 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised 3D anatomy segmentation using self-distilled masked image transformer (SMIT)
May 20, 2022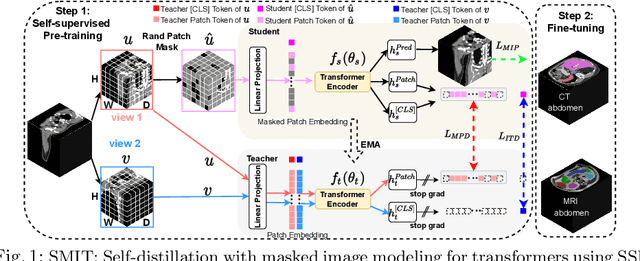
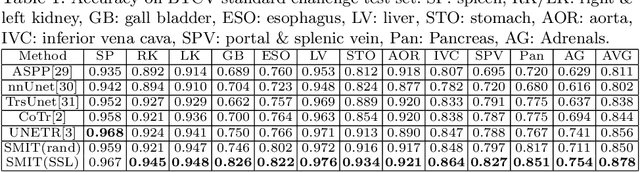
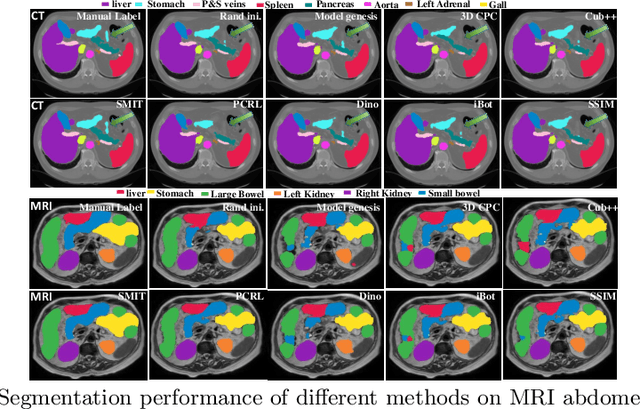
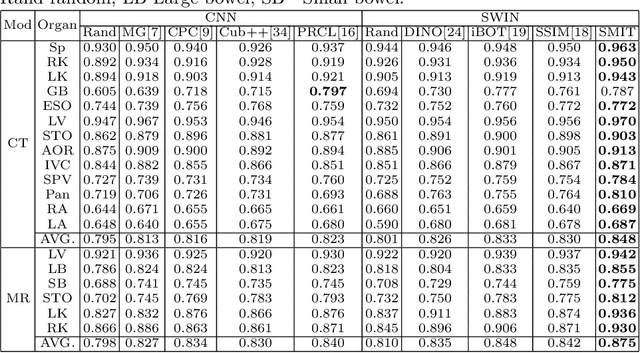
Vision transformers, with their ability to more efficiently model long-range context, have demonstrated impressive accuracy gains in several computer vision and medical image analysis tasks including segmentation. However, such methods need large labeled datasets for training, which is hard to obtain for medical image analysis. Self-supervised learning (SSL) has demonstrated success in medical image segmentation using convolutional networks. In this work, we developed a \underline{s}elf-distillation learning with \underline{m}asked \underline{i}mage modeling method to perform SSL for vision \underline{t}ransformers (SMIT) applied to 3D multi-organ segmentation from CT and MRI. Our contribution is a dense pixel-wise regression within masked patches called masked image prediction, which we combined with masked patch token distillation as pretext task to pre-train vision transformers. We show our approach is more accurate and requires fewer fine tuning datasets than other pretext tasks. Unlike prior medical image methods, which typically used image sets arising from disease sites and imaging modalities corresponding to the target tasks, we used 3,643 CT scans (602,708 images) arising from head and neck, lung, and kidney cancers as well as COVID-19 for pre-training and applied it to abdominal organs segmentation from MRI pancreatic cancer patients as well as publicly available 13 different abdominal organs segmentation from CT. Our method showed clear accuracy improvement (average DSC of 0.875 from MRI and 0.878 from CT) with reduced requirement for fine-tuning datasets over commonly used pretext tasks. Extensive comparisons against multiple current SSL methods were done. Code will be made available upon acceptance for publication.
