 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObservation of high-energy neutrinos from the Galactic plane
Jul 10, 2023The origin of high-energy cosmic rays, atomic nuclei that continuously impact Earth's atmosphere, has been a mystery for over a century. Due to deflection in interstellar magnetic fields, cosmic rays from the Milky Way arrive at Earth from random directions. However, near their sources and during propagation, cosmic rays interact with matter and produce high-energy neutrinos. We search for neutrino emission using machine learning techniques applied to ten years of data from the IceCube Neutrino Observatory. We identify neutrino emission from the Galactic plane at the 4.5$\sigma$ level of significance, by comparing diffuse emission models to a background-only hypothesis. The signal is consistent with modeled diffuse emission from the Galactic plane, but could also arise from a population of unresolved point sources.
* Submitted on May 12th, 2022; Accepted on May 4th, 2023
Graph Neural Networks for Low-Energy Event Classification & Reconstruction in IceCube
Sep 07, 2022IceCube, a cubic-kilometer array of optical sensors built to detect atmospheric and astrophysical neutrinos between 1 GeV and 1 PeV, is deployed 1.45 km to 2.45 km below the surface of the ice sheet at the South Pole. The classification and reconstruction of events from the in-ice detectors play a central role in the analysis of data from IceCube. Reconstructing and classifying events is a challenge due to the irregular detector geometry, inhomogeneous scattering and absorption of light in the ice and, below 100 GeV, the relatively low number of signal photons produced per event. To address this challenge, it is possible to represent IceCube events as point cloud graphs and use a Graph Neural Network (GNN) as the classification and reconstruction method. The GNN is capable of distinguishing neutrino events from cosmic-ray backgrounds, classifying different neutrino event types, and reconstructing the deposited energy, direction and interaction vertex. Based on simulation, we provide a comparison in the 1-100 GeV energy range to the current state-of-the-art maximum likelihood techniques used in current IceCube analyses, including the effects of known systematic uncertainties. For neutrino event classification, the GNN increases the signal efficiency by 18% at a fixed false positive rate (FPR), compared to current IceCube methods. Alternatively, the GNN offers a reduction of the FPR by over a factor 8 (to below half a percent) at a fixed signal efficiency. For the reconstruction of energy, direction, and interaction vertex, the resolution improves by an average of 13%-20% compared to current maximum likelihood techniques in the energy range of 1-30 GeV. The GNN, when run on a GPU, is capable of processing IceCube events at a rate nearly double of the median IceCube trigger rate of 2.7 kHz, which opens the possibility of using low energy neutrinos in online searches for transient events.
Do-AIQ: A Design-of-Experiment Approach to Quality Evaluation of AI Mislabel Detection Algorithm
Aug 21, 2022
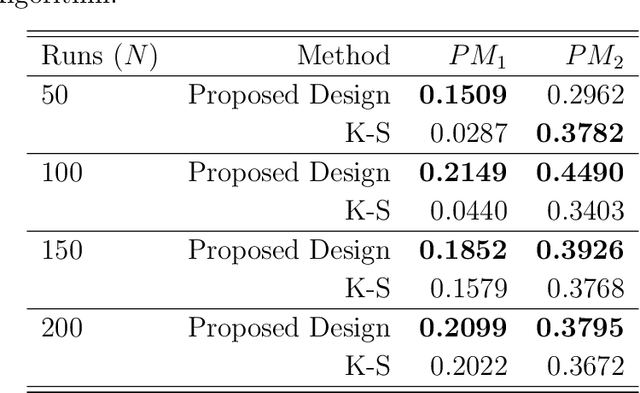


The quality of Artificial Intelligence (AI) algorithms is of significant importance for confidently adopting algorithms in various applications such as cybersecurity, healthcare, and autonomous driving. This work presents a principled framework of using a design-of-experimental approach to systematically evaluate the quality of AI algorithms, named as Do-AIQ. Specifically, we focus on investigating the quality of the AI mislabel data algorithm against data poisoning. The performance of AI algorithms is affected by hyperparameters in the algorithm and data quality, particularly, data mislabeling, class imbalance, and data types. To evaluate the quality of the AI algorithms and obtain a trustworthy assessment on the quality of the algorithms, we establish a design-of-experiment framework to construct an efficient space-filling design in a high-dimensional constraint space and develop an effective surrogate model using additive Gaussian process to enable the emulation of the quality of AI algorithms. Both theoretical and numerical studies are conducted to justify the merits of the proposed framework. The proposed framework can set an exemplar for AI algorithm to enhance the AI assurance of robustness, reproducibility, and transparency.
A Comparison of Different Machine Transliteration Models
Oct 06, 2011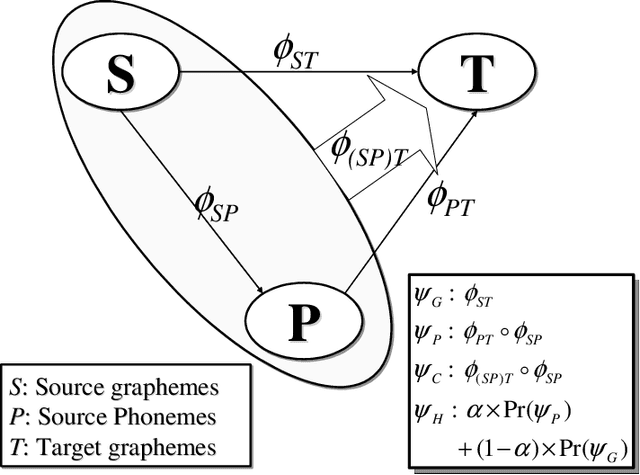


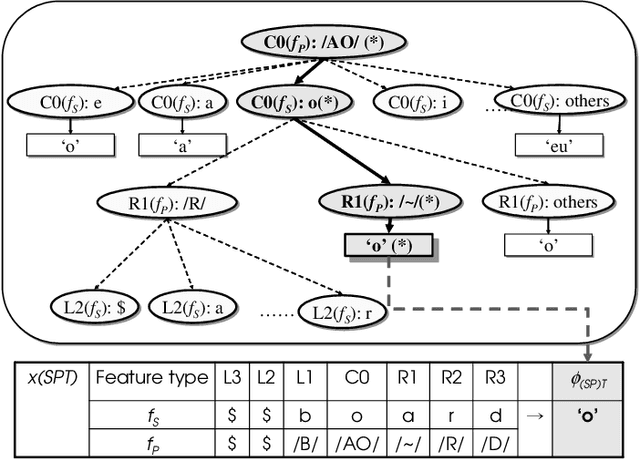
Machine transliteration is a method for automatically converting words in one language into phonetically equivalent ones in another language. Machine transliteration plays an important role in natural language applications such as information retrieval and machine translation, especially for handling proper nouns and technical terms. Four machine transliteration models -- grapheme-based transliteration model, phoneme-based transliteration model, hybrid transliteration model, and correspondence-based transliteration model -- have been proposed by several researchers. To date, however, there has been little research on a framework in which multiple transliteration models can operate simultaneously. Furthermore, there has been no comparison of the four models within the same framework and using the same data. We addressed these problems by 1) modeling the four models within the same framework, 2) comparing them under the same conditions, and 3) developing a way to improve machine transliteration through this comparison. Our comparison showed that the hybrid and correspondence-based models were the most effective and that the four models can be used in a complementary manner to improve machine transliteration performance.