 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Stacked Autoregressive Model for Video Prediction
Mar 14, 2023



Future frame prediction has been approached through two primary methods: autoregressive and non-autoregressive. Autoregressive methods rely on the Markov assumption and can achieve high accuracy in the early stages of prediction when errors are not yet accumulated. However, their performance tends to decline as the number of time steps increases. In contrast, non-autoregressive methods can achieve relatively high performance but lack correlation between predictions for each time step. In this paper, we propose an Implicit Stacked Autoregressive Model for Video Prediction (IAM4VP), which is an implicit video prediction model that applies a stacked autoregressive method. Like non-autoregressive methods, stacked autoregressive methods use the same observed frame to estimate all future frames. However, they use their own predictions as input, similar to autoregressive methods. As the number of time steps increases, predictions are sequentially stacked in the queue. To evaluate the effectiveness of IAM4VP, we conducted experiments on three common future frame prediction benchmark datasets and weather\&climate prediction benchmark datasets. The results demonstrate that our proposed model achieves state-of-the-art performance.
Self-Pair: Synthesizing Changes from Single Source for Object Change Detection in Remote Sensing Imagery
Dec 20, 2022



For change detection in remote sensing, constructing a training dataset for deep learning models is difficult due to the requirements of bi-temporal supervision. To overcome this issue, single-temporal supervision which treats change labels as the difference of two semantic masks has been proposed. This novel method trains a change detector using two spatially unrelated images with corresponding semantic labels such as building. However, training on unpaired datasets could confuse the change detector in the case of pixels that are labeled unchanged but are visually significantly different. In order to maintain the visual similarity in unchanged area, in this paper, we emphasize that the change originates from the source image and show that manipulating the source image as an after-image is crucial to the performance of change detection. Extensive experiments demonstrate the importance of maintaining visual information between pre- and post-event images, and our method outperforms existing methods based on single-temporal supervision. code is available at https://github.com/seominseok0429/Self-Pair-for-Change-Detection.
Semi-Implicit Hybrid Gradient Methods with Application to Adversarial Robustness
Feb 21, 2022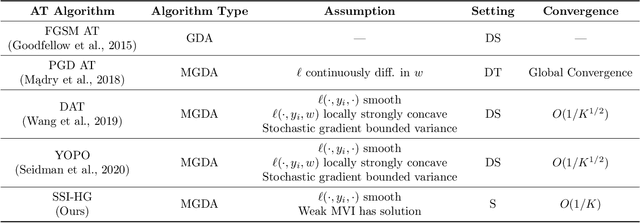
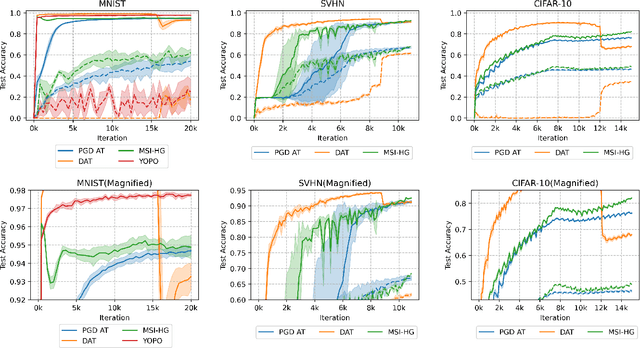

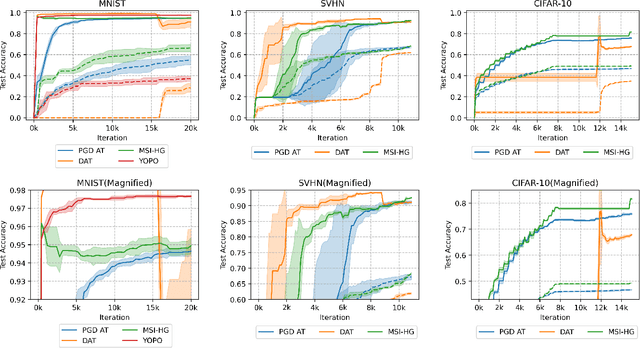
Adversarial examples, crafted by adding imperceptible perturbations to natural inputs, can easily fool deep neural networks (DNNs). One of the most successful methods for training adversarially robust DNNs is solving a nonconvex-nonconcave minimax problem with an adversarial training (AT) algorithm. However, among the many AT algorithms, only Dynamic AT (DAT) and You Only Propagate Once (YOPO) guarantee convergence to a stationary point. In this work, we generalize the stochastic primal-dual hybrid gradient algorithm to develop semi-implicit hybrid gradient methods (SI-HGs) for finding stationary points of nonconvex-nonconcave minimax problems. SI-HGs have the convergence rate $O(1/K)$, which improves upon the rate $O(1/K^{1/2})$ of DAT and YOPO. We devise a practical variant of SI-HGs, and show that it outperforms other AT algorithms in terms of convergence speed and robustness.
