 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn extension of linear self-attention for in-context learning
Mar 31, 2025In-context learning is a remarkable property of transformers and has been the focus of recent research. An attention mechanism is a key component in transformers, in which an attention matrix encodes relationships between words in a sentence and is used as weights for words in a sentence. This mechanism is effective for capturing language representations. However, it is questionable whether naive self-attention is suitable for in-context learning in general tasks, since the computation implemented by self-attention is somewhat restrictive in terms of matrix multiplication. In fact, we may need appropriate input form designs when considering heuristic implementations of computational algorithms. In this paper, in case of linear self-attention, we extend it by introducing a bias matrix in addition to a weight matrix for an input. Despite the simple extension, the extended linear self-attention can output any constant matrix, input matrix and multiplications of two or three matrices in the input. Note that the second property implies that it can be a skip connection. Therefore, flexible matrix manipulations can be implemented by connecting the extended linear self-attention components. As an example of implementation using the extended linear self-attention, we show a heuristic construction of a batch-type gradient descent of ridge regression under a reasonable input form.
Over-parameterized regression methods and their application to semi-supervised learning
Sep 06, 2024The minimum norm least squares is an estimation strategy under an over-parameterized case and, in machine learning, is known as a helpful tool for understanding a nature of deep learning. In this paper, to apply it in a context of non-parametric regression problems, we established several methods which are based on thresholding of SVD (singular value decomposition) components, wihch are referred to as SVD regression methods. We considered several methods that are singular value based thresholding, hard-thresholding with cross validation, universal thresholding and bridge thresholding. Information on output samples is not utilized in the first method while it is utilized in the other