 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Sociolinguistic Variation in the Competing Vaccination Communities
Jul 01, 2020

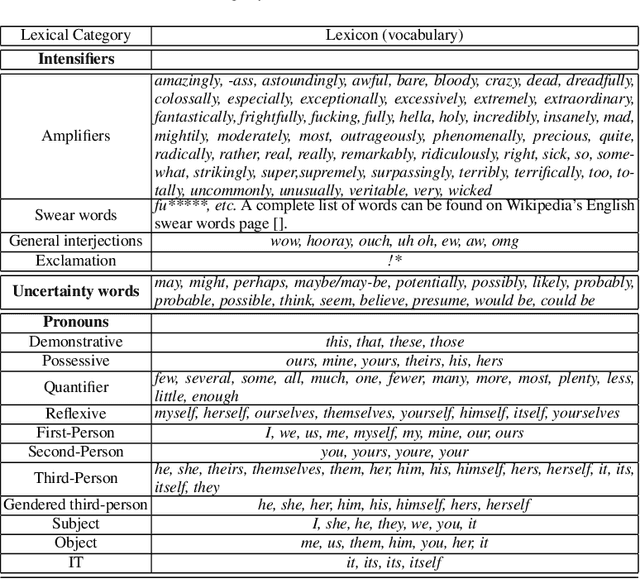
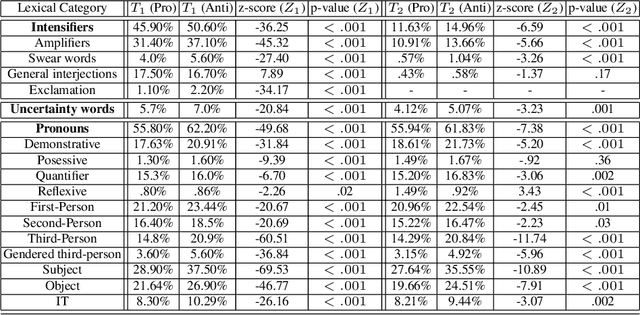
Public health practitioners and policy makers grapple with the challenge of devising effective message-based interventions for debunking public health misinformation in cyber communities. "Framing" and "personalization" of the message is one of the key features for devising a persuasive messaging strategy. For an effective health communication, it is imperative to focus on "preference-based framing" where the preferences of the target sub-community are taken into consideration. To achieve that, it is important to understand and hence characterize the target sub-communities in terms of their social interactions. In the context of health-related misinformation, vaccination remains to be the most prevalent topic of discord. Hence, in this paper, we conduct a sociolinguistic analysis of the two competing vaccination communities on Twitter: "pro-vaxxers" or individuals who believe in the effectiveness of vaccinations, and "anti-vaxxers" or individuals who are opposed to vaccinations. Our data analysis show significant linguistic variation between the two communities in terms of their usage of linguistic intensifiers, pronouns, and uncertainty words. Our network-level analysis show significant differences between the two communities in terms of their network density, echo-chamberness, and the EI index. We hypothesize that these sociolinguistic differences can be used as proxies to characterize and understand these communities to devise better message interventions.
