 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevenue Optimization with Price-Sensitive and Interdependent Demand
May 22, 2025As Kalyan T. Talluri and Garrett J. Van Ryzin describe in their work [3], Revenue Management aims to maximize an organization's revenue by considering three types of decision categories: structural, pricing, and quantity. In this document, our primary focus will be on decisions related to pricing and quantity for the sale of airline tickets on a direct flight over a certain number of time periods. More specifically, we will only focus on the optimization aspect of this problem. We will assume the demand data to be given, since Air France estimates it beforehand using real data. Similarly, we assume all price options to be predetermined by Air France's algorithms and verified by their analysts. Our objective will be to maximize the revenue of a direct flight by choosing the prices for each product from the predefined set of options. -- Comme d\'ecrit par Kalyan T. Talluri et Garrett J. Van Ryzin dans leur ouvrage [3], le Revenue Management consiste en la maximisation du revenu d'un organisme \`a partir de trois types de cat\'egories de d\'ecision : structurelles, prix et quantit\'e. Dans ce document, nous nous int\'eresserons principalement aux d\'ecisions de type prix et quantit\'e pour la vente de billets d'avion sur un vol direct au cours d'un certain nombre de pas de temps. Plus pr\'ecis\'ement, nous nous situerons dans la partie optimisation du probl\`eme. Nous prendrons ainsi les donn\'ees de demande comme acquises, car elles sont estim\'ees au pr\'ealable par Air France \`a partir des donn\'ees r\'eelles. De m\^eme, pour chaque produit que l'on cherchera \`a vendre, on nous impose en amont les prix possibles que l'on a droit d'utiliser et qui se basent sur des algorithmes d'Air France dont les r\'esultats sont v\'erifi\'es par des analystes. Notre but sera alors de maximiser le revenu d'un vol direct en choisissant les prix de chaque produit parmi ceux impos\'es.
Reinforcement Learning for Stock Transactions
May 22, 2025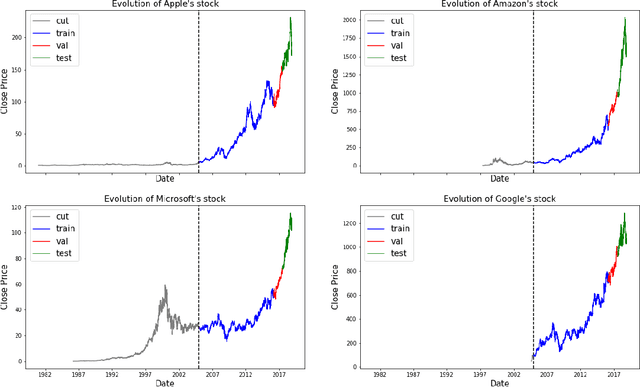
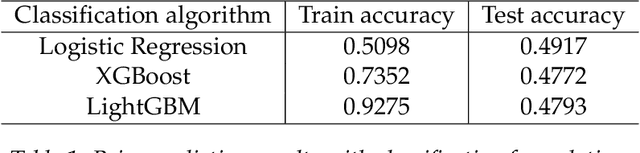
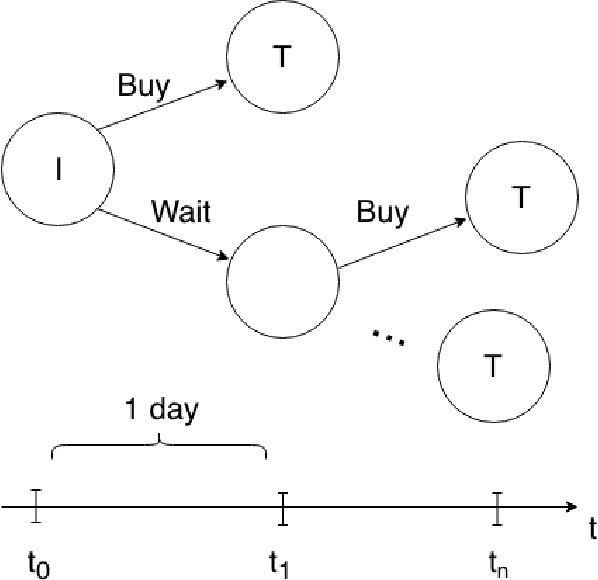
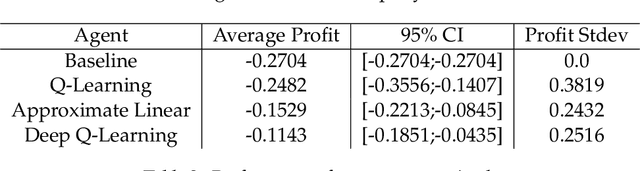
Much research has been done to analyze the stock market. After all, if one can determine a pattern in the chaotic frenzy of transactions, then they could make a hefty profit from capitalizing on these insights. As such, the goal of our project was to apply reinforcement learning (RL) to determine the best time to buy a stock within a given time frame. With only a few adjustments, our model can be extended to identify the best time to sell a stock as well. In order to use the format of free, real-world data to train the model, we define our own Markov Decision Process (MDP) problem. These two papers [5] [6] helped us in formulating the state space and the reward system of our MDP problem. We train a series of agents using Q-Learning, Q-Learning with linear function approximation, and deep Q-Learning. In addition, we try to predict the stock prices using machine learning regression and classification models. We then compare our agents to see if they converge on a policy, and if so, which one learned the best policy to maximize profit on the stock market.
