 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashionM3: Multimodal, Multitask, and Multiround Fashion Assistant based on Unified Vision-Language Model
Apr 24, 2025Fashion styling and personalized recommendations are pivotal in modern retail, contributing substantial economic value in the fashion industry. With the advent of vision-language models (VLM), new opportunities have emerged to enhance retailing through natural language and visual interactions. This work proposes FashionM3, a multimodal, multitask, and multiround fashion assistant, built upon a VLM fine-tuned for fashion-specific tasks. It helps users discover satisfying outfits by offering multiple capabilities including personalized recommendation, alternative suggestion, product image generation, and virtual try-on simulation. Fine-tuned on the novel FashionRec dataset, comprising 331,124 multimodal dialogue samples across basic, personalized, and alternative recommendation tasks, FashionM3 delivers contextually personalized suggestions with iterative refinement through multiround interactions. Quantitative and qualitative evaluations, alongside user studies, demonstrate FashionM3's superior performance in recommendation effectiveness and practical value as a fashion assistant.
Dress Well via Fashion Cognitive Learning
Aug 01, 2022
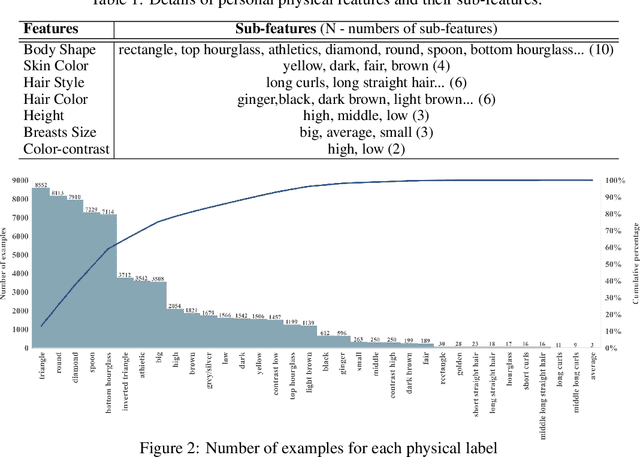
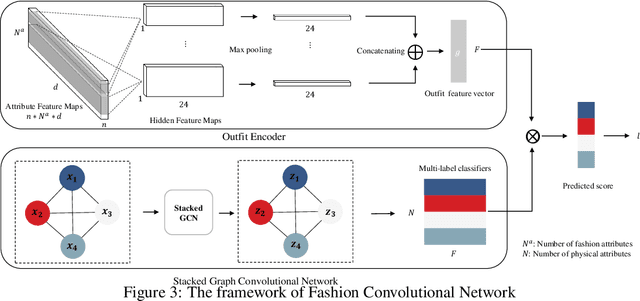
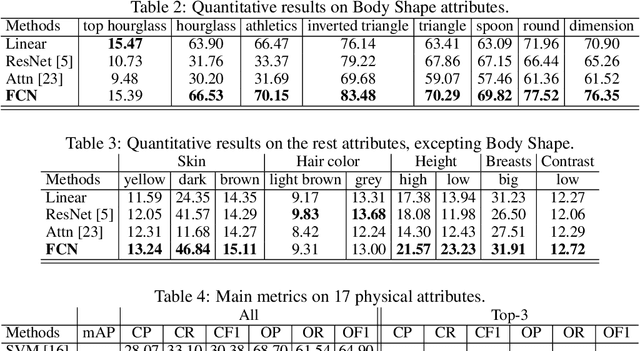
Fashion compatibility models enable online retailers to easily obtain a large number of outfit compositions with good quality. However, effective fashion recommendation demands precise service for each customer with a deeper cognition of fashion. In this paper, we conduct the first study on fashion cognitive learning, which is fashion recommendations conditioned on personal physical information. To this end, we propose a Fashion Cognitive Network (FCN) to learn the relationships among visual-semantic embedding of outfit composition and appearance features of individuals. FCN contains two submodules, namely outfit encoder and Multi-label Graph Neural Network (ML-GCN). The outfit encoder uses a convolutional layer to encode an outfit into an outfit embedding. The latter module learns label classifiers via stacked GCN. We conducted extensive experiments on the newly collected O4U dataset, and the results provide strong qualitative and quantitative evidence that our framework outperforms alternative methods.