methods. We then applied them to semi-supervised learning, in which unlabeled input samples are incorporated into kernel functions in a regressor. The experimental results for real data showed that, depending on the datasets, the SVD regression methods is superior to a naive ridge regression method. Unfortunately, there were no clear advantage of the methods utilizing information on output samples. Furthermore, for depending on datasets, incorporation of unlabeled input samples into kernels is found to have certain advantages.
On gradient descent training under data augmentation with on-line noisy copies
Jun 16, 2022
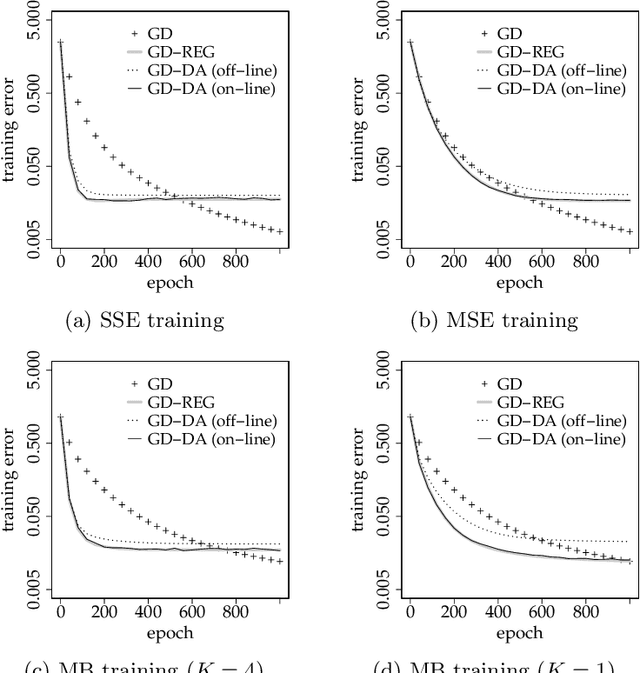
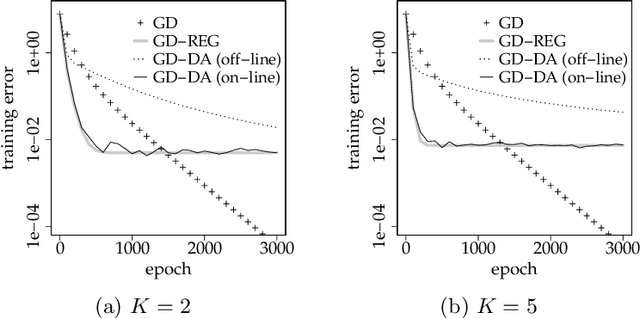
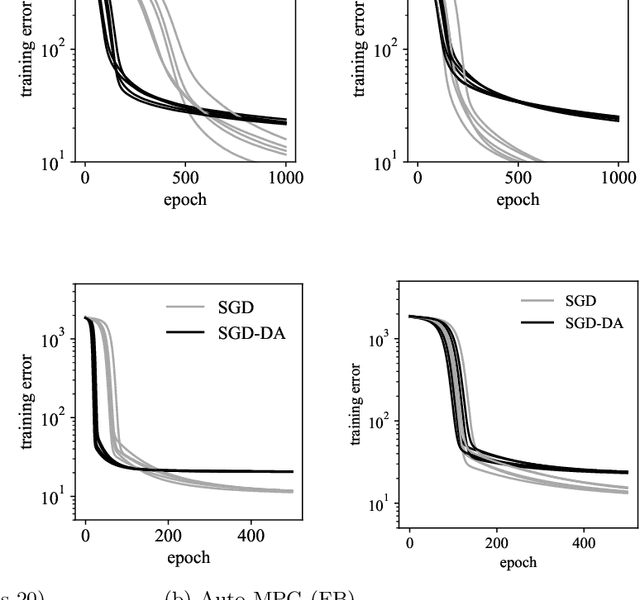
In machine learning, data augmentation (DA) is a technique for improving the generalization performance. In this paper, we mainly considered gradient descent of linear regression under DA using noisy copies of datasets, in which noise is injected into inputs. We analyzed the situation where random noisy copies are newly generated and used at each epoch; i.e., the case of using on-line noisy copies. Therefore, it is viewed as an analysis on a method using noise injection into training process by DA manner; i.e., on-line version of DA. We derived the averaged behavior of training process under three situations which are the full-batch training under the sum of squared errors, the full-batch and mini-batch training under the mean squared error. We showed that, in all cases, training for DA with on-line copies is approximately equivalent to a ridge regularization whose regularization parameter corresponds to the variance of injected noise. On the other hand, we showed that the learning rate is multiplied by the number of noisy copies plus one in full-batch under the sum of squared errors and the mini-batch under the mean squared error; i.e., DA with on-line copies yields apparent acceleration of training. The apparent acceleration and regularization effect come from the original part and noise in a copy data respectively. These results are confirmed in a numerical experiment. In the numerical experiment, we found that our result can be approximately applied to usual off-line DA in under-parameterization scenario and can not in over-parametrization scenario. Moreover, we experimentally investigated the training process of neural networks under DA with off-line noisy copies and found that our analysis on linear regression is possible to be applied to neural networks.