One shot PACS: Patient specific Anatomic Context and Shape prior aware recurrent registration-segmentation of longitudinal thoracic cone beam CTs
Jan 26, 2022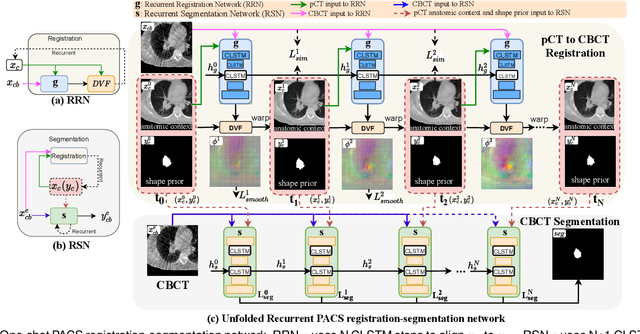
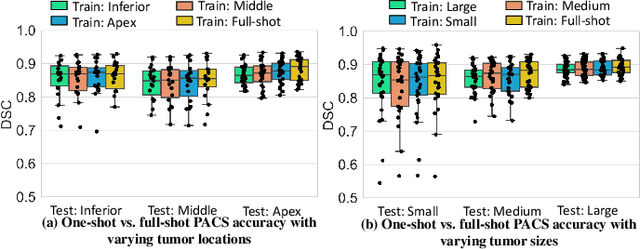
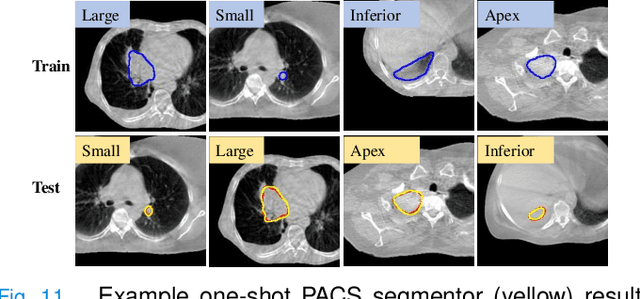
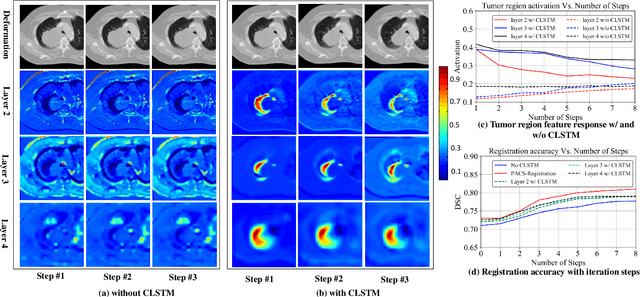
Image-guided adaptive lung radiotherapy requires accurate tumor and organs segmentation from during treatment cone-beam CT (CBCT) images. Thoracic CBCTs are hard to segment because of low soft-tissue contrast, imaging artifacts, respiratory motion, and large treatment induced intra-thoracic anatomic changes. Hence, we developed a novel Patient-specific Anatomic Context and Shape prior or PACS-aware 3D recurrent registration-segmentation network for longitudinal thoracic CBCT segmentation. Segmentation and registration networks were concurrently trained in an end-to-end framework and implemented with convolutional long-short term memory models. The registration network was trained in an unsupervised manner using pairs of planning CT (pCT) and CBCT images and produced a progressively deformed sequence of images. The segmentation network was optimized in a one-shot setting by combining progressively deformed pCT (anatomic context) and pCT delineations (shape context) with CBCT images. Our method, one-shot PACS was significantly more accurate (p$<$0.001) for tumor (DSC of 0.83 $\pm$ 0.08, surface DSC [sDSC] of 0.97 $\pm$ 0.06, and Hausdorff distance at $95^{th}$ percentile [HD95] of 3.97$\pm$3.02mm) and the esophagus (DSC of 0.78 $\pm$ 0.13, sDSC of 0.90$\pm$0.14, HD95 of 3.22$\pm$2.02) segmentation than multiple methods. Ablation tests and comparative experiments were also done.
Unpaired cross-modality educed distillation (CMEDL) applied to CT lung tumor segmentation
Jul 16, 2021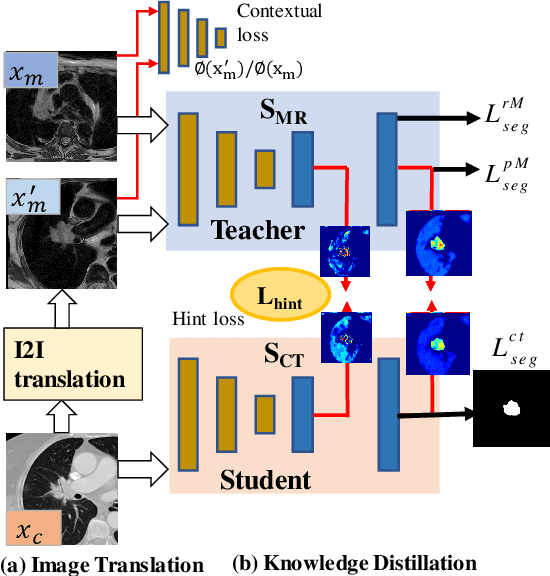
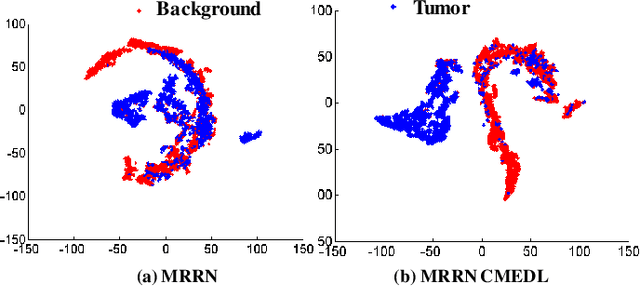
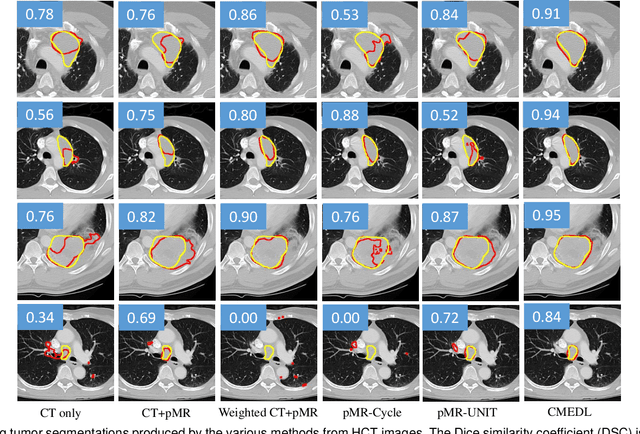
Accurate and robust segmentation of lung cancers from CTs is needed to more accurately plan and deliver radiotherapy and to measure treatment response. This is particularly difficult for tumors located close to mediastium, due to low soft-tissue contrast. Therefore, we developed a new cross-modality educed distillation (CMEDL) approach, using unpaired CT and MRI scans, whereby a teacher MRI network guides a student CT network to extract features that signal the difference between foreground and background. Our contribution eliminates two requirements of distillation methods: (i) paired image sets by using an image to image (I2I) translation and (ii) pre-training of the teacher network with a large training set by using concurrent training of all networks. Our framework uses an end-to-end trained unpaired I2I translation, teacher, and student segmentation networks. Our framework can be combined with any I2I and segmentation network. We demonstrate our framework's feasibility using 3 segmentation and 2 I2I methods. All networks were trained with 377 CT and 82 T2w MRI from different sets of patients. Ablation tests and different strategies for incorporating MRI information into CT were performed. Accuracy was measured using Dice similarity (DSC), surface Dice (sDSC), and Hausdorff distance at the 95$^{th}$ percentile (HD95). The CMEDL approach was significantly (p $<$ 0.001) more accurate than non-CMEDL methods, quantitatively and visually. It produced the highest segmentation accuracy (sDSC of 0.83 $\pm$ 0.16 and HD95 of 5.20 $\pm$ 6.86mm). CMEDL was also more accurate than using either pMRI's or the combination of CT's with pMRI's for segmentation.
Deformation Driven Seq2Seq Longitudinal Tumor and Organs-at-Risk Prediction for Radiotherapy
Jun 18, 2021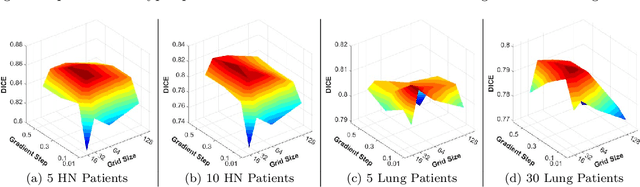
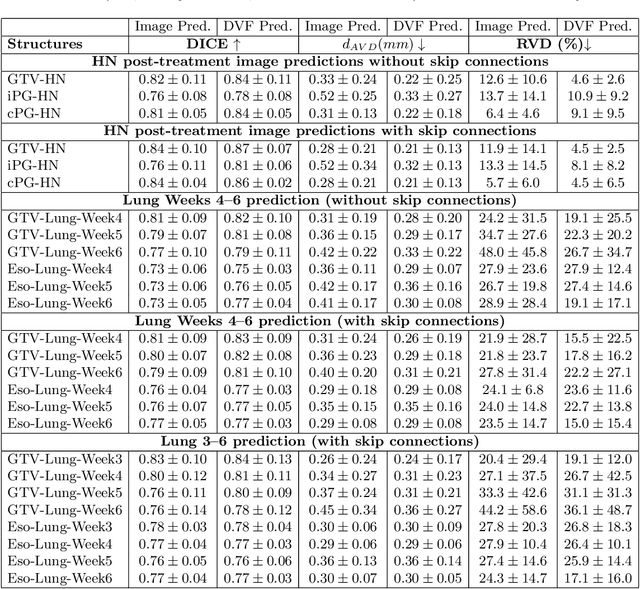
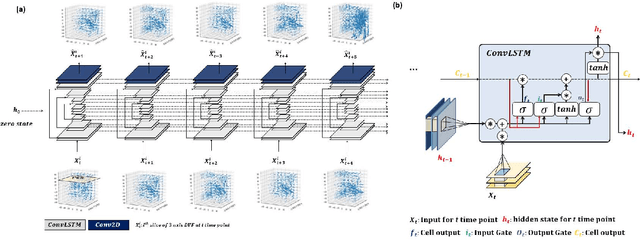
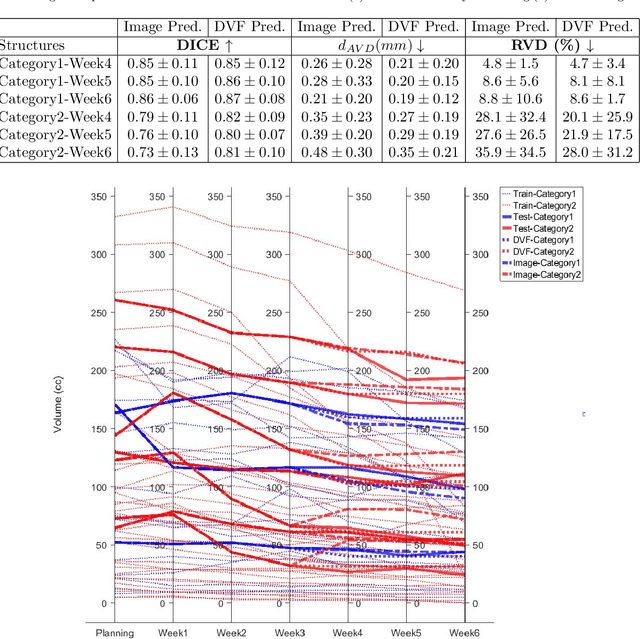
Purpose: Radiotherapy presents unique challenges and clinical requirements for longitudinal tumor and organ-at-risk (OAR) prediction during treatment. The challenges include tumor inflammation/edema and radiation-induced changes in organ geometry, whereas the clinical requirements demand flexibility in input/output sequence timepoints to update the predictions on rolling basis and the grounding of all predictions in relationship to the pre-treatment imaging information for response and toxicity assessment in adaptive radiotherapy. Methods: To deal with the aforementioned challenges and to comply with the clinical requirements, we present a novel 3D sequence-to-sequence model based on Convolution Long Short Term Memory (ConvLSTM) that makes use of series of deformation vector fields (DVF) between individual timepoints and reference pre-treatment/planning CTs to predict future anatomical deformations and changes in gross tumor volume as well as critical OARs. High-quality DVF training data is created by employing hyper-parameter optimization on the subset of the training data with DICE coefficient and mutual information metric. We validated our model on two radiotherapy datasets: a publicly available head-and-neck dataset (28 patients with