 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Cross-Validation to SURE: Asymptotic Risk of Tuned Regularized Estimators
Mar 20, 2026We derive the asymptotic risk function of regularized empirical risk minimization (ERM) estimators tuned by $n$-fold cross-validation (CV). The out-of-sample prediction loss of such estimators converges in distribution to the squared-error loss (risk function) of shrinkage estimators in the normal means model, tuned by Stein's unbiased risk estimate (SURE). This risk function provides a more fine-grained picture of predictive performance than uniform bounds on worst-case regret, which are common in learning theory: it quantifies how risk varies with the true parameter. As key intermediate steps, we show that (i) $n$-fold CV converges uniformly to SURE, and (ii) while SURE typically has multiple local minima, its global minimum is generically well separated. Well-separation ensures that uniform convergence of CV to SURE translates into convergence of the tuning parameter chosen by CV to that chosen by SURE.
Optimal tests following sequential experiments
Apr 30, 2023Recent years have seen tremendous advances in the theory and application of sequential experiments. While these experiments are not always designed with hypothesis testing in mind, researchers may still be interested in performing tests after the experiment is completed. The purpose of this paper is to aid in the development of optimal tests for sequential experiments by analyzing their asymptotic properties. Our key finding is that the asymptotic power function of any test can be matched by a test in a limit experiment where a Gaussian process is observed for each treatment, and inference is made for the drifts of these processes. This result has important implications, including a powerful sufficiency result: any candidate test only needs to rely on a fixed set of statistics, regardless of the type of sequential experiment. These statistics are the number of times each treatment has been sampled by the end of the experiment, along with final value of the score (for parametric models) or efficient influence function (for non-parametric models) process for each treatment. We then characterize asymptotically optimal tests under various restrictions such as unbiasedness, \alpha-spending constraints etc. Finally, we apply our our results to three key classes of sequential experiments: costly sampling, group sequential trials, and bandit experiments, and show how optimal inference can be conducted in these scenarios.
Risk and optimal policies in bandit experiments
Dec 13, 2021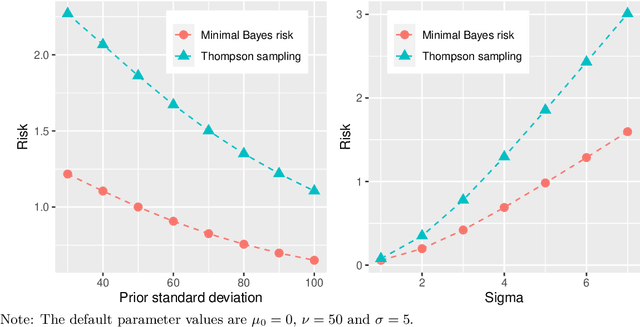
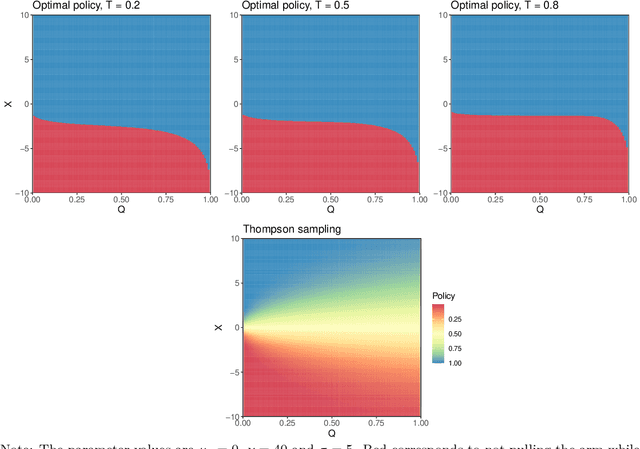
This paper provides a decision theoretic analysis of bandit experiments. The bandit setting corresponds to a dynamic programming problem, but solving this directly is typically infeasible. Working within the framework of diffusion asymptotics, we define a suitable notion of asymptotic Bayes risk for bandit settings. For normally distributed rewards, the minimal Bayes risk can be characterized as the solution to a nonlinear second-order partial differential equation (PDE). Using a limit of experiments approach, we show that this PDE characterization also holds asymptotically under both parametric and non-parametric distribution of the rewards. The approach further describes the state variables it is asymptotically sufficient to restrict attention to, and therefore suggests a practical strategy for dimension reduction. The upshot is that we can approximate the dynamic programming problem defining the bandit setting with a PDE which can be efficiently solved using sparse matrix routines. We derive near-optimal policies from the numerical solutions to these equations. The proposed policies substantially dominate existing methods such Thompson sampling. The framework also allows for substantial generalizations to the bandit problem such as time discounting and pure exploration motives.
Dynamically optimal treatment allocation using Reinforcement Learning
Apr 01, 2019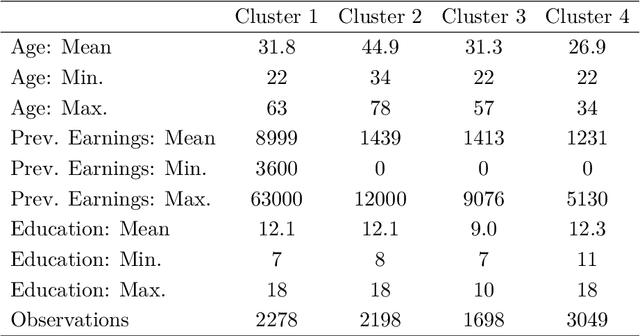

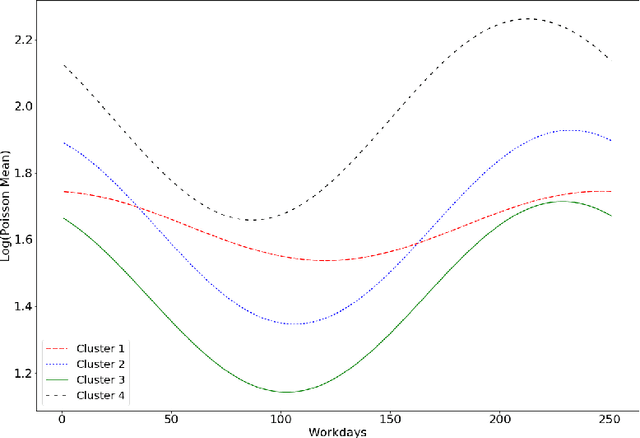

Consider a situation wherein a stream of individuals arrive sequentially - for example when they get unemployed - to a social planner. Once each individual arrives, the planner needs to decide instantaneously on an action or treatment assignment - for example offering job training - while taking into account various institutional constraints such as limited budget and capacity. In this paper, we show how one can use offline observational data to estimate an optimal policy rule that maximizes ex-ante expected welfare in this dynamic context. Importantly, we are able to find the optimal policy within a pre-specified class of policy rules. The policies may be restricted for computational, legal or incentive compatibility reasons. For each policy, we show that a Partial Differential Equation (PDE) characterizes the evolution of the value function under that policy. Using the data, one can write down a sample version of the PDE that provides estimates of these value functions. We then propose a modified Reinforcement Learning algorithm to solve for the policy rule that achieves the best value in the pre-specified class. The algorithm is easily implementable and computationally efficient, with speedups achieved through multiple reinforcement learning agents simultaneously learning the problem in parallel processes. By exploiting the properties of the PDEs, we show that the average social welfare attained by the estimated policy rule converges at a $n^{-1/2}$ rate to the maximum attainable within the specified class of policy functions; this is the same rate as that obtained in the static case. Finally we also allow for non-compliance using instrumental variables, and show how one can accommodate compliance heterogeneity in a dynamic setting.