Stance in Replies and Quotes : A New Dataset For Learning Stance in Twitter Conversations
Jun 27, 2020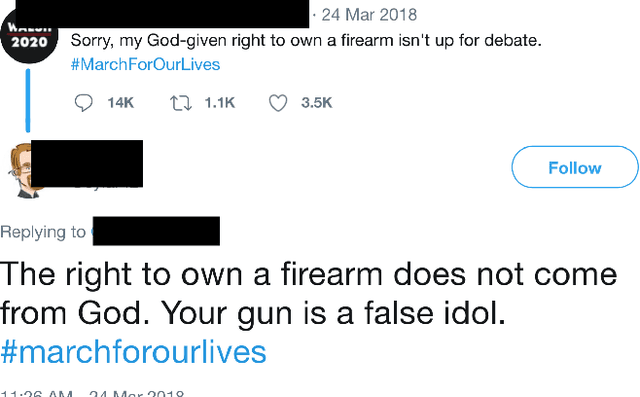
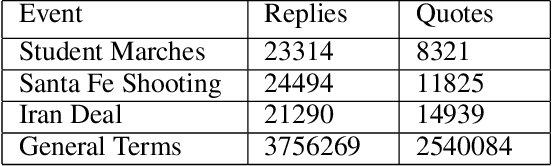
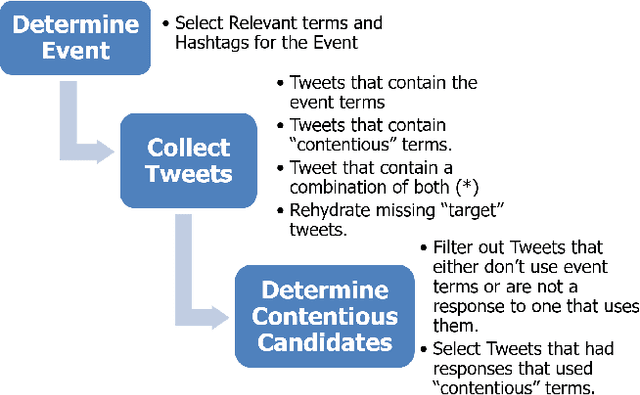
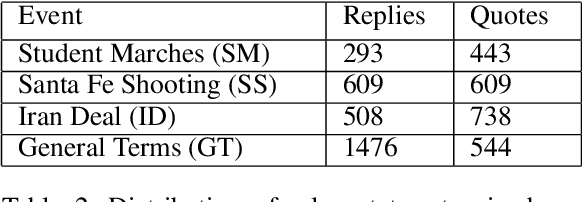
Automated ways to extract stance (denying vs. supporting opinions) from conversations on social media are essential to advance opinion mining research. Recently, there is a renewed excitement in the field as we see new models attempting to improve the state-of-the-art. However, for training and evaluating the models, the datasets used are often small. Additionally, these small datasets have uneven class distributions, i.e., only a tiny fraction of the examples in the dataset have favoring or denying stances, and most other examples have no clear stance. Moreover, the existing datasets do not distinguish between the different types of conversations on social media (e.g., replying vs. quoting on Twitter). Because of this, models trained on one event do not generalize to other events. In the presented work, we create a new dataset by labeling stance in responses to posts on Twitter (both replies and quotes) on controversial issues. To the best of our knowledge, this is currently the largest human-labeled stance dataset for Twitter conversations with over 5200 stance labels. More importantly, we designed a tweet collection methodology that favors the selection of denial-type responses. This class is expected to be more useful in the identification of rumors and determining antagonistic relationships between users. Moreover, we include many baseline models for learning the stance in conversations and compare the performance of various models. We show that combining data from replies and quotes decreases the accuracy of models indicating that the two modalities behave differently when it comes to stance learning.
A Computational Analysis of Polarization on Indian and Pakistani Social Media
May 20, 2020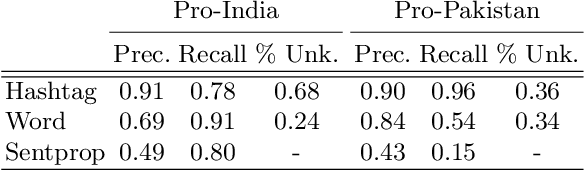
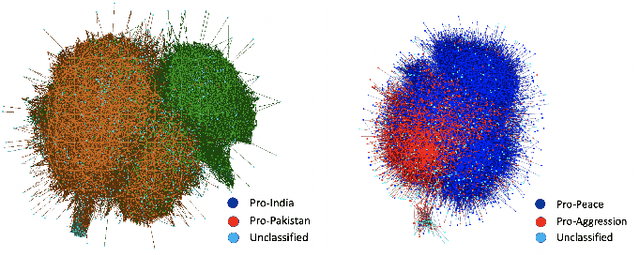
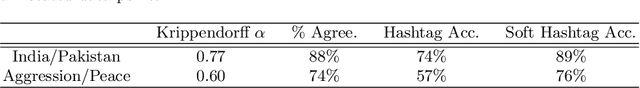
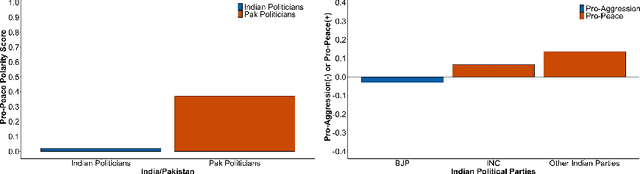
Between February 14, 2019 and March 4, 2019, a terrorist attack in Pulwama, Kashmir followed by retaliatory air strikes led to rising tensions between India and Pakistan, two nuclear-armed countries. In this work, we examine polarizing messaging on Twitter during these events, particularly focusing on the positions of Indian and Pakistani politicians. We use label propagation technique focused on hashtag cooccurences to find polarizing tweets and users. Our analysis reveals that politicians in the ruling political party in India (BJP) used polarized hashtags and called for escalation of conflict more so than politicians from other parties. Our work offers the first analysis of how escalating tensions between India and Pakistan manifest on Twitter and provides a framework for studying polarizing messages.