manually contoured pre-, mid-, and post-treatment CTs), and an internal non-small cell lung cancer dataset (63 patients with manually contoured planning CT and 6 weekly CBCTs). Results: The use of DVF representation and skip connections overcomes the blurring issue of ConvLSTM prediction with the traditional image representation. The mean and standard deviation of DICE for predictions of lung GTV at week 4, 5, and 6 were 0.83$\pm$0.09, 0.82$\pm$0.08, and 0.81$\pm$0.10, respectively, and for post-treatment ipsilateral and contralateral parotids, were 0.81$\pm$0.06 and 0.85$\pm$0.02.
Deep cross-modality (MR-CT) educed distillation learning for cone beam CT lung tumor segmentation
Feb 26, 2021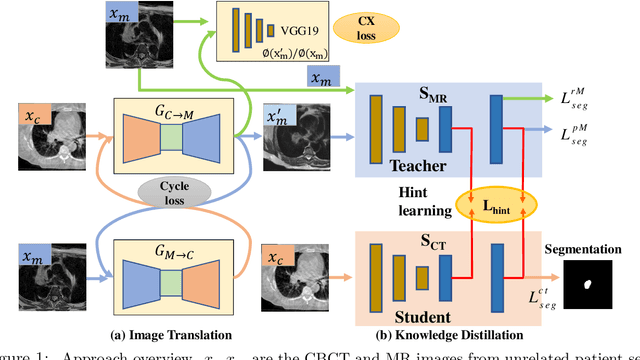
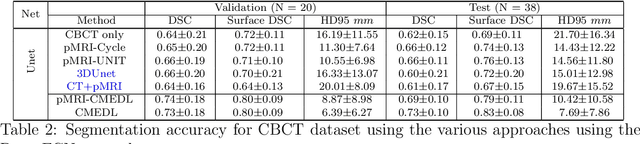
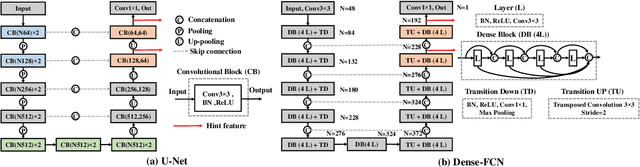
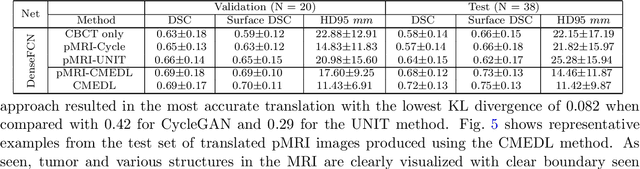
Despite the widespread availability of in-treatment room cone beam computed tomography (CBCT) imaging, due to the lack of reliable segmentation methods, CBCT is only used for gross set up corrections in lung radiotherapies. Accurate and reliable auto-segmentation tools could potentiate volumetric response assessment and geometry-guided adaptive radiation therapies. Therefore, we developed a new deep learning CBCT lung tumor segmentation method. Methods: The key idea of our approach called cross modality educed distillation (CMEDL) is to use magnetic resonance imaging (MRI) to guide a CBCT segmentation network training to extract more informative features during training. We accomplish this by training an end-to-end network comprised of unpaired domain adaptation (UDA) and cross-domain segmentation distillation networks (SDN) using unpaired CBCT and MRI datasets. Feature distillation regularizes the student network to extract CBCT features that match the statistical distribution of MRI features extracted by the teacher network and obtain better differentiation of tumor from background.} We also compared against an alternative framework that used UDA with MR segmentation network, whereby segmentation was done on the synthesized pseudo MRI representation. All networks were trained with 216 weekly CBCTs and 82 T2-weighted turbo spin echo MRI acquired from different patient cohorts. Validation was done on 20 weekly CBCTs from patients not used in training. Independent testing was done on 38 weekly CBCTs from patients not used in training or validation. Segmentation accuracy was measured using surface Dice similarity coefficient (SDSC) and Hausdroff distance at 95th percentile (HD95) metrics.