Contrastive Multiview Coding with Electro-optics for SAR Semantic Segmentation
Aug 31, 2021
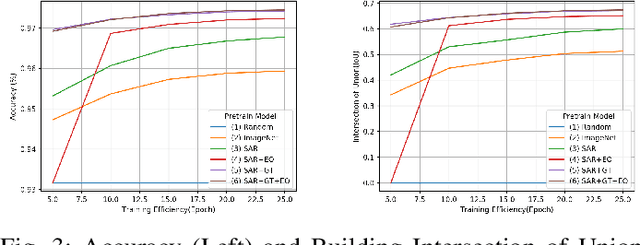
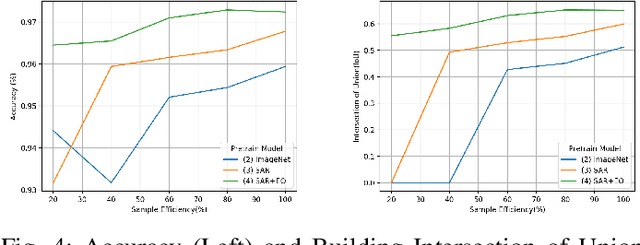
In the training of deep learning models, how the model parameters are initialized greatly affects the model performance, sample efficiency, and convergence speed. Representation learning for model initialization has recently been actively studied in the remote sensing field. In particular, the appearance characteristics of the imagery obtained using the a synthetic aperture radar (SAR) sensor are quite different from those of general electro-optical (EO) images, and thus representation learning is even more important in remote sensing domain. Motivated from contrastive multiview coding, we propose multi-modal representation learning for SAR semantic segmentation. Unlike previous studies, our method jointly uses EO imagery, SAR imagery, and a label mask. Several experiments show that our approach is superior to the existing methods in model performance, sample efficiency, and convergence speed.
Training Domain-invariant Object Detector Faster with Feature Replay and Slow Learner
May 31, 2021
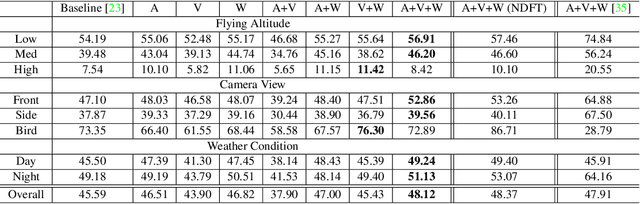
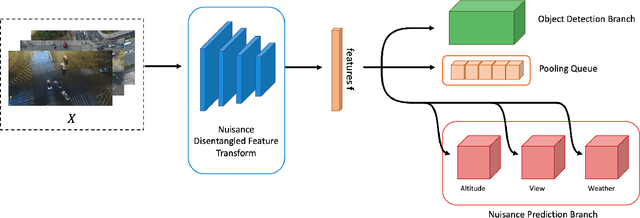
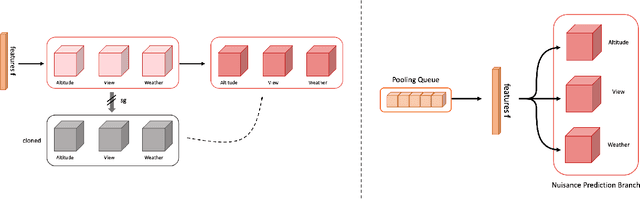
In deep learning-based object detection on remote sensing domain, nuisance factors, which affect observed variables while not affecting predictor variables, often matters because they cause domain changes. Previously, nuisance disentangled feature transformation (NDFT) was proposed to build domain-invariant feature extractor with with knowledge of nuisance factors. However, NDFT requires enormous time in a training phase, so it has been impractical. In this paper, we introduce our proposed method, A-NDFT, which is an improvement to NDFT. A-NDFT utilizes two acceleration techniques, feature replay and slow learner. Consequently, on a large-scale UAVDT benchmark, it is shown that our framework can reduce the training time of NDFT from 31 hours to 3 hours while still maintaining the performance. The code will be made publicly available online.