Discover Your Social Identity from What You Tweet: a Content Based Approach
Mar 03, 2020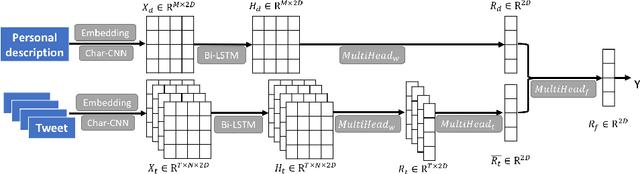


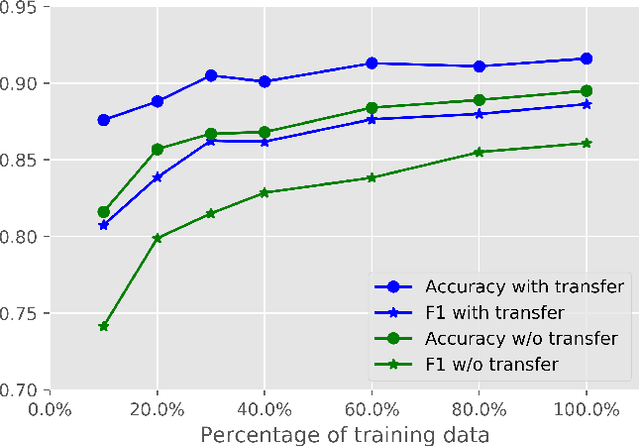
An identity denotes the role an individual or a group plays in highly differentiated contemporary societies. In this paper, our goal is to classify Twitter users based on their role identities. We first collect a coarse-grained public figure dataset automatically, then manually label a more fine-grained identity dataset. We propose a hierarchical self-attention neural network for Twitter user role identity classification. Our experiments demonstrate that the proposed model significantly outperforms multiple baselines. We further propose a transfer learning scheme that improves our model's performance by a large margin. Such transfer learning also greatly reduces the need for a large amount of human labeled data.
A Hierarchical Location Prediction Neural Network for Twitter User Geolocation
Oct 28, 2019Accurate estimation of user location is important for many online services. Previous neural network based methods largely ignore the hierarchical structure among locations. In this paper, we propose a hierarchical location prediction neural network for Twitter user geolocation. Our model first predicts the home country for a user, then uses the country result to guide the city-level prediction. In addition, we employ a character-aware word embedding layer to overcome the noisy information in tweets. With the feature fusion layer, our model can accommodate various feature combinations and achieves state-of-the-art results over three commonly used benchmarks under different feature settings. It not only improves the prediction accuracy but also greatly reduces the mean error distance.
Graph-Hist: Graph Classification from Latent Feature Histograms With Application to Bot Detection
Oct 02, 2019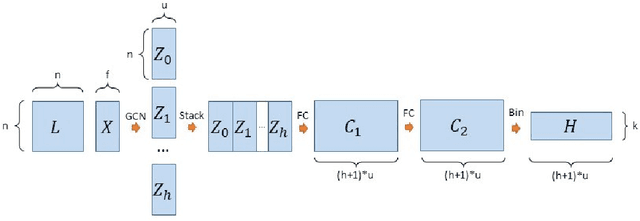

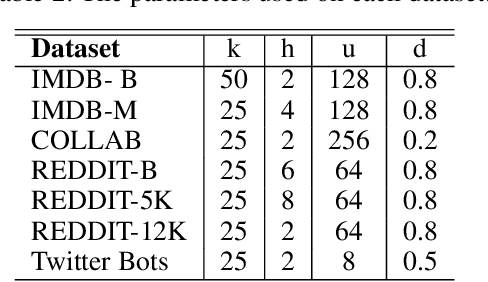
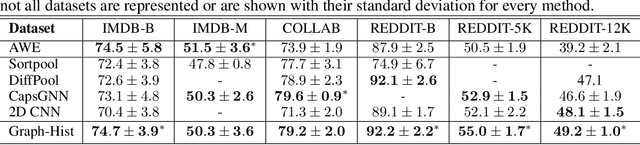
Neural networks are increasingly used for graph classification in a variety of contexts. Social media is a critical application area in this space, however the characteristics of social media graphs differ from those seen in most popular benchmark datasets. Social networks tend to be large and sparse, while benchmarks are small and dense. Classically, large and sparse networks are analyzed by studying the distribution of local properties. Inspired by this, we introduce Graph-Hist: an end-to-end architecture that extracts a graph's latent local features, bins nodes together along 1-D cross sections of the feature space, and classifies the graph based on this multi-channel histogram. We show that Graph-Hist improves state of the art performance on true social media benchmark datasets, while still performing well on other benchmarks. Finally, we demonstrate Graph-Hist's performance by conducting bot detection in social media. While sophisticated bot and cyborg accounts increasingly evade traditional detection methods, they leave artificial artifacts in their conversational graph that are detected through graph classification. We apply Graph-Hist to classify these conversational graphs. In the process, we confirm that social media graphs are different than most baselines and that Graph-Hist outperforms existing bot-detection models.
