 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Basic Evaluation of Neural Networks Trained with the Error Diffusion Learning Algorithm
Apr 21, 2025Artificial neural networks are powerful tools capable of addressing various tasks. Although the backpropagation algorithm has become a standard training method for these neural networks, its lack of biological plausibility has inspired the development of alternative learning approaches. One such alternative is Kaneko's Error Diffusion Learning Algorithm (EDLA), a biologically motivated approach wherein a single global error signal diffuses throughout a network composed of paired excitatory-inhibitory sublayers, thereby eliminating the necessity for layer-wise backpropagation. This study presents a contemporary formulation of the EDLA framework and evaluates its effectiveness through parity check, regression, and image classification tasks. Our experimental results indicate that EDLA networks can consistently achieve high accuracy across these benchmarks, with performance efficiency and convergence speed notably influenced by the choice of learning rate, neuron count, and network depth. Further investigation of the internal representations formed by EDLA networks reveals their capacity for meaningful feature extraction, similar to traditional neural networks. These results suggest that EDLA is a biologically motivated alternative for training feedforward networks and will motivate future work on extending this method to biologically inspired neural networks.
Flexible game-playing AI with AlphaViT: adapting to multiple games and board sizes
Aug 25, 2024This paper presents novel game AI agents based on the AlphaZero framework, enhanced with Vision Transformers (ViT): AlphaViT, AlphaViD, and AlphaVDA. These agents are designed to play various board games of different sizes using a single model, overcoming AlphaZero's limitation of being restricted to a fixed board size. AlphaViT uses only a transformer encoder, while AlphaViD and AlphaVDA contain both an encoder and a decoder. AlphaViD's decoder receives input from the encoder output, while AlphaVDA uses a learnable matrix as decoder input. Using the AlphaZero framework, the three proposed methods demonstrate their versatility in different game environments, including Connect4, Gomoku, and Othello. Experimental results show that these agents, whether trained on a single game or on multiple games simultaneously, consistently outperform traditional algorithms such as Minimax and Monte Carlo tree search using a single DNN with shared weights, while approaching the performance of AlphaZero. In particular, AlphaViT and AlphaViD show strong performance across games, with AlphaViD benefiting from an additional decoder layer that enhances its ability to adapt to different action spaces and board sizes. These results may suggest the potential of transformer-based architectures to develop more flexible and robust game AI agents capable of excelling in multiple games and dynamic environments.
Characteristics of networks generated by kernel growing neural gas
Aug 25, 2023This research aims to develop kernel GNG, a kernelized version of the growing neural gas (GNG) algorithm, and to investigate the features of the networks generated by the kernel GNG. The GNG is an unsupervised artificial neural network that can transform a dataset into an undirected graph, thereby extracting the features of the dataset as a graph. The GNG is widely used in vector quantization, clustering, and 3D graphics. Kernel methods are often used to map a dataset to feature space, with support vector machines being the most prominent application. This paper introduces the kernel GNG approach and explores the characteristics of the networks generated by kernel GNG. Five kernels, including Gaussian, Laplacian, Cauchy, inverse multiquadric, and log kernels, are used in this study. The results of this study show that the average degree and the average clustering coefficient decrease as the kernel parameter increases for Gaussian, Laplacian, Cauchy, and IMQ kernels. If we avoid more edges and a higher clustering coefficient (or more triangles), the kernel GNG with a larger value of the parameter will be more appropriate.
An efficient and straightforward online quantization method for a data stream through remove-birth updating
Jun 21, 2023The growth of network-connected devices is creating an explosion of data, known as big data, and posing significant challenges to efficient data analysis. This data is generated continuously, creating a dynamic flow known as a data stream. The characteristics of a data stream may change dynamically, and this change is known as concept drift. Consequently, a method for handling data streams must efficiently reduce their volume while dynamically adapting to these changing characteristics. This paper proposes a simple online vector quantization method for concept drift. The proposed method identifies and replaces units with low win probability through remove-birth updating, thus achieving a rapid adaptation to concept drift. Furthermore, the results of this study show that the proposed method can generate minimal dead units even in the presence of concept drift. This study also suggests that some metrics calculated from the proposed method will be helpful for drift detection.
