 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explainable Regression Framework for Predicting Remaining Useful Life of Machines
Apr 30, 2022
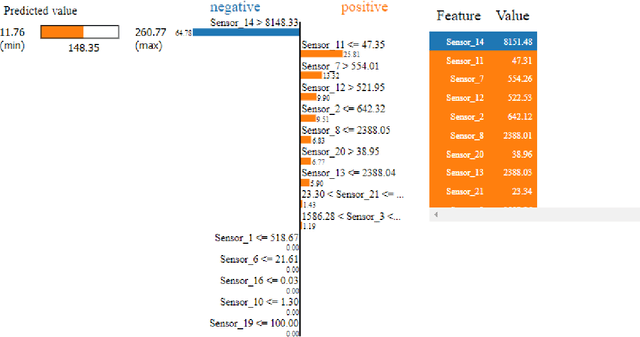

Prediction of a machine's Remaining Useful Life (RUL) is one of the key tasks in predictive maintenance. The task is treated as a regression problem where Machine Learning (ML) algorithms are used to predict the RUL of machine components. These ML algorithms are generally used as a black box with a total focus on the performance without identifying the potential causes behind the algorithms' decisions and their working mechanism. We believe, the performance (in terms of Mean Squared Error (MSE), etc.,) alone is not enough to build the trust of the stakeholders in ML prediction rather more insights on the causes behind the predictions are needed. To this aim, in this paper, we explore the potential of Explainable AI (XAI) techniques by proposing an explainable regression framework for the prediction of machines' RUL. We also evaluate several ML algorithms including classical and Neural Networks (NNs) based solutions for the task. For the explanations, we rely on two model agnostic XAI methods namely Local Interpretable Model-Agnostic Explanations (LIME) and Shapley Additive Explanations (SHAP). We believe, this work will provide a baseline for future research in the domain.
Exploration and Exploitation in Federated Learning to Exclude Clients with Poisoned Data
Apr 29, 2022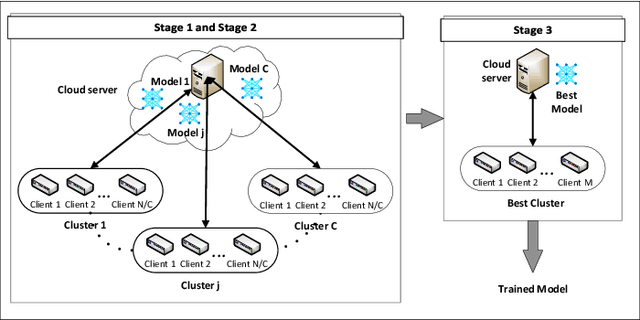
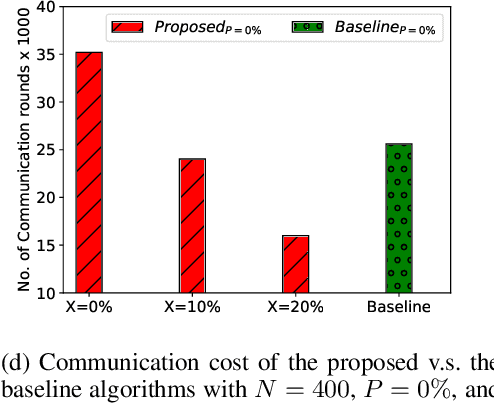
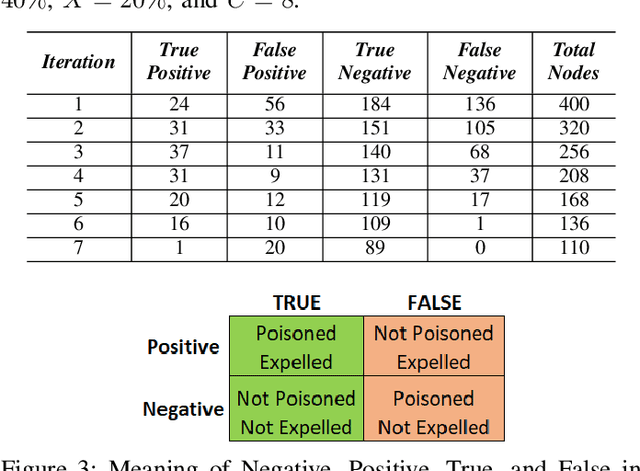
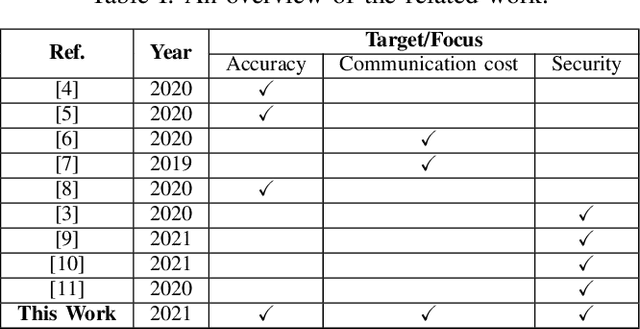
Federated Learning (FL) is one of the hot research topics, and it utilizes Machine Learning (ML) in a distributed manner without directly accessing private data on clients. However, FL faces many challenges, including the difficulty to obtain high accuracy, high communication cost between clients and the server, and security attacks related to adversarial ML. To tackle these three challenges, we propose an FL algorithm inspired by evolutionary techniques. The proposed algorithm groups clients randomly in many clusters, each with a model selected randomly to explore the performance of different models. The clusters are then trained in a repetitive process where the worst performing cluster is removed in each iteration until one cluster remains. In each iteration, some clients are expelled