Nested-block self-attention for robust radiotherapy planning segmentation
Feb 26, 2021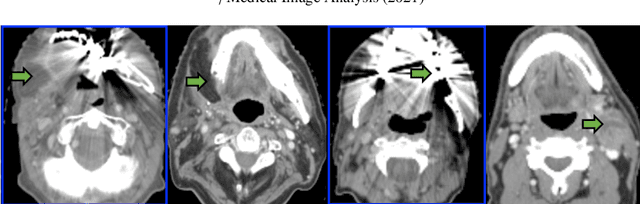
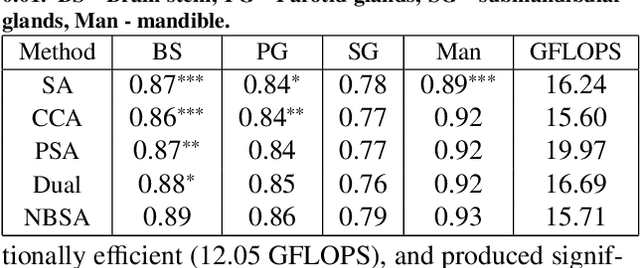
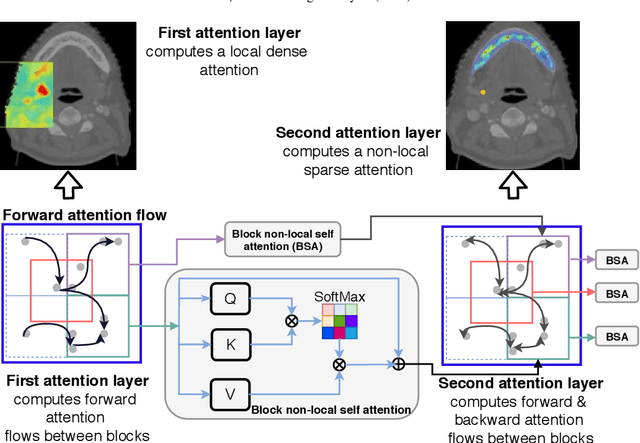
Although deep convolutional networks have been widely studied for head and neck (HN) organs at risk (OAR) segmentation, their use for routine clinical treatment planning is limited by a lack of robustness to imaging artifacts, low soft tissue contrast on CT, and the presence of abnormal anatomy. In order to address these challenges, we developed a computationally efficient nested block self-attention (NBSA) method that can be combined with any convolutional network. Our method achieves computational efficiency by performing non-local calculations within memory blocks of fixed spatial extent. Contextual dependencies are captured by passing information in a raster scan order between blocks, as well as through a second attention layer that causes bi-directional attention flow. We implemented our approach on three different networks to demonstrate feasibility. Following training using 200 cases, we performed comprehensive evaluations using conventional and clinical metrics on a separate set of 172 test scans sourced from external and internal institution datasets without any exclusion criteria. NBSA required a similar number of computations (15.7 gflops) as the most efficient criss-cross attention (CCA) method and generated significantly more accurate segmentations for brain stem (Dice of 0.89 vs. 0.86) and parotid glands (0.86 vs. 0.84) than CCA. NBSA's segmentations were less variable than multiple 3D methods, including for small organs with low soft-tissue contrast such as the submandibular glands (surface Dice of 0.90).