On the Power of Deep but Naive Partial Label Learning
Oct 22, 2020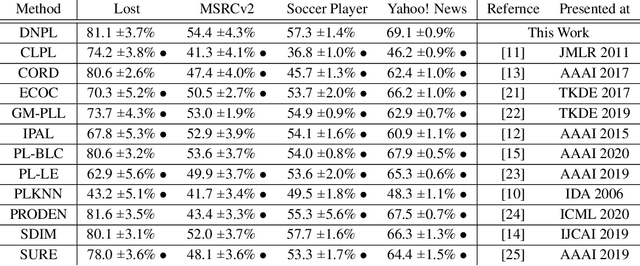
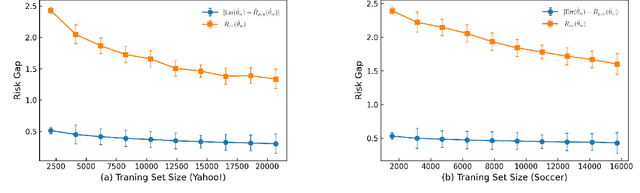
Partial label learning (PLL) is a class of weakly supervised learning where each training instance consists of a data and a set of candidate labels containing a unique ground truth label. To tackle this problem, a majority of current state-of-the-art methods employs either label disambiguation or averaging strategies. So far, PLL methods without such techniques have been considered impractical. In this paper, we challenge this view by revealing the hidden power of the oldest and naivest PLL method when it is instantiated with deep neural networks. Specifically, we show that, with deep neural networks, the naive model can achieve competitive performances against the other state-of-the-art methods, suggesting it as a strong baseline for PLL. We also address the question of how and why such a naive model works well with deep neural networks. Our empirical results indicate that deep neural networks trained on partially labeled examples generalize very well even in the over-parametrized regime and without label disambiguations or regularizations. We point out that existing learning theories on PLL are vacuous in the over-parametrized regime. Hence they cannot explain why the deep naive method works. We propose an alternative theory on how deep learning generalize in PLL problems.
Revisiting Classical Bagging with Modern Transfer Learning for On-the-fly Disaster Damage Detector
Oct 04, 2019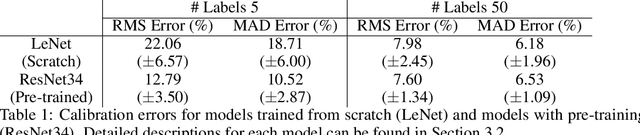
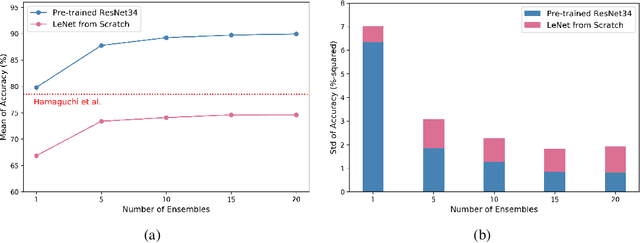
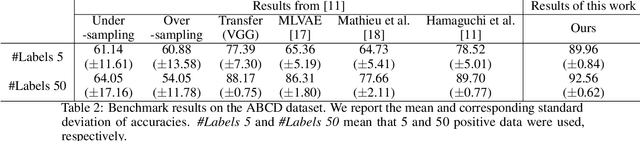
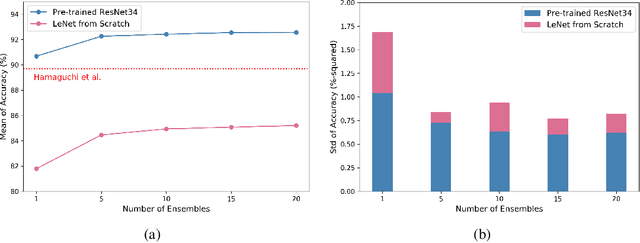
Automatic post-disaster damage detection using aerial imagery is crucial for quick assessment of damage caused by disaster and development of a recovery plan. The main problem preventing us from creating an applicable model in practice is that damaged (positive) examples we are trying to detect are much harder to obtain than undamaged (negative) examples, especially in short time. In this paper, we revisit the classical bootstrap aggregating approach in the context of modern transfer learning for data-efficient disaster damage detection. Unlike previous classical ensemble learning articles, our work points out the effectiveness of simple bagging in deep transfer learning that has been underestimated in the context of imbalanced classification. Benchmark results on the AIST Building Change Detection dataset show that our approach significantly outperforms existing methodologies, including the recently proposed disentanglement learning.