from clusters either due to using poisoned data or low performance. The surviving clients are exploited in the next iteration. The remaining cluster with surviving clients is then used for training the best FL model (i.e., remaining FL model). Communication cost is reduced since fewer clients are used in the final training of the FL model. To evaluate the performance of the proposed algorithm, we conduct a number of experiments using FEMNIST dataset and compare the result against the random FL algorithm. The experimental results show that the proposed algorithm outperforms the baseline algorithm in terms of accuracy, communication cost, and security.
Merit-based Fusion of NLP Techniques for Instant Feedback on Water Quality from Twitter Text
Feb 09, 2022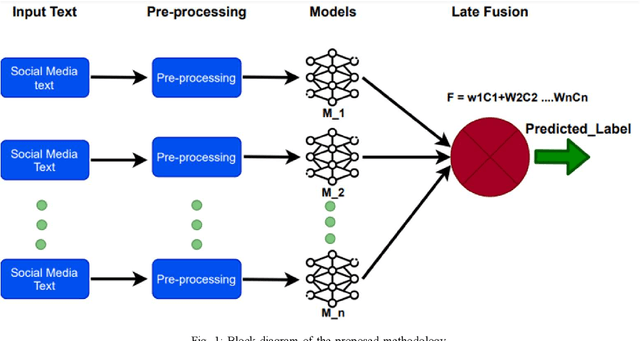

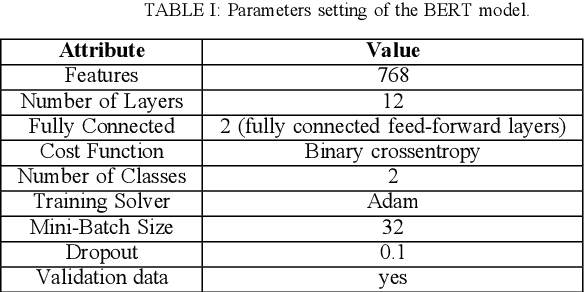
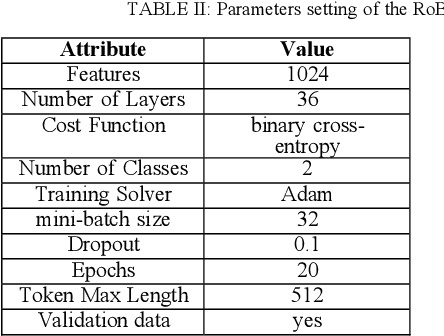
This paper focuses on an important environmental challenge; namely, water quality by analyzing the potential of social media as an immediate source of feedback. The main goal of the work is to automatically analyze and retrieve social media posts relevant to water quality with particular attention to posts describing different aspects of water quality, such as watercolor, smell, taste, and related illnesses. To this aim, we propose a novel framework incorporating different preprocessing, data augmentation, and classification techniques. In total, three different Neural Networks (NNs) architectures, namely (i) Bidirectional Encoder Representations from Transformers (BERT), (ii) Robustly Optimized BERT Pre-training Approach (XLM-RoBERTa), and (iii) custom Long short-term memory (LSTM) model, are employed in a merit-based fusion scheme. For merit-based weight assignment to the models, several optimization and search techniques are compared including a Particle Swarm Optimization (PSO), a Genetic Algorithm (GA), Brute Force (BF), Nelder-Mead, and Powell's optimization methods. We also provide an evaluation of the individual models where the highest F1-score of 0.81 is obtained with the BERT model. In merit-based fusion, overall better results are obtained with BF achieving an F1-score score of 0.852. We also provide comparison against existing methods, where a significant improvement for our proposed solutions is obtained. We believe such rigorous analysis of this relatively new topic will provide a baseline for future research.