Pivot Language for Low-Resource Machine Translation
May 21, 2025



Certain pairs of languages suffer from lack of a parallel corpus which is large in size and diverse in domain. One of the ways this is overcome is via use of a pivot language. In this paper we use Hindi as a pivot language to translate Nepali into English. We describe what makes Hindi a good candidate for the pivot. We discuss ways in which a pivot language can be used, and use two such approaches - the Transfer Method (fully supervised) and Backtranslation (semi-supervised) - to translate Nepali into English. Using the former, we are able to achieve a devtest Set SacreBLEU score of 14.2, which improves the baseline fully supervised score reported by (Guzman et al., 2019) by 6.6 points. While we are slightly below the semi-supervised baseline score of 15.1, we discuss what may have caused this under-performance, and suggest scope for future work.
Instance Segmentation for Point Sets
May 20, 2025Recently proposed neural network architectures like PointNet [QSMG16] and PointNet++ [QYSG17] have made it possible to apply Deep Learning to 3D point sets. The feature representations of shapes learned by these two networks enabled training classifiers for Semantic Segmentation, and more recently for Instance Segmentation via the Similarity Group Proposal Network (SGPN) [WYHN17]. One area of improvement which has been highlighted by SGPN's authors, pertains to use of memory intensive similarity matrices which occupy memory quadratic in the number of points. In this report, we attempt to tackle this issue through use of two sampling based methods, which compute Instance Segmentation on a sub-sampled Point Set, and then extrapolate labels to the complete set using the nearest neigbhour approach. While both approaches perform equally well on large sub-samples, the random-based strategy gives the most improvements in terms of speed and memory usage.
3D Reconstruction from Sketches
May 20, 2025We consider the problem of reconstructing a 3D scene from multiple sketches. We propose a pipeline which involves (1) stitching together multiple sketches through use of correspondence points, (2) converting the stitched sketch into a realistic image using a CycleGAN, and (3) estimating that image's depth-map using a pre-trained convolutional neural network based architecture called MegaDepth. Our contribution includes constructing a dataset of image-sketch pairs, the images for which are from the Zurich Building Database, and sketches have been generated by us. We use this dataset to train a CycleGAN for our pipeline's second step. We end up with a stitching process that does not generalize well to real drawings, but the rest of the pipeline that creates a 3D reconstruction from a single sketch performs quite well on a wide variety of drawings.