Parameterized Convolutional Neural Networks for Aspect Level Sentiment Classification
Sep 13, 2019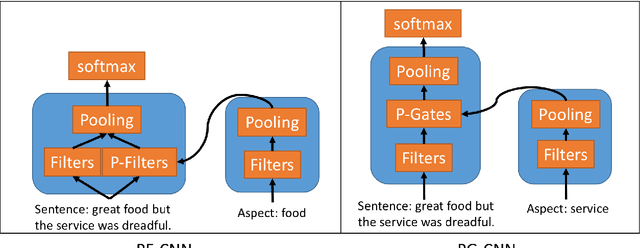
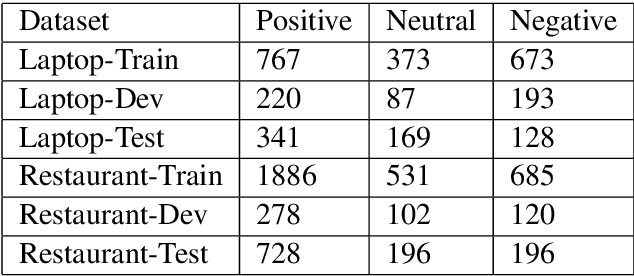
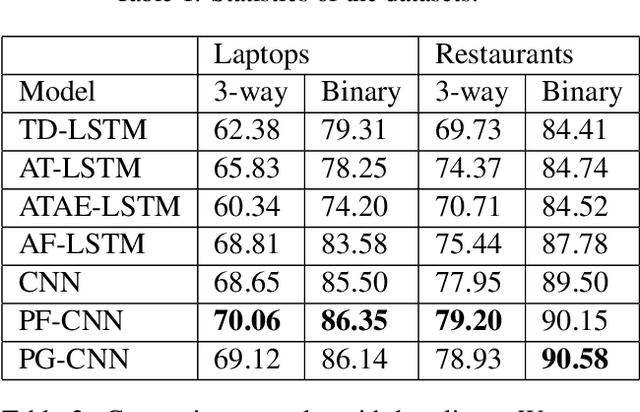
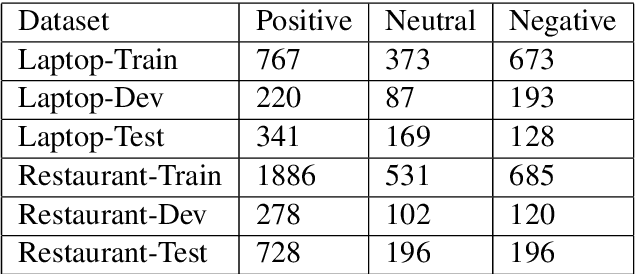
We introduce a novel parameterized convolutional neural network for aspect level sentiment classification. Using parameterized filters and parameterized gates, we incorporate aspect information into convolutional neural networks (CNN). Experiments demonstrate that our parameterized filters and parameterized gates effectively capture the aspect-specific features, and our CNN-based models achieve excellent results on SemEval 2014 datasets.