Unified cross-modality feature disentangler for unsupervised multi-domain MRI abdomen organs segmentation
Jul 19, 2020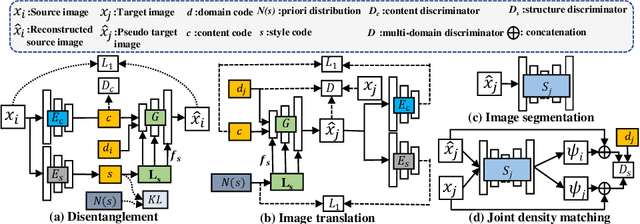

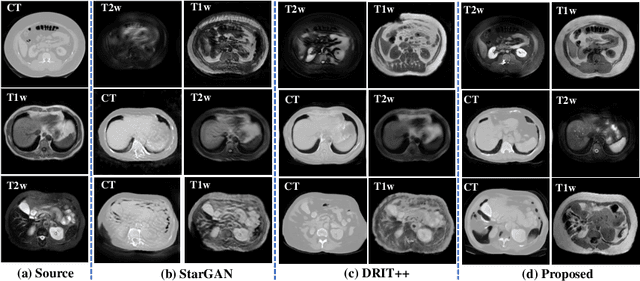
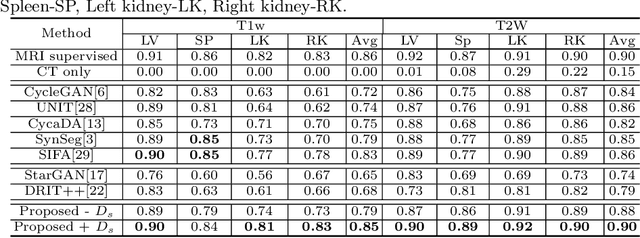
Our contribution is a unified cross-modality feature disentagling approach for multi-domain image translation and multiple organ segmentation. Using CT as the labeled source domain, our approach learns to segment multi-modal (T1-weighted and T2-weighted) MRI having no labeled data. Our approach uses a variational auto-encoder (VAE) to disentangle the image content from style. The VAE constrains the style feature encoding to match a universal prior (Gaussian) that is assumed to span the styles of all the source and target modalities. The extracted image style is converted into a latent style scaling code, which modulates the generator to produce multi-modality images according to the target domain code from the image content features. Finally, we introduce a joint distribution matching discriminator that combines the translated images with task-relevant segmentation probability maps to further constrain and regularize image-to-image (I2I) translations. We performed extensive comparisons to multiple state-of-the-art I2I translation and segmentation methods. Our approach resulted in the lowest average multi-domain image reconstruction error of 1.34$\pm$0.04. Our approach produced an average Dice similarity coefficient (DSC) of 0.85 for T1w and 0.90 for T2w MRI for multi-organ segmentation, which was highly comparable to a fully supervised MRI multi-organ segmentation network (DSC of 0.86 for T1w and 0.90 for T2w MRI).
* This paper has been accepted by MICCAI2020
PSIGAN: Joint probabilistic segmentation and image distribution matching for unpaired cross-modality adaptation based MRI segmentation
Jul 18, 2020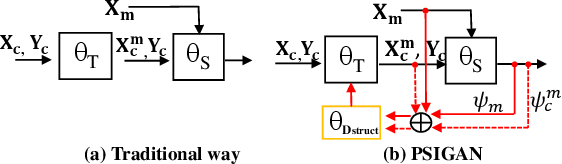
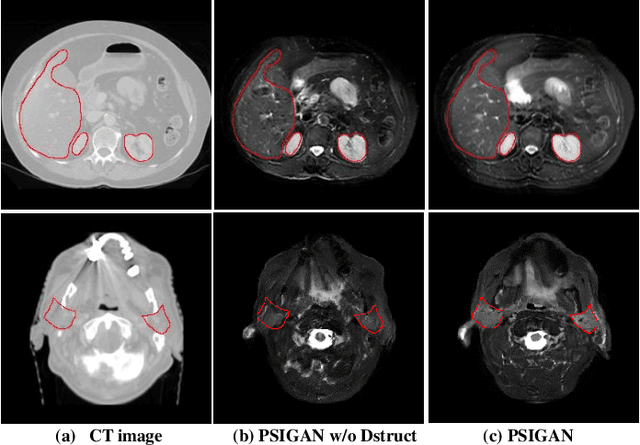
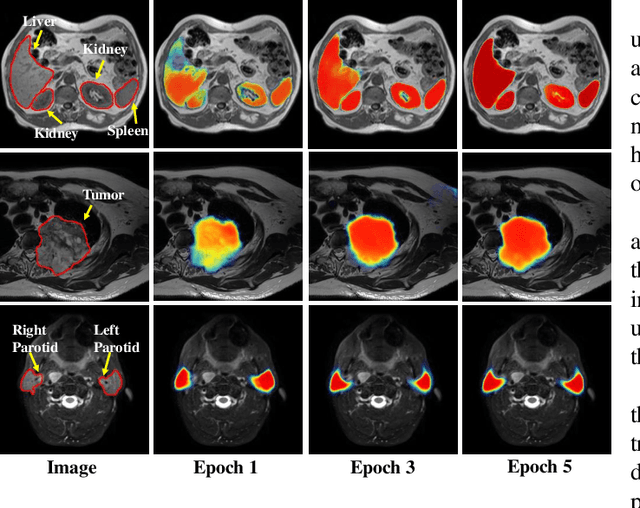
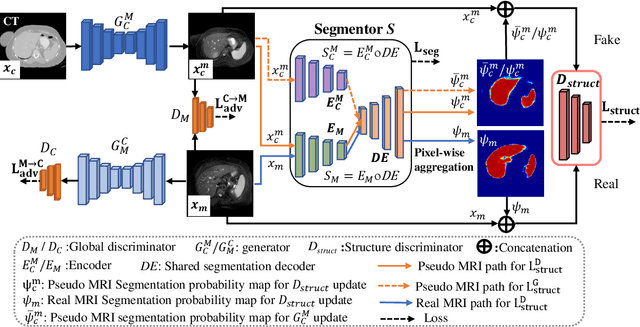
We developed a new joint probabilistic segmentation and image distribution matching generative adversarial network (PSIGAN) for unsupervised domain adaptation (UDA) and multi-organ segmentation from magnetic resonance (MRI) images. Our UDA approach models the co-dependency between images and their segmentation as a joint probability distribution using a new structure discriminator. The structure discriminator computes structure of interest focused adversarial loss by combining the generated pseudo MRI with