 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-feature Reconstruction Network using Crossed-mask Restoration for Unsupervised Anomaly Detection
Apr 20, 2024



Unsupervised anomaly detection using only normal samples is of great significance for quality inspection in industrial manufacturing. Although existing reconstruction-based methods have achieved promising results, they still face two problems: poor distinguishable information in image reconstruction and well abnormal regeneration caused by model over-generalization ability. To overcome the above issues, we convert the image reconstruction into a combination of parallel feature restorations and propose a multi-feature reconstruction network, MFRNet, using crossed-mask restoration in this paper. Specifically, a multi-scale feature aggregator is first developed to generate more discriminative hierarchical representations of the input images from a pre-trained model. Subsequently, a crossed-mask generator is adopted to randomly cover the extracted feature map, followed by a restoration network based on the transformer structure for high-quality repair of the missing regions. Finally, a hybrid loss is equipped to guide model training and anomaly estimation, which gives consideration to both the pixel and structural similarity. Extensive experiments show that our method is highly competitive with or significantly outperforms other state-of-the-arts on four public available datasets and one self-made dataset.
Defect Transformer: An Efficient Hybrid Transformer Architecture for Surface Defect Detection
Jul 17, 2022
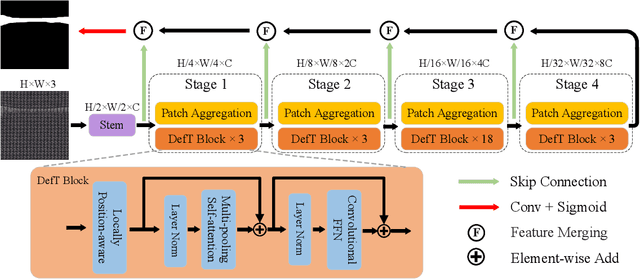
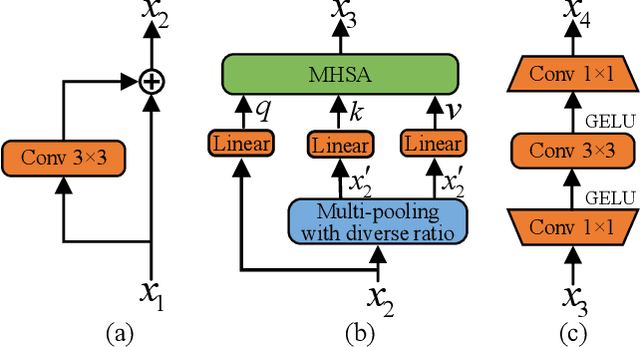
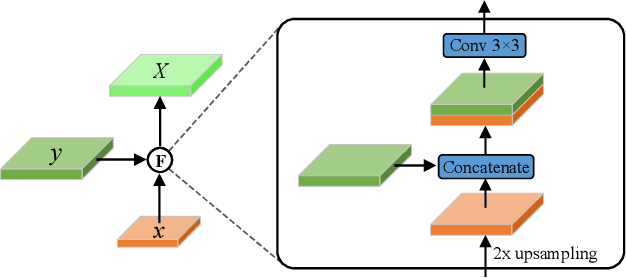
Surface defect detection is an extremely crucial step to ensure the quality of industrial products. Nowadays, convolutional neural networks (CNNs) based on encoder-decoder architecture have achieved tremendous success in various defect detection tasks. However, due to the intrinsic locality of convolution, they commonly exhibit a limitation in explicitly modeling long-range interactions, critical for pixel-wise defect detection in complex cases, e.g., cluttered background and illegible pseudo-defects. Recent transformers are especially skilled at learning global image dependencies but with limited local structural information necessary for detailed defect location. To overcome the above limitations, we propose an efficient hybrid transformer architecture, termed Defect Transformer (DefT), for surface defect detection, which incorporates CNN and transformer into a unified model to capture local and non-local relationships collaboratively. Specifically, in the encoder module, a convolutional stem block is firstly adopted to retain more detailed spatial information. Then, the patch aggregation blocks are used to generate multi-scale representation with four hierarchies, each of them is followed by a series of DefT blocks, which respectively include a locally position-aware block for local position encoding, a lightweight multi-pooling self-attention to model multi-scale global contextual relationships with good computational efficiency, and a convolutional feed-forward network for feature transformation and further location information learning. Finally, a simple but effective decoder module is proposed to gradually recover spatial details from the skip connections in the encoder. Extensive experiments on three datasets demonstrate the superiority and efficiency of our method compared with other CNN- and transformer-based networks.
FedMD: Heterogenous Federated Learning via Model Distillation
Oct 08, 2019
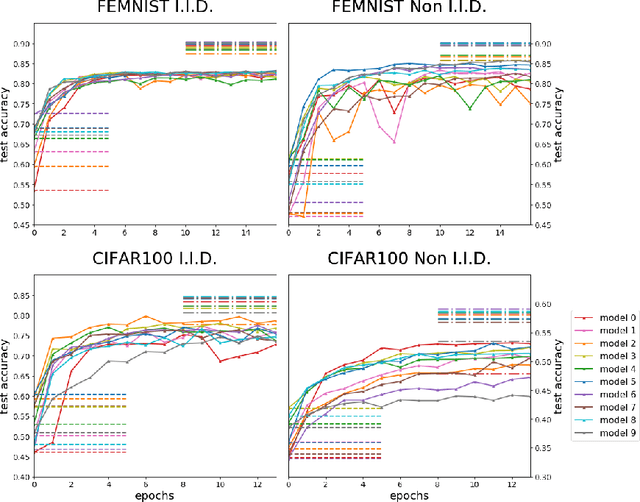
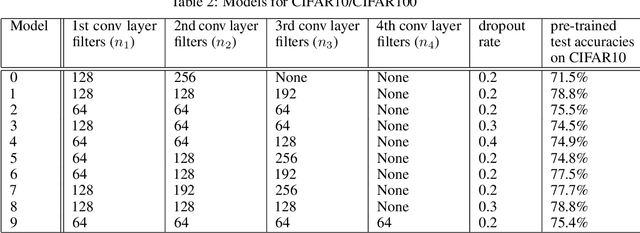
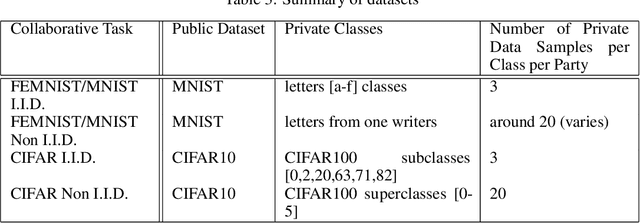
Federated learning enables the creation of a powerful centralized model without compromising data privacy of multiple participants. While successful, it does not incorporate the case where each participant independently designs its own model. Due to intellectual property concerns and heterogeneous nature of tasks and data, this is a widespread requirement in applications of federated learning to areas such as health care and AI as a service. In this work, we use transfer learning and knowledge distillation to develop a universal framework that enables federated learning when each agent owns not only their private data, but also uniquely designed models. We test our framework on the MNIST/FEMNIST dataset and the CIFAR10/CIFAR100 dataset and observe fast improvement across all participating models. With 10 distinct participants, the final test accuracy of each model on average receives a 20% gain on top of what's possible without collaboration and is only a few percent lower than the performance each model would have obtained if all private datasets were pooled and made directly available for all participants.