural nets (NNs) to generalize systematically. Famous examples include SCAN and Compositional Table Lookup (CTL). Here we introduce CTL++, a new diagnostic dataset based on compositions of unary symbolic functions. While the original CTL is used to test length generalization or productivity, CTL++ is designed to test systematicity of NNs, that is, their capability to generalize to unseen compositions of known functions. CTL++ splits functions into groups and tests performance on group elements composed in a way not seen during training. We show that recent CTL-solving Transformer variants fail on CTL++. The simplicity of the task design allows for fine-grained control of task difficulty, as well as many insightful analyses. For example, we measure how much overlap between groups is needed by tested NNs for learning to compose. We also visualize how learned symbol representations in outputs of functions from different groups are compatible in case of success but not in case of failure. These results provide insights into failure cases reported on more complex compositions in the natural language domain. Our code is public.
Images as Weight Matrices: Sequential Image Generation Through Synaptic Learning Rules
Oct 07, 2022
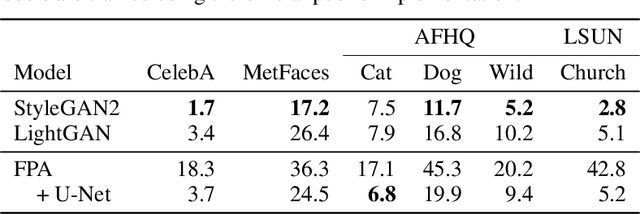
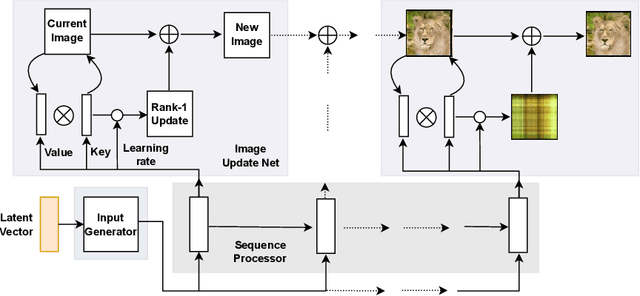
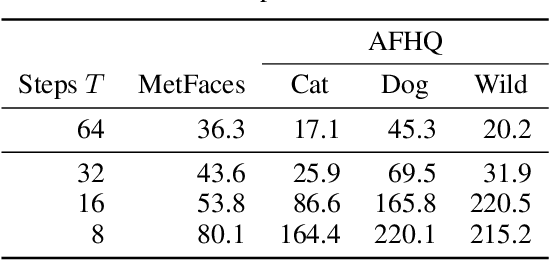
Work on fast weight programmers has demonstrated the effectiveness of key/value outer product-based learning rules for sequentially generating a weight matrix (WM) of a neural net (NN) by another NN or itself. However, the weight generation steps are typically not visually interpretable by humans, because the contents stored in the WM of an NN are not. Here we apply the same principle to generate natural images. The resulting fast weight painters (FPAs) learn to execute sequences of delta learning rules to sequentially generate images as sums of outer products of self-invented keys and values, one rank at a time, as if each image was a WM of an NN. We train our FPAs in the generative adversarial networks framework, and evaluate on various image datasets. We show how these generic learning rules can generate images with respectable visual quality without any explicit inductive bias for images. While the performance largely lags behind the one of specialised state-of-the-art image generators, our approach allows for visualising how synaptic learning rules iteratively produce complex connection patterns, yielding human-interpretable meaningful images. Finally, we also show that an additional convolutional U-Net (now popular in diffusion models) at the output of an FPA can learn one-step "denoising" of FPA-generated images to enhance their quality. Our code is public.