Syntax-Aware Aspect Level Sentiment Classification with Graph Attention Networks
Sep 05, 2019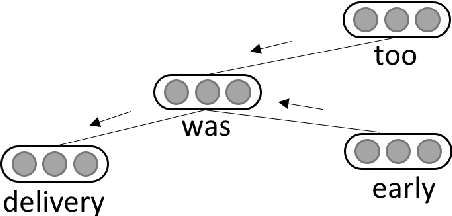
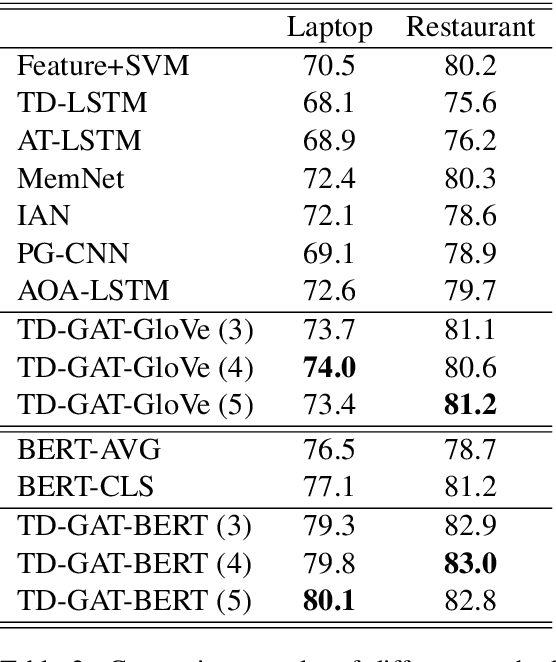
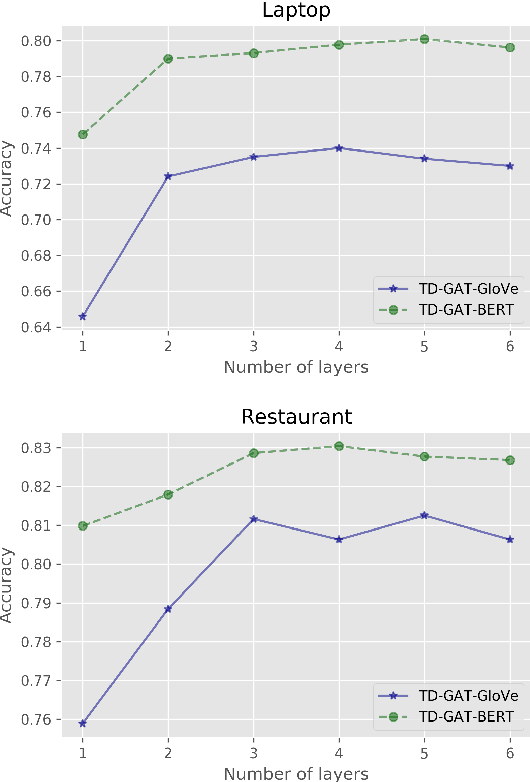
Aspect level sentiment classification aims to identify the sentiment expressed towards an aspect given a context sentence. Previous neural network based methods largely ignore the syntax structure in one sentence. In this paper, we propose a novel target-dependent graph attention network (TD-GAT) for aspect level sentiment classification, which explicitly utilizes the dependency relationship among words. Using the dependency graph, it propagates sentiment features directly from the syntactic context of an aspect target. In our experiments, we show our method outperforms multiple baselines with GloVe embeddings. We also demonstrate that using BERT representations further substantially boosts the performance.
