 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Pillar Feature Encoding Via Spatio-Temporal Virtual Grid for 3D Object Detection
Mar 11, 2024Developing high-performance, real-time architectures for LiDAR-based 3D object detectors is essential for the successful commercialization of autonomous vehicles. Pillar-based methods stand out as a practical choice for onboard deployment due to their computational efficiency. However, despite their efficiency, these methods can sometimes underperform compared to alternative point encoding techniques such as Voxel-encoding or PointNet++. We argue that current pillar-based methods have not sufficiently captured the fine-grained distributions of LiDAR points within each pillar structure. Consequently, there exists considerable room for improvement in pillar feature encoding. In this paper, we introduce a novel pillar encoding architecture referred to as Fine-Grained Pillar Feature Encoding (FG-PFE). FG-PFE utilizes Spatio-Temporal Virtual (STV) grids to capture the distribution of point clouds within each pillar across vertical, temporal, and horizontal dimensions. Through STV grids, points within each pillar are individually encoded using Vertical PFE (V-PFE), Temporal PFE (T-PFE), and Horizontal PFE (H-PFE). These encoded features are then aggregated through an Attentive Pillar Aggregation method. Our experiments conducted on the nuScenes dataset demonstrate that FG-PFE achieves significant performance improvements over baseline models such as PointPillar, CenterPoint-Pillar, and PillarNet, with only a minor increase in computational overhead.
Unified Contrastive Fusion Transformer for Multimodal Human Action Recognition
Sep 10, 2023Various types of sensors have been considered to develop human action recognition (HAR) models. Robust HAR performance can be achieved by fusing multimodal data acquired by different sensors. In this paper, we introduce a new multimodal fusion architecture, referred to as Unified Contrastive Fusion Transformer (UCFFormer) designed to integrate data with diverse distributions to enhance HAR performance. Based on the embedding features extracted from each modality, UCFFormer employs the Unified Transformer to capture the inter-dependency among embeddings in both time and modality domains. We present the Factorized Time-Modality Attention to perform self-attention efficiently for the Unified Transformer. UCFFormer also incorporates contrastive learning to reduce the discrepancy in feature distributions across various modalities, thus generating semantically aligned features for information fusion. Performance evaluation conducted on two popular datasets, UTD-MHAD and NTU RGB+D, demonstrates that UCFFormer achieves state-of-the-art performance, outperforming competing methods by considerable margins.
MGTANet: Encoding Sequential LiDAR Points Using Long Short-Term Motion-Guided Temporal Attention for 3D Object Detection