NLP Techniques for Water Quality Analysis in Social Media Content
Nov 30, 2021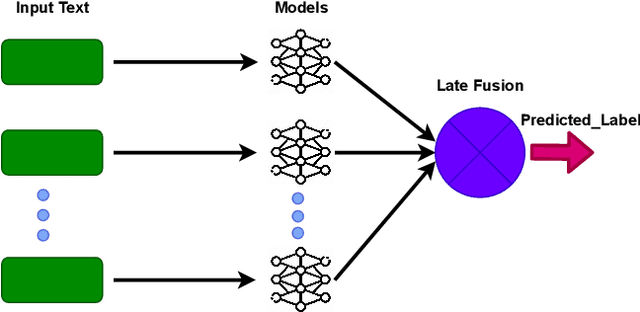
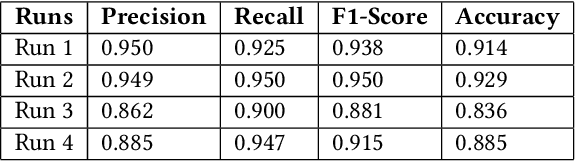
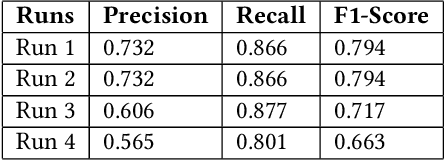
This paper presents our contributions to the MediaEval 2021 task namely "WaterMM: Water Quality in Social Multimedia". The task aims at analyzing social media posts relevant to water quality with particular focus on the aspects like watercolor, smell, taste, and related illnesses. To this aim, a multimodal dataset containing both textual and visual information along with meta-data is provided. Considering the quality and quantity of available content, we mainly focus on textual information by employing three different models individually and jointly in a late-fusion manner. These models include (i) Bidirectional Encoder Representations from Transformers (BERT), (ii) Robustly Optimized BERT Pre-training Approach (XLM-RoBERTa), and a (iii) custom Long short-term memory (LSTM) model obtaining an overall F1-score of 0.794, 0.717, 0.663 on the official test set, respectively. In the fusion scheme, all the models are treated equally and no significant improvement is observed in the performance over the best performing individual model.