Bridging between soft and hard thresholding by scaling
Apr 20, 2021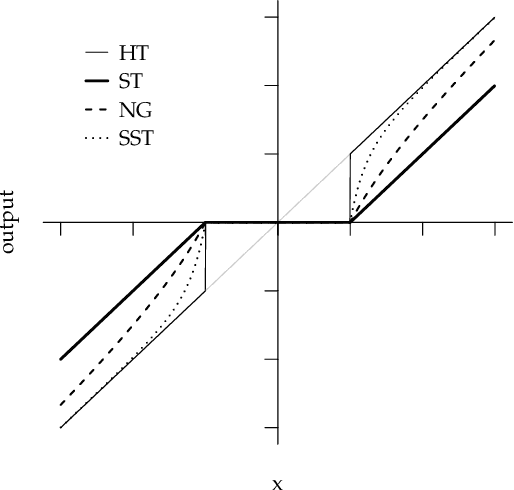
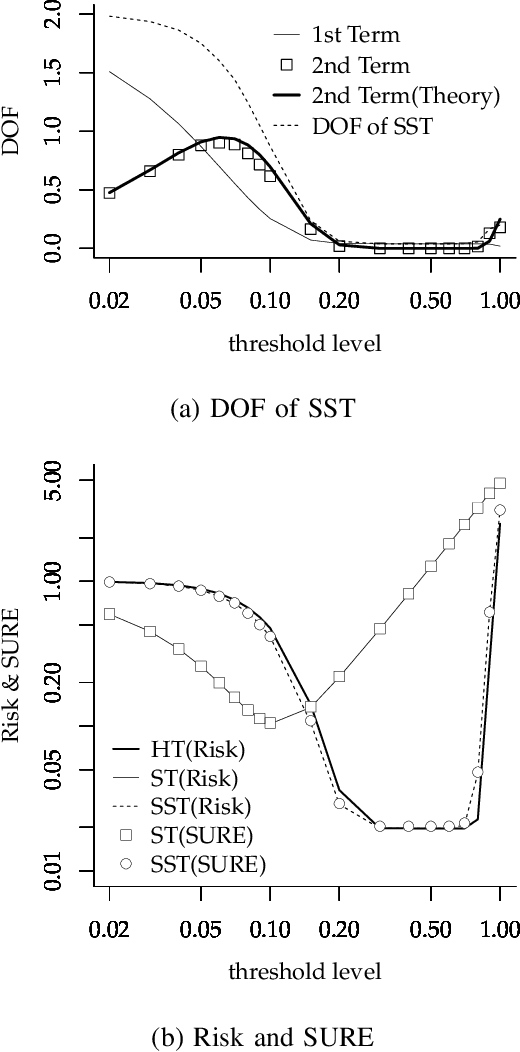
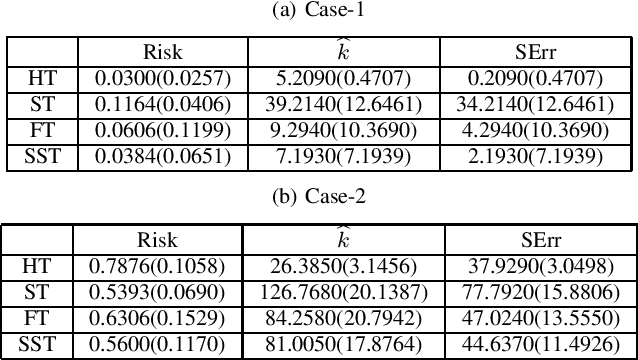
In this article, we developed and analyzed a thresholding method in which soft thresholding estimators are independently expanded by empirical scaling values. The scaling values have a common hyper-parameter that is an order of expansion of an ideal scaling value that achieves hard thresholding. We simply call this estimator a scaled soft thresholding estimator. The scaled soft thresholding is a general method that includes the soft thresholding and non-negative garrote as special cases and gives an another derivation of adaptive LASSO. We then derived the degree of freedom of the scaled soft thresholding by means of the Stein's unbiased risk estimate and found that it is decomposed into the degree of freedom of soft thresholding and the reminder connecting to hard thresholding. In this meaning, the scaled soft thresholding gives a natural bridge between soft and hard thresholding methods. Since the degree of freedom represents the degree of over-fitting, this result implies that there are two sources of over-fitting in the scaled soft thresholding. The first source originated from soft thresholding is determined by the number of un-removed coefficients and is a natural measure of the degree of over-fitting. We analyzed the second source in a particular case of the scaled soft thresholding by referring a known result for hard thresholding. We then found that, in a sparse, large sample and non-parametric setting, the second source is largely determined by coefficient estimates whose true values are zeros and has an influence on over-fitting when threshold levels are around noise levels in those coefficient estimates. In a simple numerical example, these theoretical implications has well explained the behavior of the degree of freedom. Moreover, based on the results here and some known facts, we explained the behaviors of risks of soft, hard and scaled soft thresholding methods.
