 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinux Kernel Configurations at Scale: A Dataset for Performance and Evolution Analysis
May 12, 2025

Configuring the Linux kernel to meet specific requirements, such as binary size, is highly challenging due to its immense complexity-with over 15,000 interdependent options evolving rapidly across different versions. Although several studies have explored sampling strategies and machine learning methods to understand and predict the impact of configuration options, the literature still lacks a comprehensive and large-scale dataset encompassing multiple kernel versions along with detailed quantitative measurements. To bridge this gap, we introduce LinuxData, an accessible collection of kernel configurations spanning several kernel releases, specifically from versions 4.13 to 5.8. This dataset, gathered through automated tools and build processes, comprises over 240,000 kernel configurations systematically labeled with compilation outcomes and binary sizes. By providing detailed records of configuration evolution and capturing the intricate interplay among kernel options, our dataset enables innovative research in feature subset selection, prediction models based on machine learning, and transfer learning across kernel versions. Throughout this paper, we describe how the dataset has been made easily accessible via OpenML and illustrate how it can be leveraged using only a few lines of Python code to evaluate AI-based techniques, such as supervised machine learning. We anticipate that this dataset will significantly enhance reproducibility and foster new insights into configuration-space analysis at a scale that presents unique opportunities and inherent challenges, thereby advancing our understanding of the Linux kernel's configurability and evolution.
Learning Software Configuration Spaces: A Systematic Literature Review
Jun 07, 2019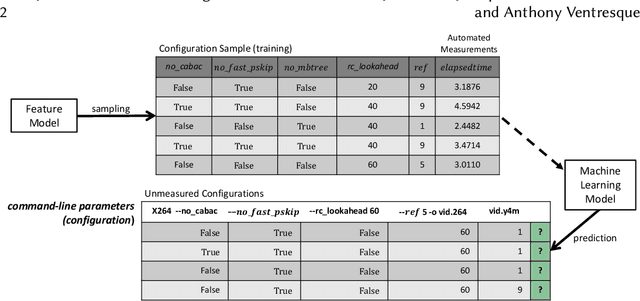

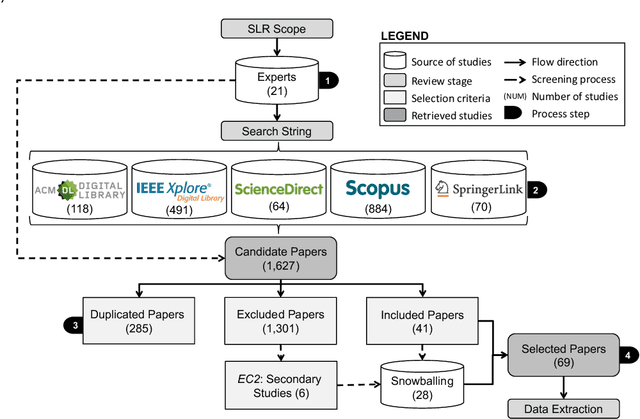
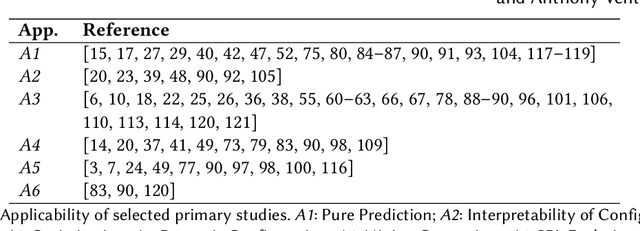
Most modern software systems (operating systems like Linux or Android, Web browsers like Firefox or Chrome, video encoders like ffmpeg, x264 or VLC, mobile and cloud applications, etc.) are highly-configurable. Hundreds of configuration options, features, or plugins can be combined, each potentially with distinct functionality and effects on execution time, security, energy consumption, etc. Due to the combinatorial explosion and the cost of executing software, it is quickly impossible to exhaustively explore the whole configuration space. Hence, numerous works have investigated the idea of learning it from a small sample of configurations' measurements. The pattern "sampling, measuring, learning" has emerged in the literature, with several practical interests for both software developers and end-users of configurable systems. In this survey, we report on the different application objectives (e.g., performance prediction, configuration optimization, constraint mining), use-cases, targeted software systems and application domains. We review the various strategies employed to gather a representative and cost-effective sample. We describe automated software techniques used to measure functional and non-functional properties of configurations. We classify machine learning algorithms and how they relate to the pursued application. Finally, we also describe how researchers evaluate the quality of the learning process. The findings from this systematic review show that the potential application objective is important; there are a vast number of case studies reported in the literature from the basis of several domains and software systems. Yet, the huge variant space of configurable systems is still challenging and calls to further investigate the synergies between artificial intelligence and software engineering.