Deep Models for Visual Sentiment Analysis of Disaster-related Multimedia Content
Nov 30, 2021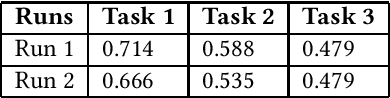
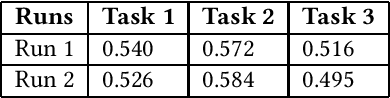
This paper presents a solutions for the MediaEval 2021 task namely "Visual Sentiment Analysis: A Natural Disaster Use-case". The task aims to extract and classify sentiments perceived by viewers and the emotional message conveyed by natural disaster-related images shared on social media. The task is composed of three sub-tasks including, one single label multi-class image classification task, and, two multi-label multi-class image classification tasks, with different sets of labels. In our proposed solutions, we rely mainly on two different state-of-the-art models namely, Inception-v3 and VggNet-19, pre-trained on ImageNet, which are fine-tuned for each of the three task using different strategies. Overall encouraging results are obtained on all the three tasks. On the single-label classification task (i.e. Task 1), we obtained the weighted average F1-scores of 0.540 and 0.526 for the Inception-v3 and VggNet-19 based solutions, respectively. On the multi-label classification i.e., Task 2 and Task 3, the weighted F1-score of our Inception-v3 based solutions was 0.572 and 0.516, respectively. Similarly, the weighted F1-score of our VggNet-19 based solution on Task 2 and Task 3 was 0.584 and 0.495, respectively.
Visual Sentiment Analysis: A Natural DisasterUse-case Task at MediaEval 2021
Nov 22, 2021The Visual Sentiment Analysis task is being offered for the first time at MediaEval. The main purpose of the task is to predict the emotional response to images of natural disasters shared on social media. Disaster-related images are generally complex and often evoke an emotional response, making them an ideal use case of visual sentiment analysis. We believe being able to perform meaningful analysis of natural disaster-related data could be of great societal importance, and a joint effort in this regard can open several interesting directions for future research. The task is composed of three sub-tasks, each aiming to explore a different aspect of the challenge. In this paper, we provide a detailed overview of the task, the general motivation of the task, and an overview of the dataset and the metrics to be used for the evaluation of the proposed solutions.
Adversarial Attacks and Defenses for Social Network Text Processing Applications: Techniques, Challenges and Future Research Directions
Oct 26, 2021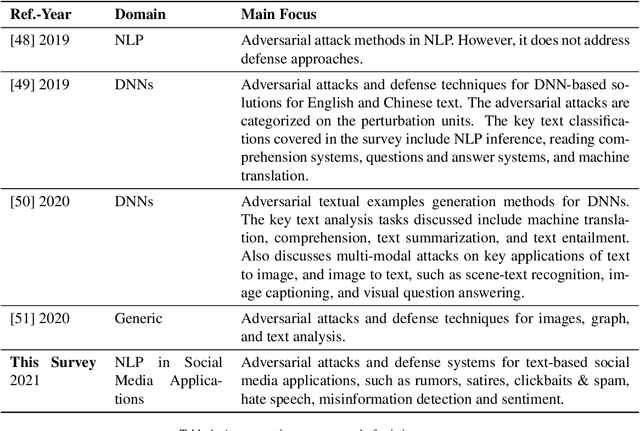
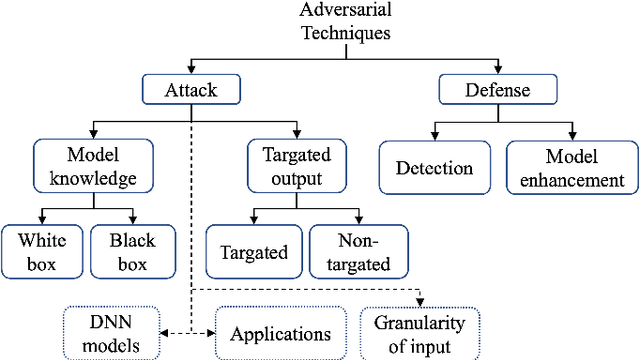
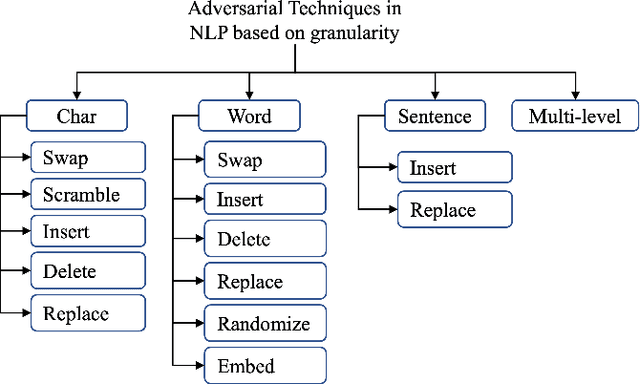

The growing use of social media has led to the development of several Machine Learning (ML) and Natural Language Processing(NLP) tools to process the unprecedented amount of social media content to make actionable decisions. However, these MLand NLP algorithms have been widely shown to be vulnerable to adversarial attacks. These vulnerabilities allow adversaries to launch a diversified set of adversarial attacks on these algorithms in different applications of social media text processing. In this paper, we provide a comprehensive review of the main approaches for adversarial attacks and defenses in the context of social media applications with a particular focus on key challenges and future research directions. In detail, we cover literature on six key applications, namely (i) rumors detection, (ii) satires detection, (iii) clickbait & spams identification, (iv) hate speech detection, (v)misinformation detection, and (vi) sentiment analysis. We then highlight the concurrent and anticipated future research questions and provide recommendations and directions for future work.