Dec 21, 2022Most scanning LiDAR sensors generate a sequence of point clouds in real-time. While conventional 3D object detectors use a set of unordered LiDAR points acquired over a fixed time interval, recent studies have revealed that substantial performance improvement can be achieved by exploiting the spatio-temporal context present in a sequence of LiDAR point sets. In this paper, we propose a novel 3D object detection architecture, which can encode LiDAR point cloud sequences acquired by multiple successive scans. The encoding process of the point cloud sequence is performed on two different time scales. We first design a short-term motion-aware voxel encoding that captures the short-term temporal changes of point clouds driven by the motion of objects in each voxel. We also propose long-term motion-guided bird's eye view (BEV) feature enhancement that adaptively aligns and aggregates the BEV feature maps obtained by the short-term voxel encoding by utilizing the dynamic motion context inferred from the sequence of the feature maps. The experiments conducted on the public nuScenes benchmark demonstrate that the proposed 3D object detector offers significant improvements in performance compared to the baseline methods and that it sets a state-of-the-art performance for certain 3D object detection categories. Code is available at https://github.com/HYjhkoh/MGTANet.git
D-Align: Dual Query Co-attention Network for 3D Object Detection Based on Multi-frame Point Cloud Sequence
Sep 30, 2022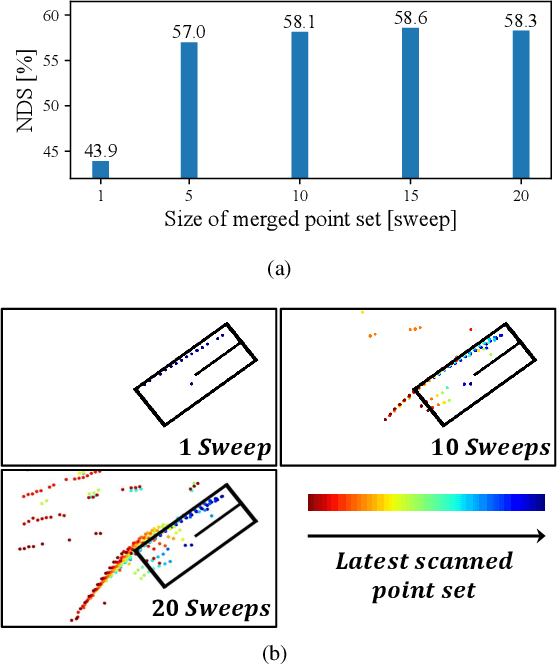
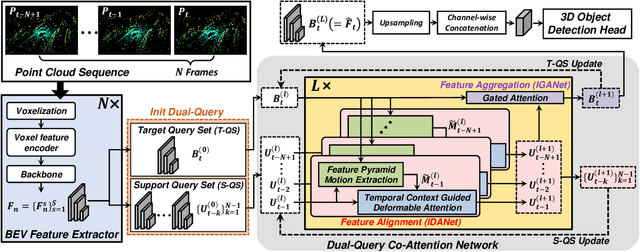
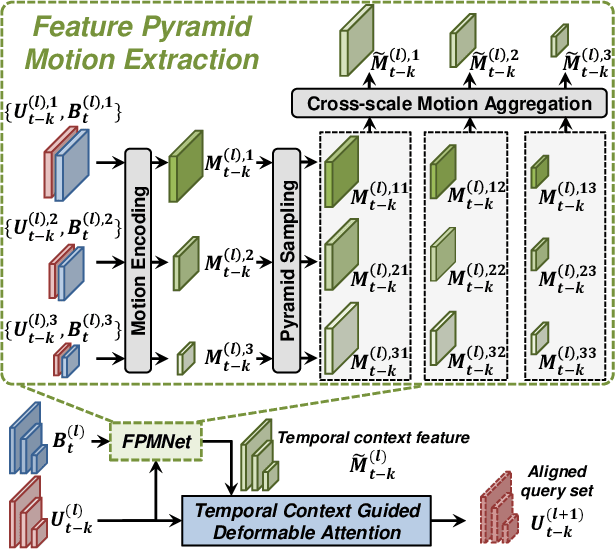
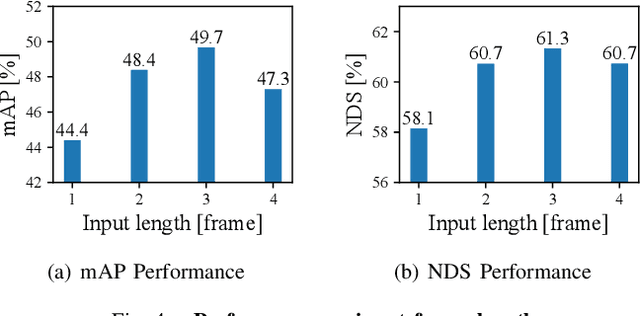
LiDAR sensors are widely used for 3D object detection in various mobile robotics applications. LiDAR sensors continuously generate point cloud data in real-time. Conventional 3D object detectors detect objects using a set of points acquired over a fixed duration. However, recent studies have shown that the performance of object detection can be further enhanced by utilizing spatio-temporal information obtained from point cloud sequences. In this paper, we propose a new 3D object detector, named D-Align, which can effectively produce strong bird's-eye-view (BEV) features by aligning and aggregating the features obtained from a sequence of point sets. The proposed method includes a novel dual-query co-attention network that uses two types of queries, including target query set (T-QS) and support query set (S-QS), to update the features of target and support frames, respectively. D-Align aligns S-QS to T-QS based on the temporal context features extracted from the adjacent feature maps and then aggregates S-QS with T-QS using a gated attention mechanism. The dual queries are updated through multiple attention layers to progressively enhance the target frame features used to produce the detection results. Our experiments on the nuScenes dataset show that the proposed D-Align method greatly improved the performance of a single frame-based baseline method and significantly outperformed the latest 3D object detectors.
