 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting the Insider Threat with Long Short Term Memory Neural Networks
Jul 20, 2020



Information systems enable many organizational processes in every industry. The efficiencies and effectiveness in the use of information technologies create an unintended byproduct: misuse by existing users or somebody impersonating them - an insider threat. Detecting the insider threat may be possible if thorough analysis of electronic logs, capturing user behaviors, takes place. However, logs are usually very large and unstructured, posing significant challenges for organizations. In this study, we use deep learning, and most specifically Long Short Term Memory (LSTM) recurrent networks for enabling the detection. We demonstrate through a very large, anonymized dataset how LSTM uses the sequenced nature of the data for reducing the search space and making the work of a security analyst more effective.
Serverless on FHIR: Deploying machine learning models for healthcare on the cloud
Jun 08, 2020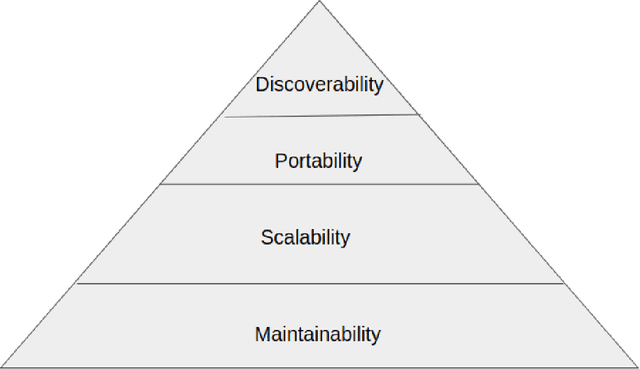
Machine Learning (ML) plays a vital role in implementing digital health. The advances in hardware and the democratization of software tools have revolutionized machine learning. However, the deployment of ML models -- the mathematical representation of the task to be performed -- for effective and efficient clinical decision support at the point of care is still a challenge. ML models undergo constant improvement of their accuracy and predictive power with a high turnover rate. Updating models consumed by downstream health information systems is essential for patient safety. We introduce a functional taxonomy and a four-tier architecture for cloud-based model deployment for digital health. The four tiers are containerized microservices for maintainability, serverless architecture for scalability, function as a service for portability and FHIR schema for discoverability. We call this architecture Serverless on FHIR and propose this as a standard to deploy digital health applications that can be consumed by downstream systems such as EMRs and visualization tools.
QRMine: A python package for triangulation in Grounded Theory
Mar 30, 2020Grounded theory (GT) is a qualitative research method for building theory grounded in data. GT uses textual and numeric data and follows various stages of coding or tagging data for sense-making, such as open coding and selective coding. Machine Learning (ML) techniques, including natural language processing (NLP), can assist the researchers in the coding process. Triangulation is the process of combining various types of data. ML can facilitate deriving insights from numerical data for corroborating findings from the textual interview transcripts. We present an open-source python package (QRMine) that encapsulates various ML and NLP libraries to support coding and triangulation in GT. QRMine enables researchers to use these methods on their data with minimal effort. Researchers can install QRMine from the python package index (PyPI) and can contribute to its development. We believe that the concept of computational triangulation will make GT relevant in the realm of big data.