Explainable Event Recognition
Oct 10, 2021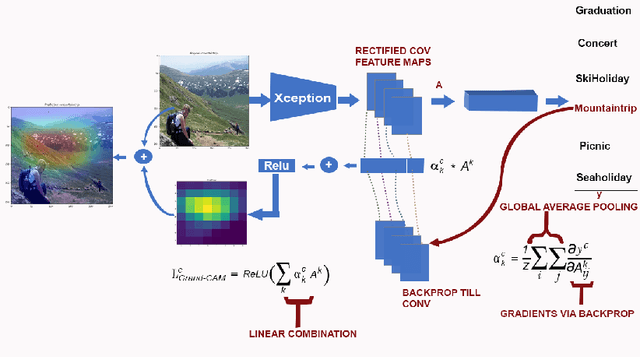
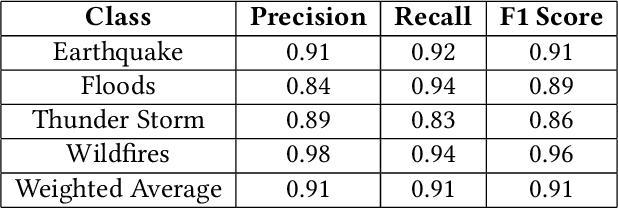

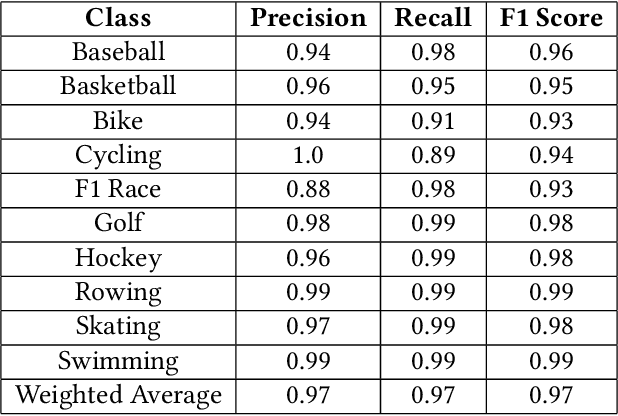
The literature shows outstanding capabilities for CNNs in event recognition in images. However, fewer attempts are made to analyze the potential causes behind the decisions of the models and exploring whether the predictions are based on event-salient objects or regions? To explore this important aspect of event recognition, in this work, we propose an explainable event recognition framework relying on Grad-CAM and an Xception architecture-based CNN model. Experiments are conducted on three large-scale datasets covering a diversified set of natural disasters, social, and sports events. Overall, the model showed outstanding generalization capabilities obtaining overall F1-scores of 0.91, 0.94, and 0.97 on natural disasters, social, and sports events, respectively. Moreover, for subjective analysis of activation maps generated through Grad-CAM for the predicted samples of the model, a crowdsourcing study is conducted to analyze whether the model's predictions are based on event-related objects/regions or not? The results of the study indicate that 78%, 84%, and 78% of the model decisions on natural disasters, sports, and social events datasets, respectively, are based onevent-related objects or regions.