Joint 3D Object Detection and Tracking Using Spatio-Temporal Representation of Camera Image and LiDAR Point Clouds
Dec 15, 2021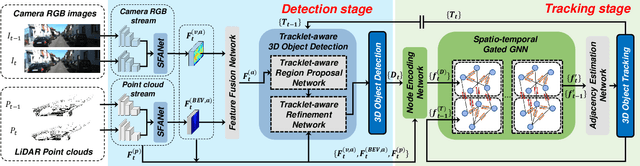

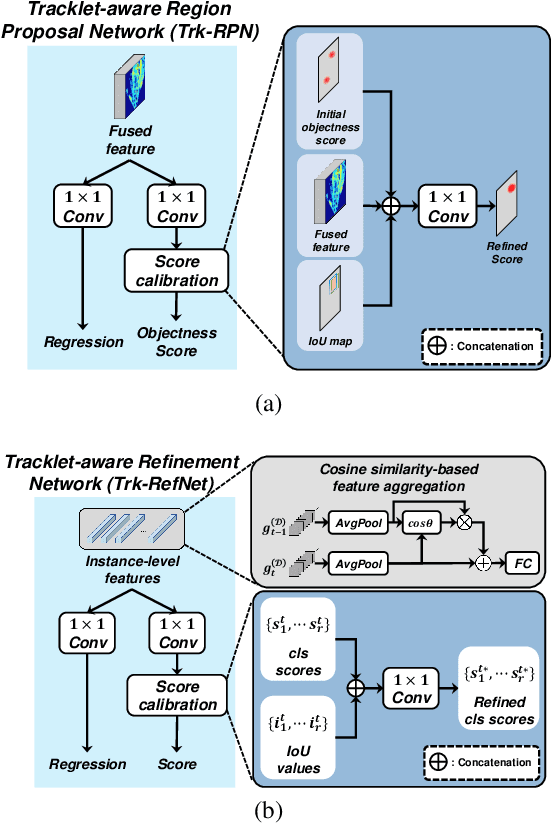

In this paper, we propose a new joint object detection and tracking (JoDT) framework for 3D object detection and tracking based on camera and LiDAR sensors. The proposed method, referred to as 3D DetecTrack, enables the detector and tracker to cooperate to generate a spatio-temporal representation of the camera and LiDAR data, with which 3D object detection and tracking are then performed. The detector constructs the spatio-temporal features via the weighted temporal aggregation of the spatial features obtained by the camera and LiDAR fusion. Then, the detector reconfigures the initial detection results using information from the tracklets maintained up to the previous time step. Based on the spatio-temporal features generated by the detector, the tracker associates the detected objects with previously tracked objects using a graph neural network (GNN). We devise a fully-connected GNN facilitated by a combination of rule-based edge pruning and attention-based edge gating, which exploits both spatial and temporal object contexts to improve tracking performance. The experiments conducted on both KITTI and nuScenes benchmarks demonstrate that the proposed 3D DetecTrack achieves significant improvements in both detection and tracking performances over baseline methods and achieves state-of-the-art performance among existing methods through collaboration between the detector and tracker.
Joint Representation of Temporal Image Sequences and Object Motion for Video Object Detection
Nov 20, 2020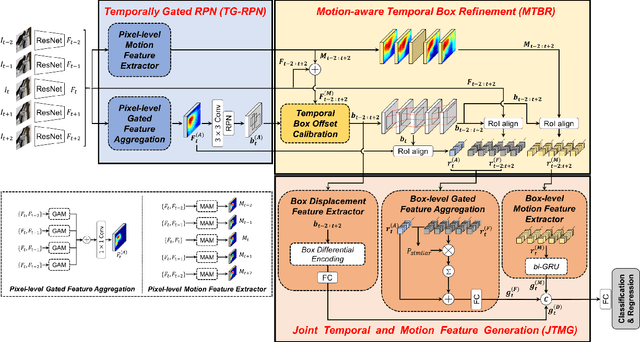
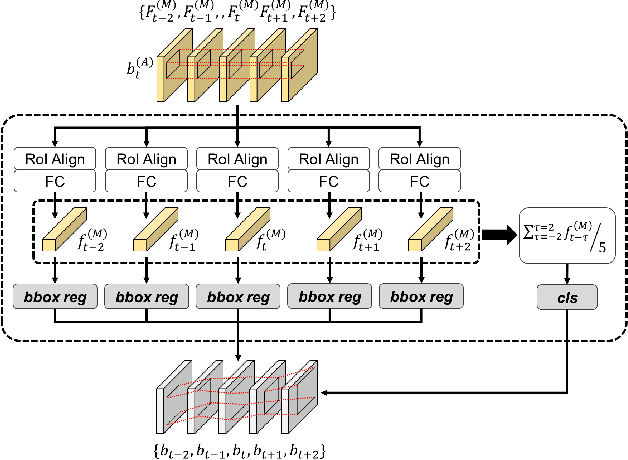
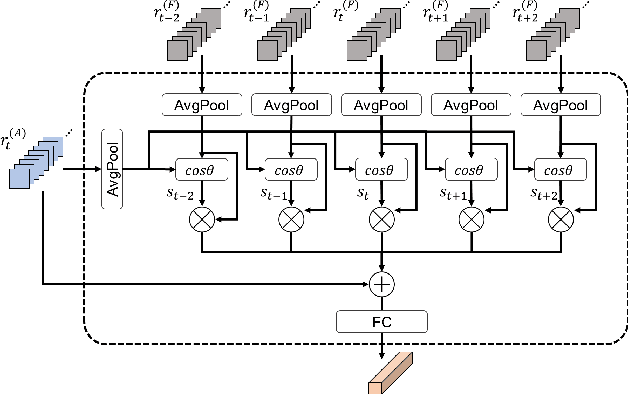

In this paper, we propose a new video object detector (VoD) method referred to as temporal feature aggregation and motion-aware VoD (TM-VoD), which produces a joint representation of temporal image sequences and object motion. The proposed TM-VoD aggregates visual feature maps extracted by convolutional neural networks applying the temporal attention gating and spatial feature alignment. This temporal feature aggregation is performed in two stages in a hierarchical fashion. In the first stage, the visual feature maps are fused at a pixel level via gated attention model. In the second stage, the