Deep Closed-Form Subspace Clustering
Aug 26, 2019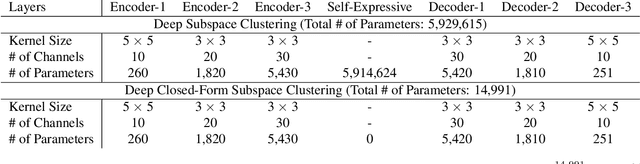
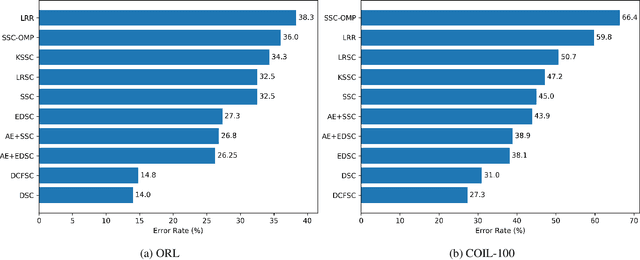
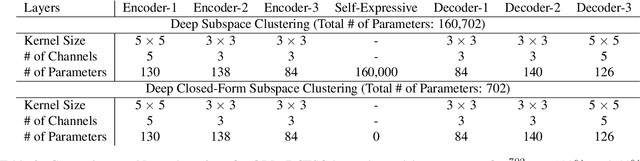
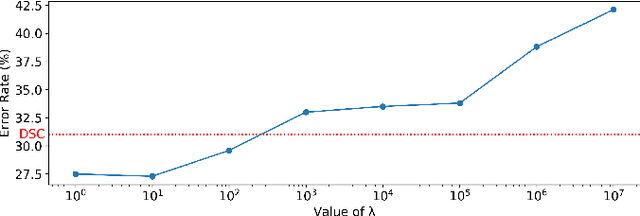
We propose Deep Closed-Form Subspace Clustering (DCFSC), a new embarrassingly simple model for subspace clustering with learning non-linear mapping. Compared with the previous deep subspace clustering (DSC) techniques, our DCFSC does not have any parameters at all for the self-expressive layer. Instead, DCFSC utilizes the implicit data-driven self-expressive layer derived from closed-form shallow auto-encoder. Moreover, DCFSC also has no complicated optimization scheme, unlike the other subspace clustering methods. With its extreme simplicity, DCFSC has significant memory-related benefits over the existing DSC method, especially on the large dataset. Several experiments showed that our DCFSC model had enough potential to be a new reference model for subspace clustering on large-scale high-dimensional dataset.
NL-LinkNet: Toward Lighter but More Accurate Road Extraction with Non-Local Operations
Aug 22, 2019
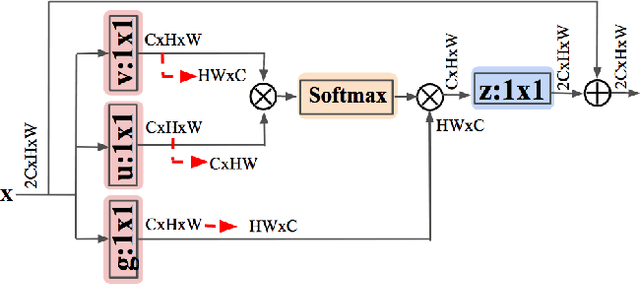
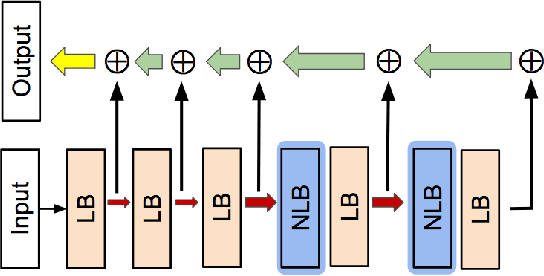
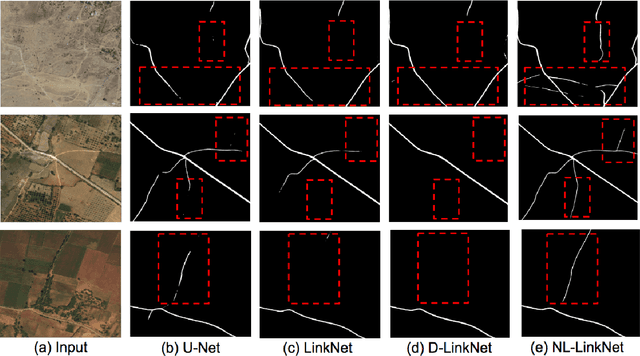
Road extraction from very high resolution satellite images is one of the most important topics in the field of remote sensing. For the road segmentation problem, spatial properties of the data can usually be captured using Convolutional Neural Networks. However, this approach only considers a few local neighborhoods at a time and has difficulty capturing long-range dependencies. In order to overcome the problem, we propose Non-Local LinkNet with non-local blocks that can grasp relations between global features. It enables each spatial feature point to refer to all other contextual information and results in more accurate road segmentation. In detail, our method achieved 65.00\% mIOU scores on the DeepGlobe 2018 Road Extraction Challenge dataset. Our best model outperformed D-LinkNet, 1st-ranked solution, by a significant gap of mIOU 0.88\% with much less number of parameters. We also present empirical analyses on proper usage of non-local blocks for the baseline model.