Inductive Graph Representation Learning with Recurrent Graph Neural Networks
May 07, 2019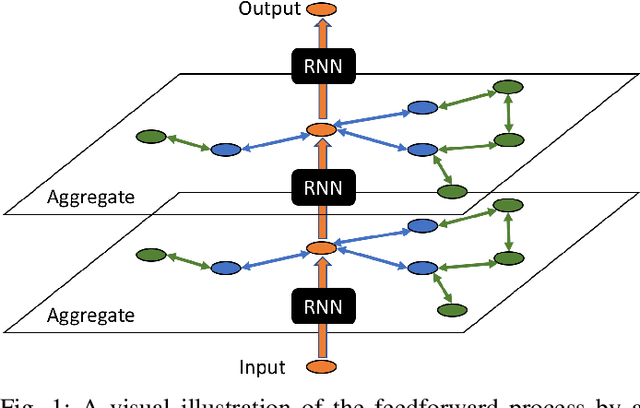
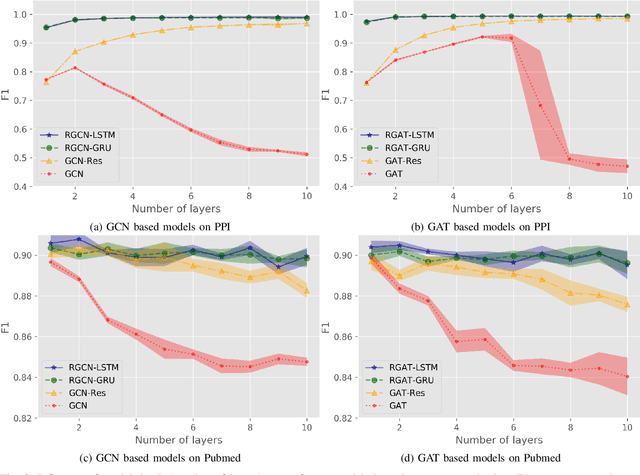
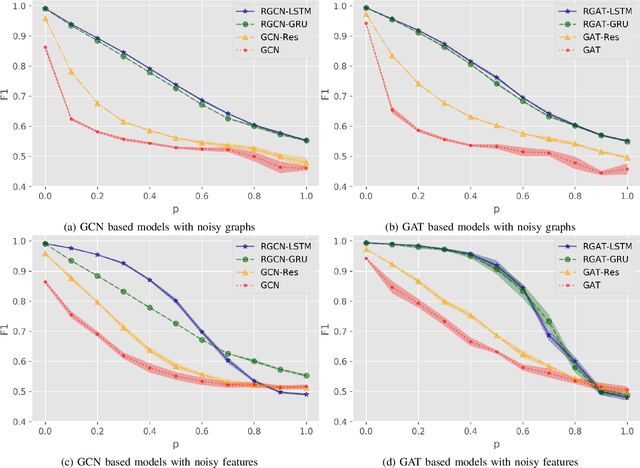
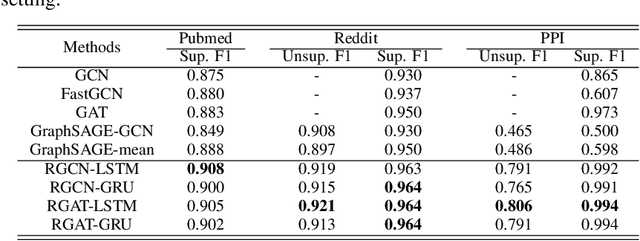
In this paper, we study the problem of node representation learning with graph neural networks. We present a graph neural network class named recurrent graph neural network (RGNN), that address the shortcomings of prior methods. By using recurrent units to capture the long-term dependency across layers, our methods can successfully identify important information during recursive neighborhood expansion. In our experiments, we show that our model class achieves state-of-the-art results on three benchmarks: the Pubmed, Reddit, and PPI network datasets. Our in-depth analyses also demonstrate that incorporating recurrent units is a simple yet effective method to prevent noisy information in graphs, which enables a deeper graph neural network.
Aspect Level Sentiment Classification with Attention-over-Attention Neural Networks
Apr 18, 2018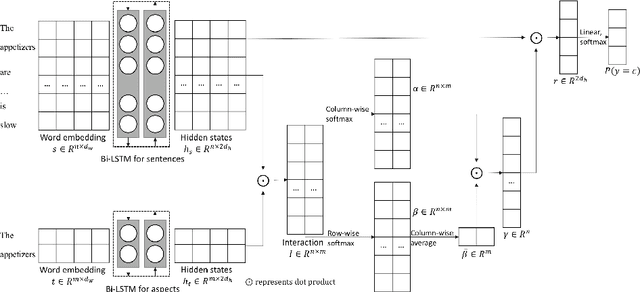


Aspect-level sentiment classification aims to identify the sentiment expressed towards some aspects given context sentences. In this paper, we introduce an attention-over-attention (AOA) neural network for aspect level sentiment classification. Our approach models aspects and sentences in a joint way and explicitly captures the interaction between aspects and context sentences. With the AOA module, our model jointly learns the representations for aspects and sentences, and automatically focuses on the important parts in sentences. Our experiments on laptop and restaurant datasets demonstrate our approach outperforms previous LSTM-based architectures.