 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHate Speech Detection in Roman Urdu
Aug 05, 2021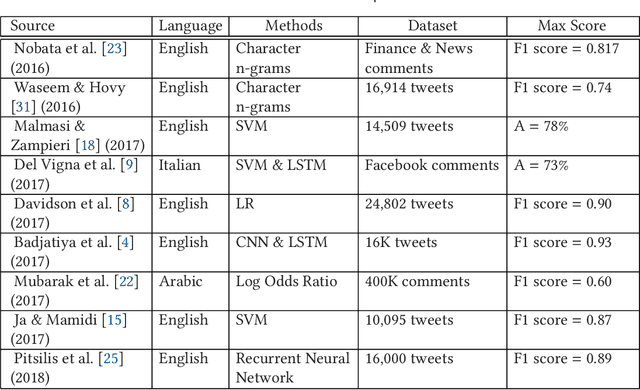
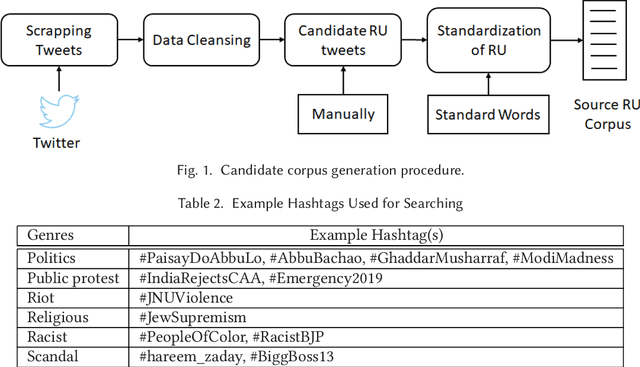
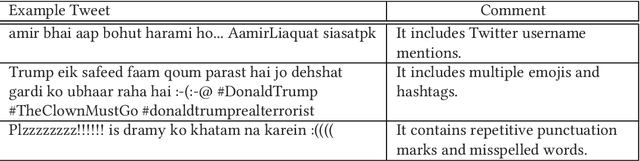
Hate speech is a specific type of controversial content that is widely legislated as a crime that must be identified and blocked. However, due to the sheer volume and velocity of the Twitter data stream, hate speech detection cannot be performed manually. To address this issue, several studies have been conducted for hate speech detection in European languages, whereas little attention has been paid to low-resource South Asian languages, making the social media vulnerable for millions of users. In particular, to the best of our knowledge, no study has been conducted for hate speech detection in Roman Urdu text, which is widely used in the sub-continent. In this study, we have scrapped more than 90,000 tweets and manually parsed them to identify 5,000 Roman Urdu tweets. Subsequently, we have employed an iterative approach to develop guidelines and used them for generating the Hate Speech Roman Urdu 2020 corpus. The tweets in the this corpus are classified at three levels: Neutral-Hostile, Simple-Complex, and Offensive-Hate speech. As another contribution, we have used five supervised learning techniques, including a deep learning technique, to evaluate and compare their effectiveness for hate speech detection. The results show that Logistic Regression outperformed all other techniques, including deep learning techniques for the two levels of classification, by achieved an F1 score of 0.906 for distinguishing between Neutral-Hostile tweets, and 0.756 for distinguishing between Offensive-Hate speech tweets.
* This is a pre-print of a contribution published in ACM Transactions on Asian and Low-Resource Language Information Processing. The final version is available online at the given journal link