Artificial Intelligence Based Prognostic Maintenance of Renewable Energy Systems: A Review of Techniques, Challenges, and Future Research Directions
Apr 20, 2021
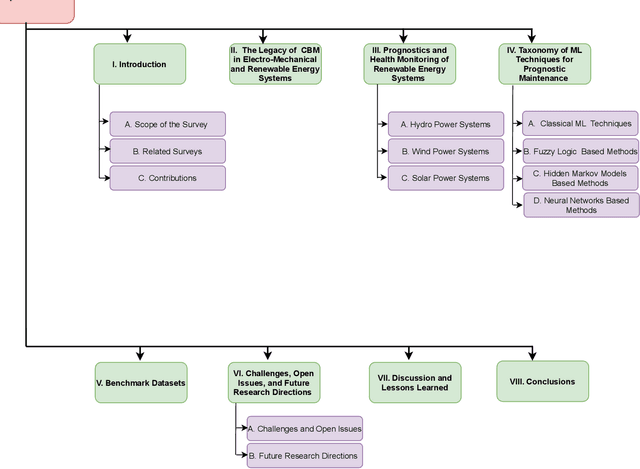
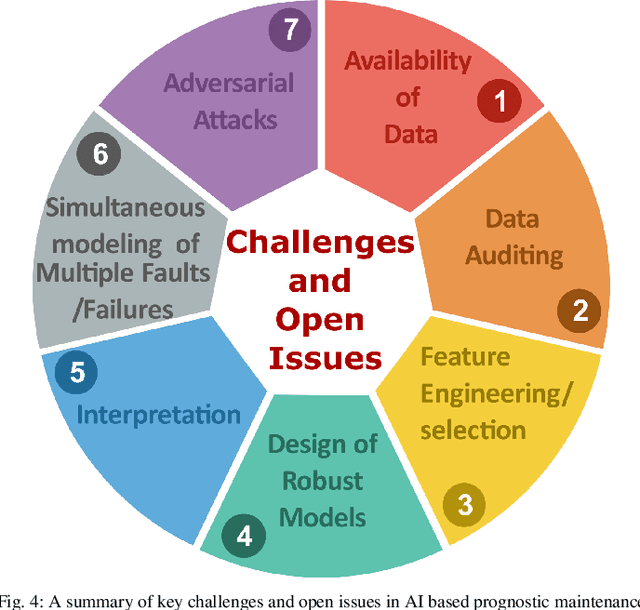
Since the depletion of fossil fuels, the world has started to rely heavily on renewable sources of energy. With every passing year, our dependency on the renewable sources of energy is increasing exponentially. As a result, complex and hybrid generation systems are being designed and developed to meet the energy demands and ensure energy security in a country. The continual improvement in the technology and an effort towards the provision of uninterrupted power to the end-users is strongly dependent on an effective and fault resilient Operation and Maintenance (O&M) system. Ingenious algorithms and techniques are hence been introduced aiming to minimize equipment and plant downtime. Efforts are being made to develop robust Prognostic Maintenance systems that can identify the faults before they occur. To this aim, complex Data Analytics and Machine Learning (ML) techniques are being used to increase the overall efficiency of these prognostic maintenance systems. This paper provides an overview of the predictive/prognostic maintenance frameworks reported in the literature. We pay a particular focus to the approaches, challenges including data-related issues, such as the availability and quality of the data and data auditing, feature engineering, interpretability, and security issues. Being a key aspect of ML-based solutions, we also discuss some of the commonly used publicly available datasets in the domain. The paper also identifies key future research directions. We believe such detailed analysis will provide a baseline for future research in the domain.