On an improvement of LASSO by scaling
Aug 22, 2018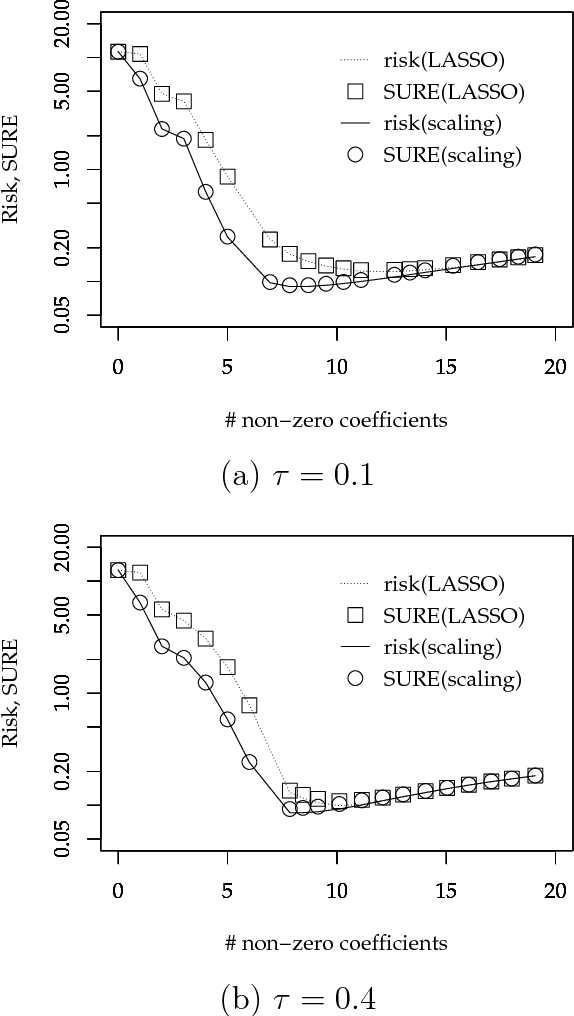
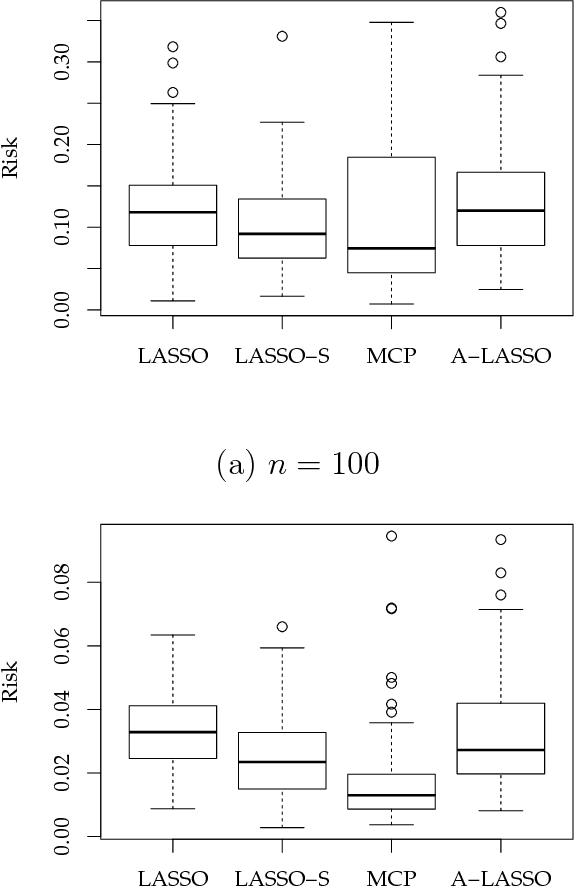
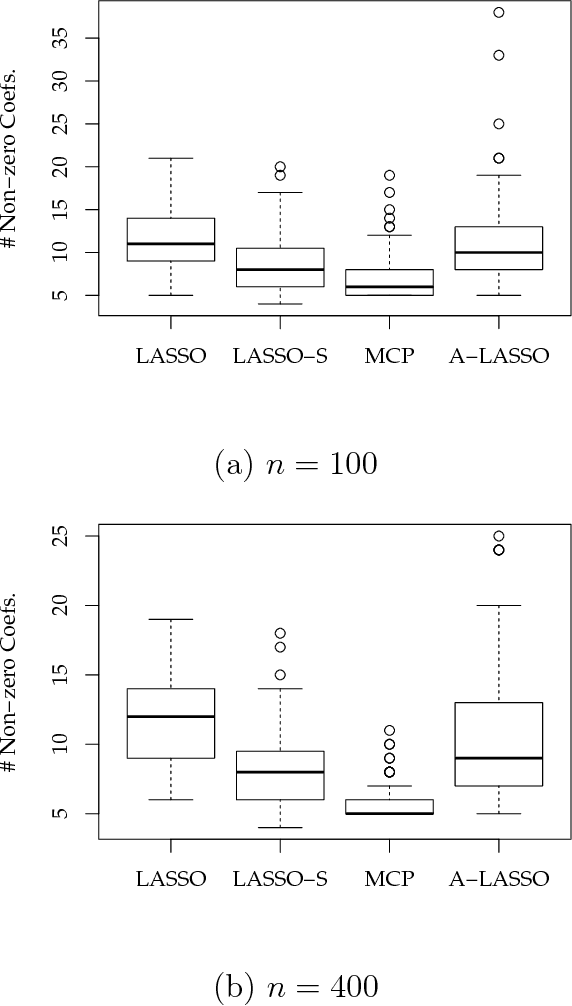
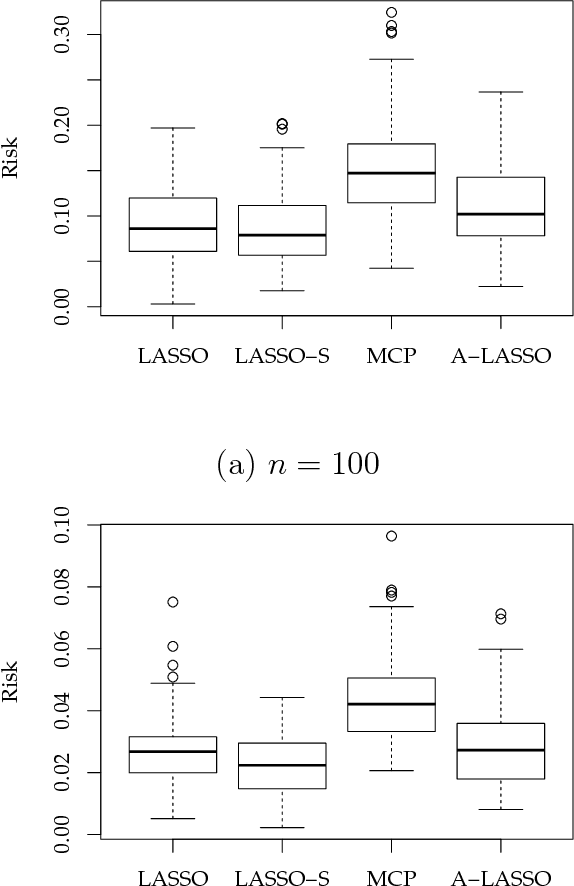
A sparse modeling is a major topic in machine learning and statistics. LASSO (Least Absolute Shrinkage and Selection Operator) is a popular sparse modeling method while it has been known to yield unexpected large bias especially at a sparse representation. There have been several studies for improving this problem such as the introduction of non-convex regularization terms. The important point is that this bias problem directly affects model selection in applications since a sparse representation cannot be selected by a prediction error based model selection even if it is a good representation. In this article, we considered to improve this problem by introducing a scaling that expands LASSO estimator to compensate excessive shrinkage, thus a large bias in LASSO estimator. We here gave an empirical value for the amount of scaling. There are two advantages of this scaling method as follows. Since the proposed scaling value is calculated by using LASSO estimator, we only need LASSO estimator that is obtained by a fast and stable optimization procedure such as LARS (Least Angle Regression) under LASSO modification or coordinate descent. And, the simplicity of our scaling method enables us to derive SURE (Stein's Unbiased Risk Estimate) under the modified LASSO estimator with scaling. Our scaling method together with model selection based on SURE is fully empirical and do not need additional hyper-parameters. In a simple numerical example, we verified that our scaling method actually improves LASSO and the SURE based model selection criterion can stably choose an appropriate sparse model.