Sentiment Classification of Customer Reviews about Automobiles in Roman Urdu
Dec 30, 2018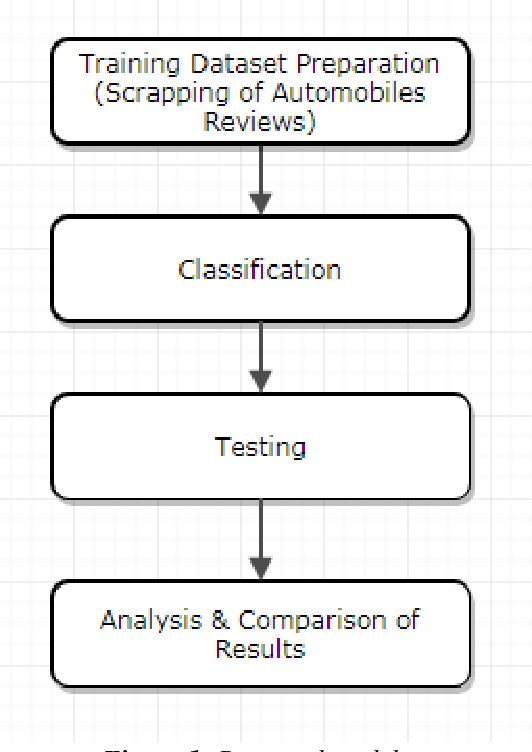
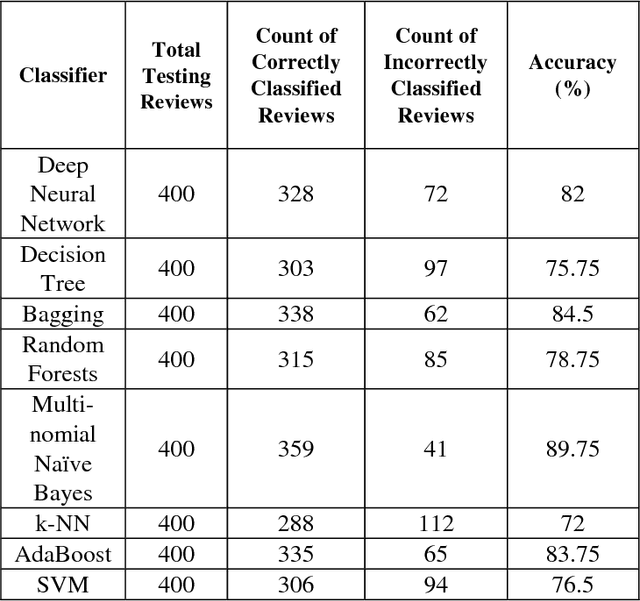
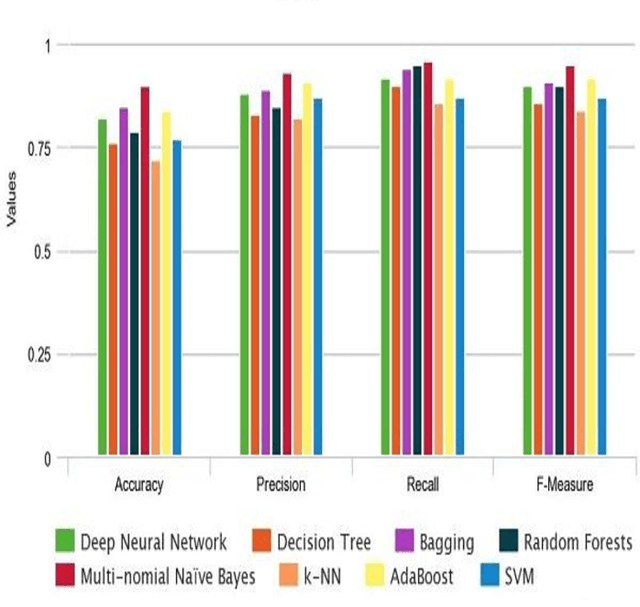
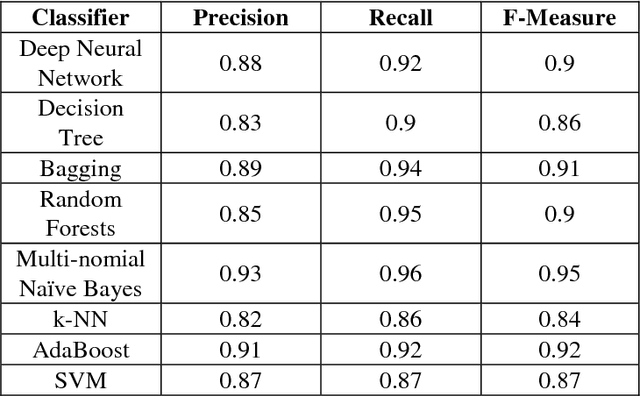
Text mining is a broad field having sentiment mining as its important constituent in which we try to deduce the behavior of people towards a specific item, merchandise, politics, sports, social media comments, review sites etc. Out of many issues in sentiment mining, analysis and classification, one major issue is that the reviews and comments can be in different languages like English, Arabic, Urdu etc. Handling each language according to its rules is a difficult task. A lot of research work has been done in English Language for sentiment analysis and classification but limited sentiment analysis work is being carried out on other regional languages like Arabic, Urdu and Hindi. In this paper, Waikato Environment for Knowledge Analysis (WEKA) is used as a platform to execute different classification models for text classification of Roman Urdu text. Reviews dataset has been scrapped from different automobiles sites. These extracted Roman Urdu reviews, containing 1000 positive and 1000 negative reviews, are then saved in WEKA attribute-relation file format (arff) as labeled examples. Training is done on 80% of this data and rest of it is used for testing purpose which is done using different models and results are analyzed in each case. The results show that Multinomial Naive Bayes outperformed Bagging, Deep Neural Network, Decision Tree, Random Forest, AdaBoost, k-NN and SVM Classifiers in terms of more accuracy, precision, recall and F-measure.
* This is a pre-print of a contribution published in Advances in Intelligent Systems and Computing (editors: Kohei Arai, Supriya Kapoor and Rahul Bhatia) published by Springer, Cham. The final authenticated version is available online at: https://doi.org/10.1007/978-3-030-03405-4_44