proposed method aggregates the features after aligning the object features using temporal box offset calibration and weights them according to the cosine similarity measure. The proposed TM-VoD also finds the representation of the motion of objects in two successive steps. The pixel-level motion features are first computed based on the incremental changes between the adjacent visual feature maps. Then, box-level motion features are obtained from both the region of interest (RoI)-aligned pixel-level motion features and the sequential changes of the box coordinates. Finally, all these features are concatenated to produce a joint representation of the objects for VoD. The experiments conducted on the ImageNet VID dataset demonstrate that the proposed method outperforms existing VoD methods and achieves a performance comparable to that of state-of-the-art VoDs.
Robust Deep Multi-modal Learning Based on Gated Information Fusion Network
Nov 02, 2018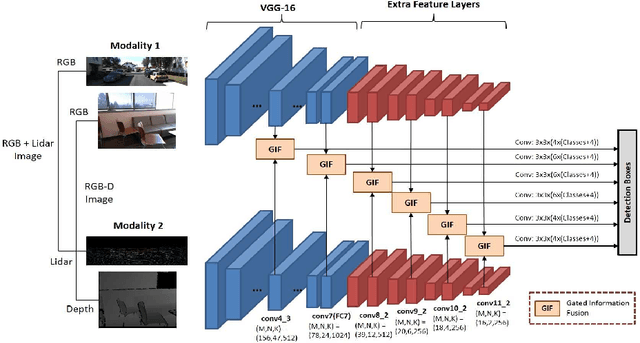

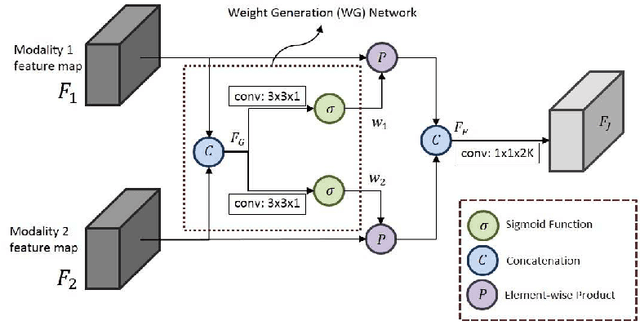

The goal of multi-modal learning is to use complimentary information on the relevant task provided by the multiple modalities to achieve reliable and robust performance. Recently, deep learning has led significant improvement in multi-modal learning by allowing for the information fusion in the intermediate feature levels. This paper addresses a problem of designing robust deep multi-modal learning architecture in the presence of imperfect modalities. We introduce deep fusion architecture for object detection which processes each modality using the separate convolutional neural network (CNN) and constructs the joint feature map by combining the intermediate features from the CNNs. In order to facilitate the robustness to the degraded modalities, we employ the gated information fusion (GIF) network which weights the contribution from each modality according to the input feature maps to be fused. The weights are determined through the convolutional layers followed by a sigmoid function and trained along with the information fusion network in an end-to-end fashion. Our experiments show that the proposed GIF network offers the additional architectural flexibility to achieve robust performance in handling some degraded modalities, and show a significant performance improvement based on Single Shot Detector (SSD) for KITTI dataset using the proposed fusion network and data augmentation schemes.