AlphaDDA: game artificial intelligence with dynamic difficulty adjustment using AlphaZero
Nov 20, 2021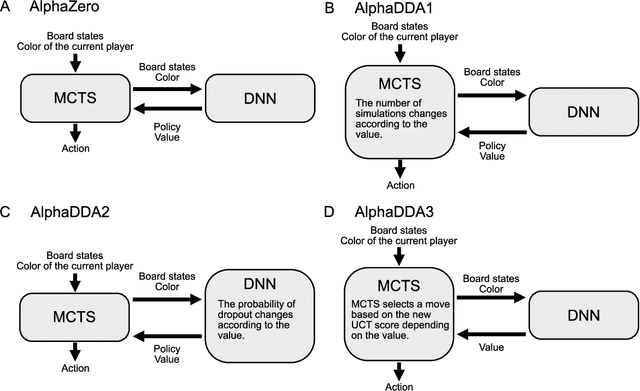
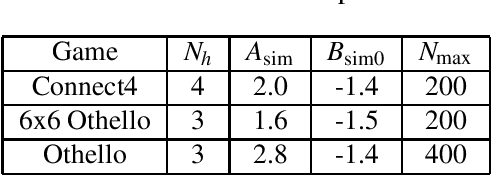

An artificial intelligence (AI) player has obtained superhuman skill for games like Go, Chess, and Othello (Reversi). In other words, the AI player becomes too strong as an opponent of human players. Then, we will not enjoy playing board games with the AI player. In order to entertain human players, the AI player is required to balance its skill with the human player's one automatically. To address this issue, I propose AlphaDDA, an AI player with dynamic difficulty adjustment based on AlphaZero. AlphaDDA consists of a deep neural network (DNN) and Monte Carlo tree search like AlphaZero. AlphaDDA estimates the value of the game state form only the board state using the DNN and changes its skill according to the value. AlphaDDA can adjust AlphaDDA's skill using only the state of a game without prior knowledge about an opponent. In this study, AlphaDDA plays Connect4, 6x6 Othello, which is Othello using a 6x6 size board, and Othello with the other AI agents. The other AI agents are AlphaZero, Monte Carlo tree search, Minimax algorithm, and a random player. This study shows that AlphaDDA achieves to balance its skill with the other AI agents except for a random player. AlphaDDA's DDA ability is derived from the accurate estimation of the value from the state of a game. We will be able to use the approach of AlphaDDA for any games in that the DNN can estimate the value from the state.
Estimation of the number of clusters on d-dimensional sphere
Nov 15, 2020
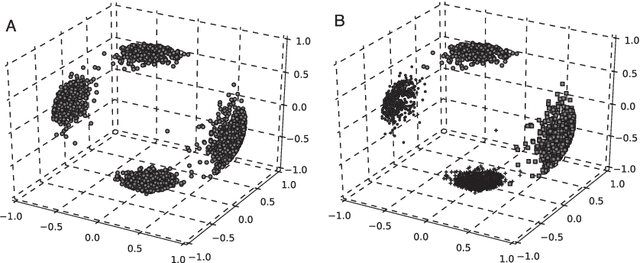
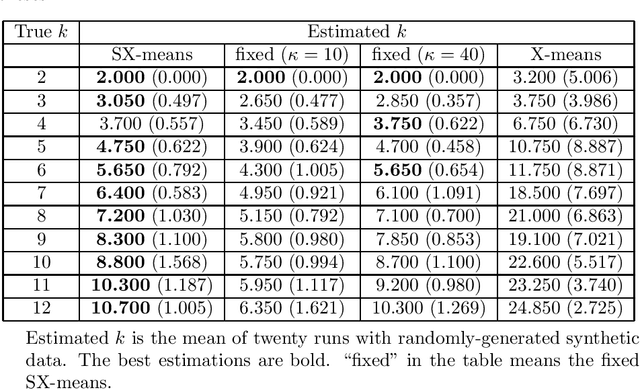
Spherical data is distributed on the sphere. The data appears in various fields such as meteorology, biology, and natural language processing. However, a method for analysis of spherical data does not develop enough yet. One of the important issues is an estimation of the number of clusters in spherical data. To address the issue, I propose a new method called the Spherical X-means (SX-means) that can estimate the number of clusters on d-dimensional sphere. The SX-means is the model-based method assuming that the data is generated from a mixture of von Mises-Fisher distributions. The present paper explains the proposed method and shows its performance of estimation of the number of clusters.