Bridging Adversarial Robustness and Gradient Interpretability
Apr 19, 2019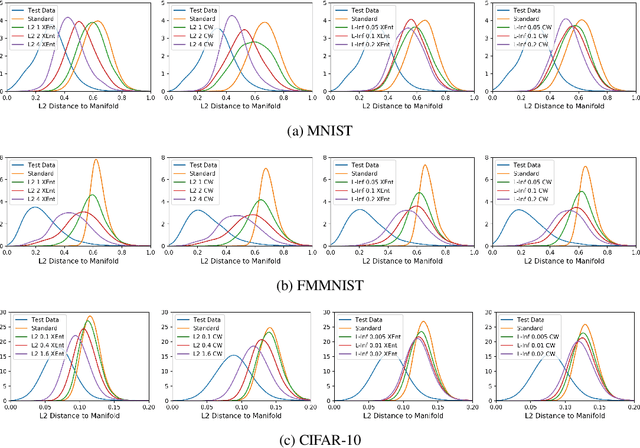

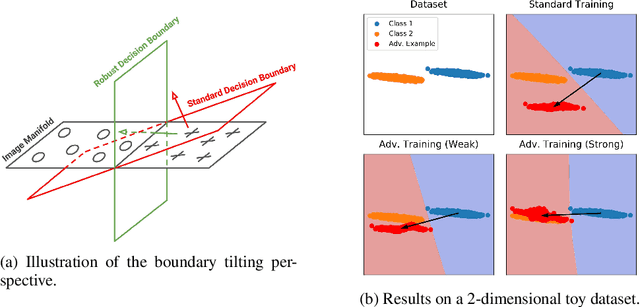
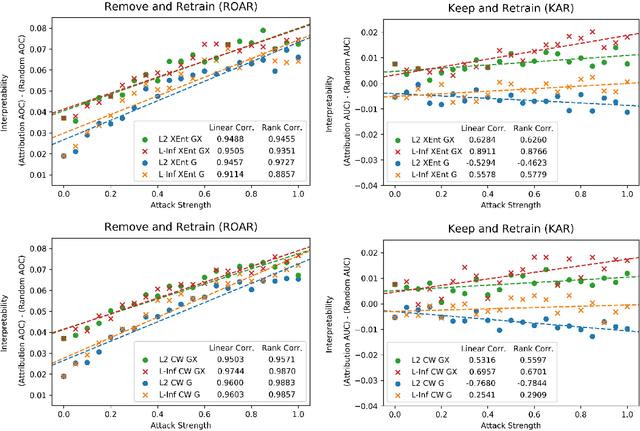
Adversarial training is a training scheme designed to counter adversarial attacks by augmenting the training dataset with adversarial examples. Surprisingly, several studies have observed that loss gradients from adversarially trained DNNs are visually more interpretable than those from standard DNNs. Although this phenomenon is interesting, there are only few works that have offered an explanation. In this paper, we attempted to bridge this gap between adversarial robustness and gradient interpretability. To this end, we identified that loss gradients from adversarially trained DNNs align better with human perception because adversarial training restricts gradients closer to the image manifold. We then demonstrated that adversarial training causes loss gradients to be quantitatively meaningful. Finally, we showed that under the adversarial training framework, there exists an empirical trade-off between test accuracy and loss gradient interpretability and proposed two potential approaches to resolving this trade-off.