probabilistic segmentations produced by a simultaneously trained segmentation sub-network. The segmentation sub-network is trained using the pseudo MRI produced by the generator sub-network. This leads to a cyclical optimization of both the generator and segmentation sub-networks that are jointly trained as part of an end-to-end network. Extensive experiments and comparisons against multiple state-of-the-art methods were done on four different MRI sequences totalling 257 scans for generating multi-organ and tumor segmentation. The experiments included, (a) 20 T1-weighted (T1w) in-phase mdixon and (b) 20 T2-weighted (T2w) abdominal MRI for segmenting liver, spleen, left and right kidneys, (c) 162 T2-weighted fat suppressed head and neck MRI (T2wFS) for parotid gland segmentation, and (d) 75 T2w MRI for lung tumor segmentation. Our method achieved an overall average DSC of 0.87 on T1w and 0.90 on T2w for the abdominal organs, 0.82 on T2wFS for the parotid glands, and 0.77 on T2w MRI for lung tumors.
* This paper has been accepted by IEEE Transactions on Medical Imaging
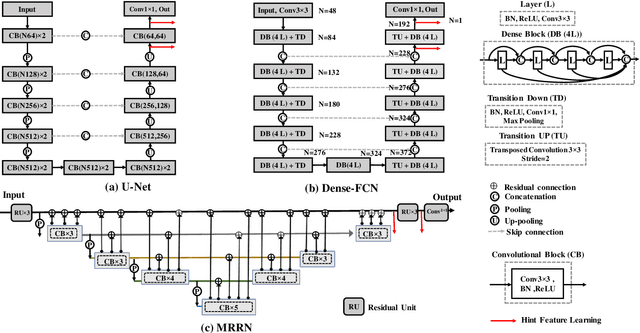
Multiple resolution residual network for automatic thoracic organs-at-risk segmentation from CT
May 31, 2020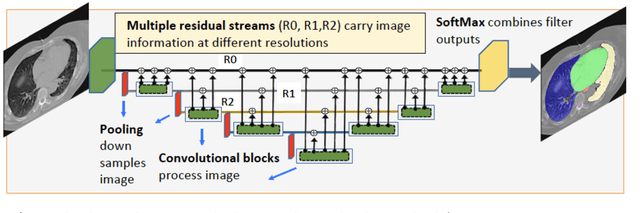
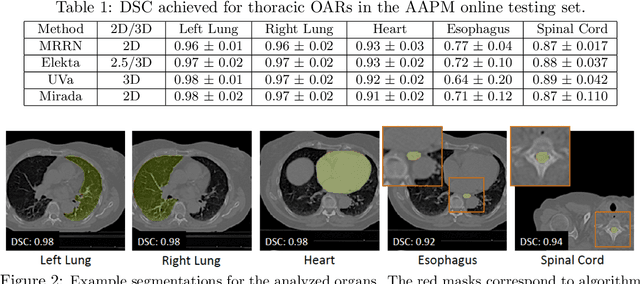
We implemented and evaluated a multiple resolution residual network (MRRN) for multiple normal organs-at-risk (OAR) segmentation from computed tomography (CT) images for thoracic radiotherapy treatment (RT) planning. Our approach simultaneously combines feature streams computed at multiple image resolutions and feature levels through residual connections. The feature streams at each level are updated as the images are passed through various feature levels. We trained our approach using 206 thoracic CT scans of lung cancer patients with 35 scans held out for validation to segment the left and right lungs, heart, esophagus, and spinal cord. This approach was tested on 60 CT scans from the open-source AAPM Thoracic Auto-Segmentation Challenge dataset. Performance was measured using the Dice Similarity Coefficient (DSC). Our approach outperformed the best-performing method in the grand challenge for hard-to-segment structures like the esophagus and achieved comparable results for all other structures. Median DSC using our method was 0.97 (interquartile range [IQR]: 0.97-0.98) for the left and right lungs, 0.93 (IQR: 0.93-0.95) for the heart, 0.78 (IQR: 0.76-0.80) for the esophagus, and 0.88 (IQR: 0.86-0.89) for the spinal cord.