Approximate spectral clustering using both reference vectors and topology of the network generated by growing neural gas
Sep 15, 2020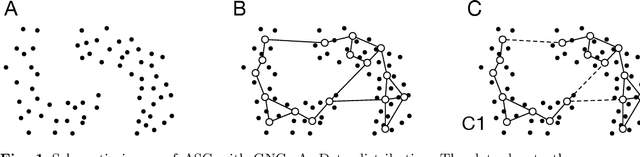
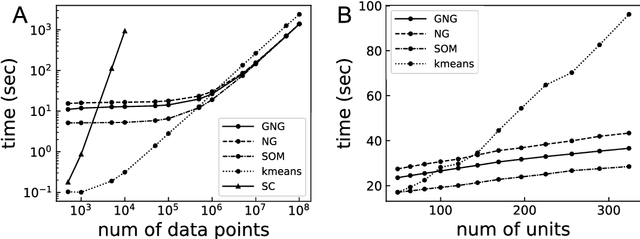
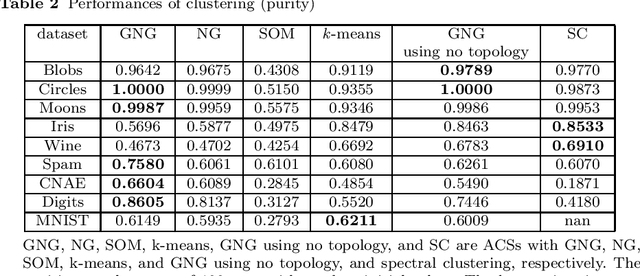
Spectral clustering (SC) is one of the most popular clustering methods and often outperforms traditional clustering methods. SC uses the eigenvectors of a Laplacian matrix calculated from a similarity matrix of a dataset. SC has serious drawbacks that are the significant increase in the computational complexity derived from the eigendecomposition and the memory space complexities to store the similarity matrix. To address the issues, I develop a new approximate spectral clustering using the network generated by growing neural gas (GNG), called ASC with GNG in this study. The proposed method uses not only reference vectors for vector quantization but also the topology of the network for extraction of the topological relationship between data points in a dataset. The similarity matrix used by ASC with GNG is made from both the reference vectors and the topology of the network generated by GNG. Using the network generated from a dataset by GNG, we achieve to reduce the computational and space complexities and to improve clustering quality. This paper demonstrates that the proposed method effectively reduces the computational time. Moreover, the results of this study show that the proposed method displays equal to or better performance of clustering than SC.
Extract an essential skeleton of a character as a graph from a character image
Jun 13, 2015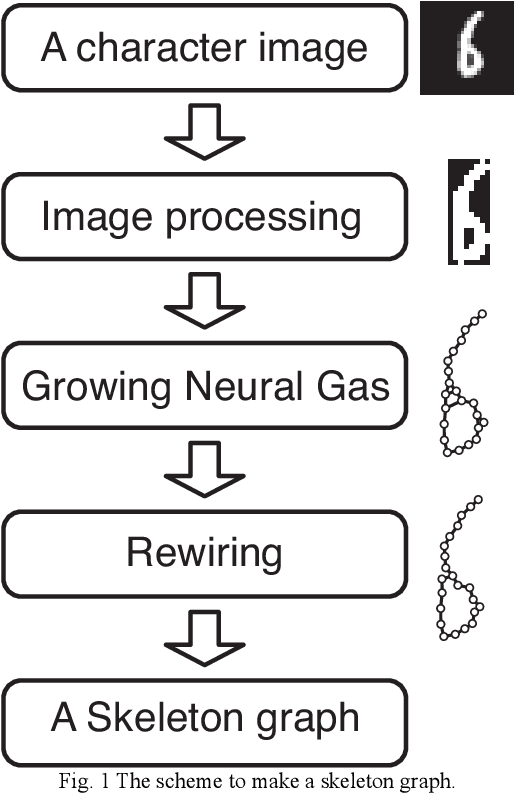
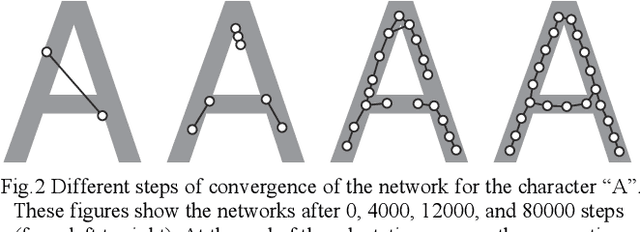
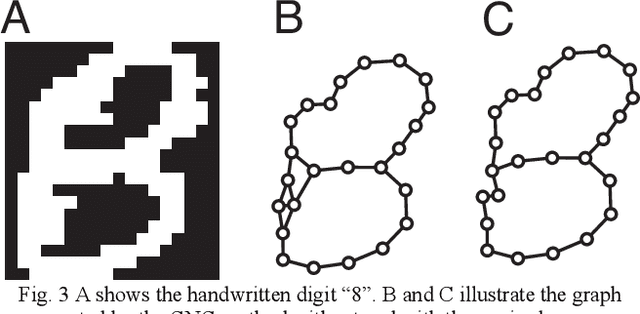

This paper aims to make a graph representing an essential skeleton of a character from an image that includes a machine printed or a handwritten character using the growing neural gas (GNG) method and the relative neighborhood graph (RNG) algorithm. The visual system in our brain can recognize printed characters and handwritten characters easily, robustly, and precisely. How can our brains robustly recognize characters? In the visual processing in our brain, essential features of an object will be used for recognition. The essential features are crosses, corners, junctions and so on. These features may be useful for character recognition by a computer. However, extraction of the features is difficult. If the skeleton of a character is represented as a graph, the features can be more easily extracted. To extract the skeleton of a character as a graph from a character image, we used the GNG method and the RNG algorithm. We achieved to extract skeleton graphs from images including distorted, noisy, and handwritten characters.