 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning with Weighted Inner Product for Universal Approximation of General Similarities
Feb 27, 2019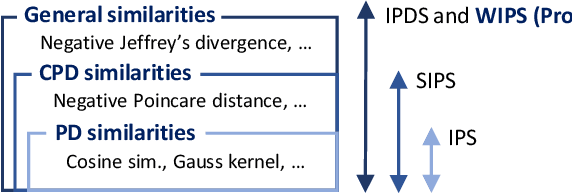
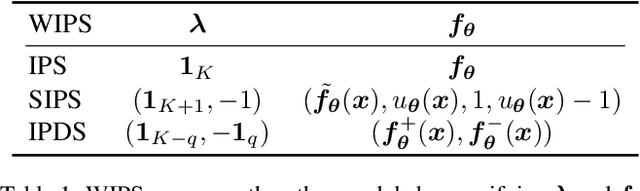
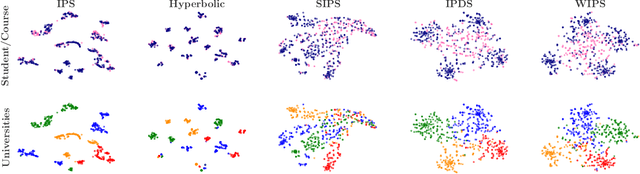
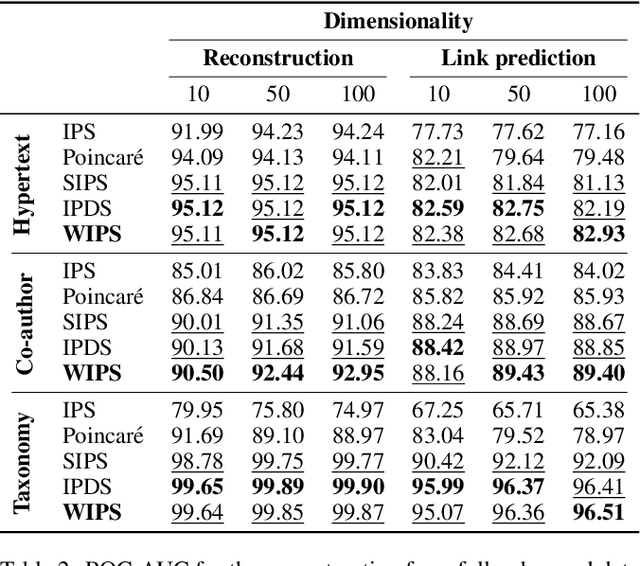
We propose $\textit{weighted inner product similarity}$ (WIPS) for neural-network based graph embedding, where we optimize the weights of the inner product in addition to the parameters of neural networks. Despite its simplicity, WIPS can approximate arbitrary general similarities including positive definite, conditionally positive definite, and indefinite kernels. WIPS is free from similarity model selection, yet it can learn any similarity models such as cosine similarity, negative Poincar\'e distance and negative Wasserstein distance. Our extensive experiments show that the proposed method can learn high-quality distributed representations of nodes from real datasets, leading to an accurate approximation of similarities as well as high performance in inductive tasks.
Segmentation-free compositional $n$-gram embedding
Sep 04, 2018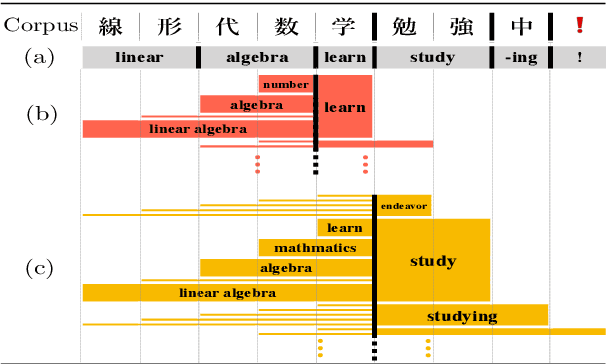

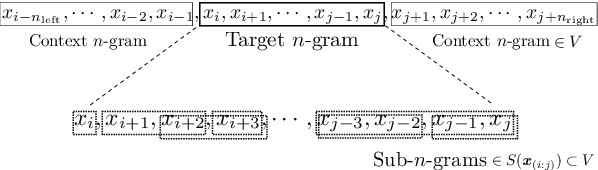
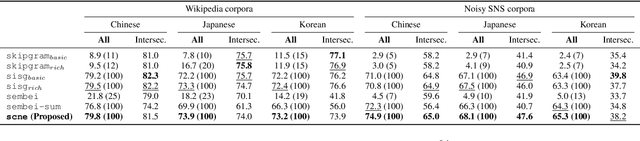
Applying conventional word embedding models to unsegmented languages, where word boundary is not clear, requires word segmentation as preprocessing. However, word segmentation is difficult and expensive to conduct without errors. Segmentation error degrades the quality of word embeddings, leading to performance degradation in downstream applications. In this paper, we propose a simple segmentation-free method to obtain unsupervised vector representations for words, phrases and sentences from an unsegmented raw corpus. Our model is based on subword information skip-gram model, but embedding targets and contexts are character $n$-grams instead of segmented words. We consider all possible character $n$-grams in a corpus as targets, and every target is modeled as the sum of its compositional sub-$n$-grams. Our method completely ignores word boundaries in a corpus and is not word-segmentation dependent. This approach may sound reckless, but it was found to work well through experiments on real-world datasets and benchmarks.