The Duo of Artificial Intelligence and Big Data for Industry 4.0: Review of Applications, Techniques, Challenges, and Future Research Directions
Apr 07, 2021
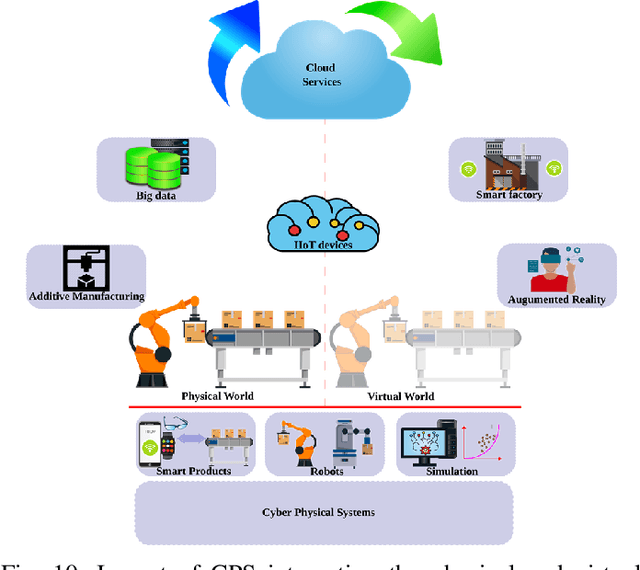
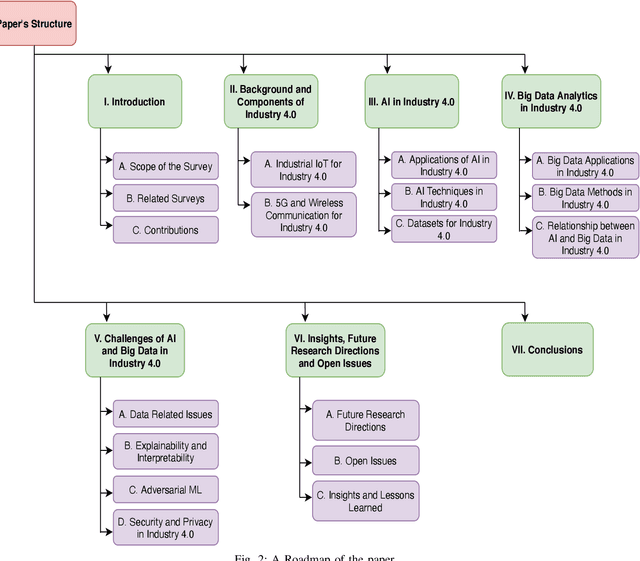
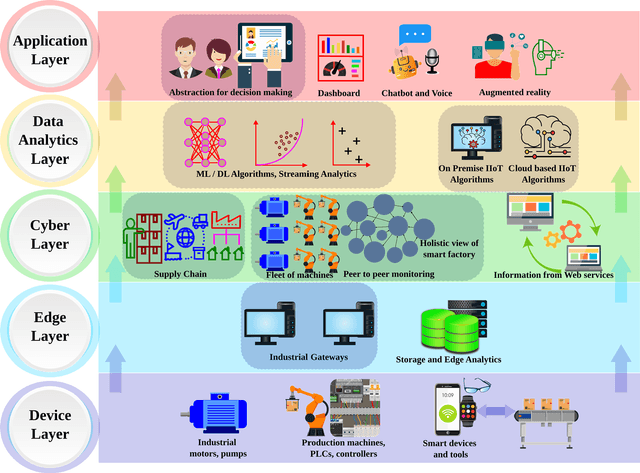
The increasing need for economic, safe, and sustainable smart manufacturing combined with novel technological enablers, has paved the way for Artificial Intelligence (AI) and Big Data in support of smart manufacturing. This implies a substantial integration of AI, Industrial Internet of Things (IIoT), Robotics, Big data, Blockchain, 5G communications, in support of smart manufacturing and the dynamical processes in modern industries. In this paper, we provide a comprehensive overview of different aspects of AI and Big Data in Industry 4.0 with a particular focus on key applications, techniques, the concepts involved, key enabling technologies, challenges, and research perspective towards deployment of Industry 5.0. In detail, we highlight and analyze how the duo of AI and Big Data is helping in different applications of Industry 4.0. We also highlight key challenges in a successful deployment of AI and Big Data methods in smart industries with a particular emphasis on data-related issues, such as availability, bias, auditing, management, interpretability, communication, and different adversarial attacks and security issues. In a nutshell, we have explored the significance of AI and Big data towards Industry 4.0 applications through panoramic reviews and discussions. We believe, this work will provide a baseline for future research in the domain.