 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStratXplore: Strategic Novelty-seeking and Instruction-aligned Exploration for Vision and Language Navigation
Sep 09, 2024



Embodied navigation requires robots to understand and interact with the environment based on given tasks. Vision-Language Navigation (VLN) is an embodied navigation task, where a robot navigates within a previously seen and unseen environment, based on linguistic instruction and visual inputs. VLN agents need access to both local and global action spaces; former for immediate decision making and the latter for recovering from navigational mistakes. Prior VLN agents rely only on instruction-viewpoint alignment for local and global decision making and back-track to a previously visited viewpoint, if the instruction and its current viewpoint mismatches. These methods are prone to mistakes, due to the complexity of the instruction and partial observability of the environment. We posit that, back-tracking is sub-optimal and agent that is aware of its mistakes can recover efficiently. For optimal recovery, exploration should be extended to unexplored viewpoints (or frontiers). The optimal frontier is a recently observed but unexplored viewpoint that aligns with the instruction and is novel. We introduce a memory-based and mistake-aware path planning strategy for VLN agents, called \textit{StratXplore}, that presents global and local action planning to select the optimal frontier for path correction. The proposed method collects all past actions and viewpoint features during navigation and then selects the optimal frontier suitable for recovery. Experimental results show this simple yet effective strategy improves the success rate on two VLN datasets with different task complexities.
Spatially-Aware Speaker for Vision-and-Language Navigation Instruction Generation
Sep 09, 2024



Embodied AI aims to develop robots that can \textit{understand} and execute human language instructions, as well as communicate in natural languages. On this front, we study the task of generating highly detailed navigational instructions for the embodied robots to follow. Although recent studies have demonstrated significant leaps in the generation of step-by-step instructions from sequences of images, the generated instructions lack variety in terms of their referral to objects and landmarks. Existing speaker models learn strategies to evade the evaluation metrics and obtain higher scores even for low-quality sentences. In this work, we propose SAS (Spatially-Aware Speaker), an instruction generator or \textit{Speaker} model that utilises both structural and semantic knowledge of the environment to produce richer instructions. For training, we employ a reward learning method in an adversarial setting to avoid systematic bias introduced by language evaluation metrics. Empirically, our method outperforms existing instruction generation models, evaluated using standard metrics. Our code is available at \url{https://github.com/gmuraleekrishna/SAS}.
Segment Any Object Model : Real-to-Simulation Fine-Tuning Strategy for Multi-Class Multi-Instance Segmentation
Mar 16, 2024



Multi-class multi-instance segmentation is the task of identifying masks for multiple object classes and multiple instances of the same class within an image. The foundational Segment Anything Model (SAM) is designed for promptable multi-class multi-instance segmentation but tends to output part or sub-part masks in the "everything" mode for various real-world applications. Whole object segmentation masks play a crucial role for indoor scene understanding, especially in robotics applications. We propose a new domain invariant Real-to-Simulation (Real-Sim) fine-tuning strategy for SAM. We use object images and ground truth data collected from Ai2Thor simulator during fine-tuning (real-to-sim). To allow our Segment Any Object Model (SAOM) to work in the "everything" mode, we propose the novel nearest neighbour assignment method, updating point embeddings for each ground-truth mask. SAOM is evaluated on our own dataset collected from Ai2Thor simulator. SAOM significantly improves on SAM, with a 28% increase in mIoU and a 25% increase in mAcc for 54 frequently-seen indoor object classes. Moreover, our Real-to-Simulation fine-tuning strategy demonstrates promising generalization performance in real environments without being trained on the real-world data (sim-to-real). The dataset and the code will be released after publication.
What Is Near?: Room Locality Learning for Enhanced Robot Vision-Language-Navigation in Indoor Living Environments
Sep 10, 2023Humans use their knowledge of common house layouts obtained from previous experiences to predict nearby rooms while navigating in new environments. This greatly helps them navigate previously unseen environments and locate their target room. To provide layout prior knowledge to navigational agents based on common human living spaces, we propose WIN (\textit{W}hat \textit{I}s \textit{N}ear), a commonsense learning model for Vision Language Navigation (VLN) tasks. VLN requires an agent to traverse indoor environments based on descriptive navigational instructions. Unlike existing layout learning works, WIN predicts the local neighborhood map based on prior knowledge of living spaces and current observation, operating on an imagined global map of the entire environment. The model infers neighborhood regions based on visual cues of current observations, navigational history, and layout common sense. We show that local-global planning based on locality knowledge and predicting the indoor layout allows the agent to efficiently select the appropriate action. Specifically, we devised a cross-modal transformer that utilizes this locality prior for decision-making in addition to visual inputs and instructions. Experimental results show that locality learning using WIN provides better generalizability compared to classical VLN agents in unseen environments. Our model performs favorably on standard VLN metrics, with Success Rate 68\% and Success weighted by Path Length 63\% in unseen environments.
Indoor Semantic Scene Understanding using Multi-modality Fusion
Aug 17, 2021
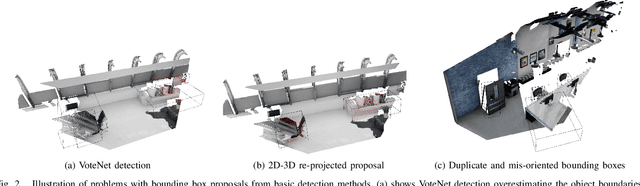

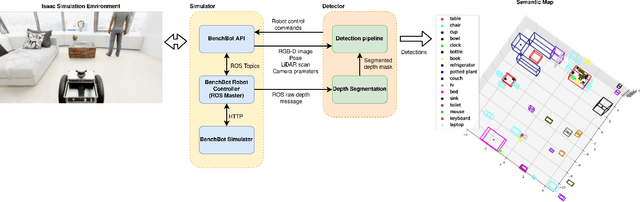
Seamless Human-Robot Interaction is the ultimate goal of developing service robotic systems. For this, the robotic agents have to understand their surroundings to better complete a given task. Semantic scene understanding allows a robotic agent to extract semantic knowledge about the objects in the environment. In this work, we present a semantic scene understanding pipeline that fuses 2D and 3D detection branches to generate a semantic map of the environment. The 2D mask proposals from state-of-the-art 2D detectors are inverse-projected to the 3D space and combined with 3D detections from point segmentation networks. Unlike previous works that were evaluated on collected datasets, we test our pipeline on an active photo-realistic robotic environment - BenchBot. Our novelty includes rectification of 3D proposals using projected 2D detections and modality fusion based on object size. This work is done as part of the Robotic Vision Scene Understanding Challenge (RVSU). The performance evaluation demonstrates that our pipeline has improved on baseline methods without significant computational bottleneck.