Local block-wise self attention for normal organ segmentation
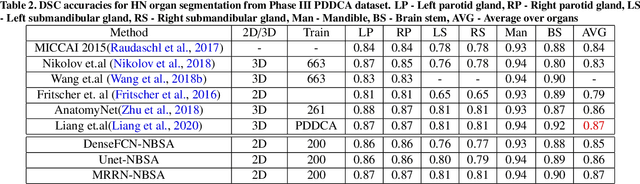
Sep 11, 2019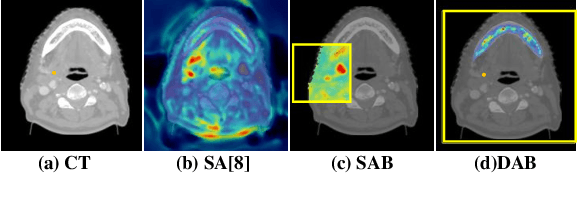
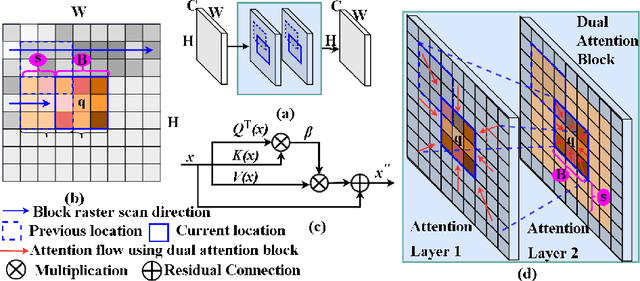
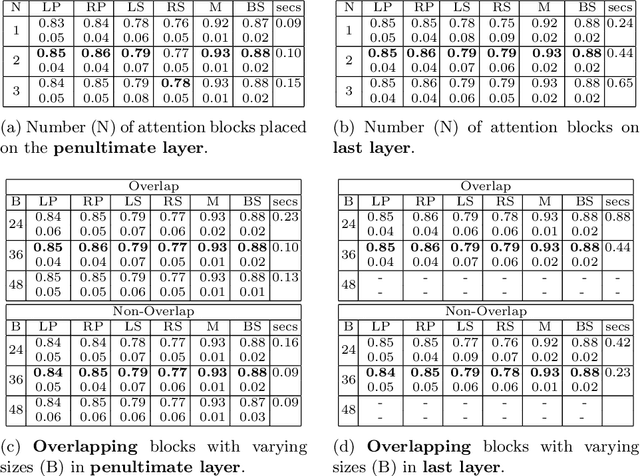
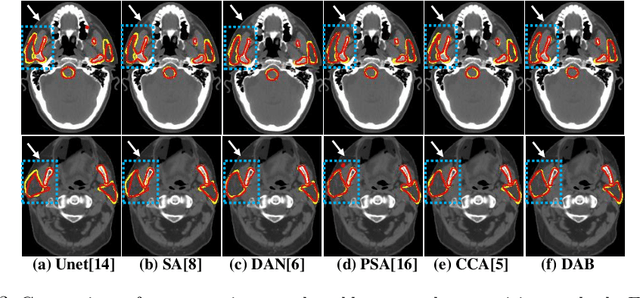
We developed a new and computationally simple local block-wise self attention based normal structures segmentation approach applied to head and neck computed tomography (CT) images. Our method uses the insight that normal organs exhibit regularity in their spatial location and inter-relation within images, which can be leveraged to simplify the computations required to aggregate feature information. We accomplish this by using local self attention blocks that pass information between each other to derive the attention map. We show that adding additional attention layers increases the contextual field and captures focused attention from relevant structures. We developed our approach using U-net and compared it against multiple state-of-the-art self attention methods. All models were trained on 48 internal headneck CT scans and tested on 48 CT scans from the external public domain database of computational anatomy dataset. Our method achieved the highest Dice similarity coefficient segmentation accuracy of 0.85$\pm$0.04, 0.86$\pm$0.04 for left and right parotid glands, 0.79$\pm$0.07 and 0.77$\pm$0.05 for left and right submandibular glands, 0.93$\pm$0.01 for mandible and 0.88$\pm$0.02 for the brain stem with the lowest increase of 66.7\% computing time per image and 0.15\% increase in model parameters compared with standard U-net. The best state-of-the-art method called point-wise spatial attention, achieved \textcolor{black}{comparable accuracy but with 516.7\% increase in computing time and 8.14\% increase in parameters compared with standard U-net.} Finally, we performed ablation tests and studied the impact of attention block size, overlap of the attention blocks, additional attention layers, and attention block placement on segmentation performance.