 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing the Annotated Bibliography as a Resource for Indicative Summarization
Jun 04, 2002

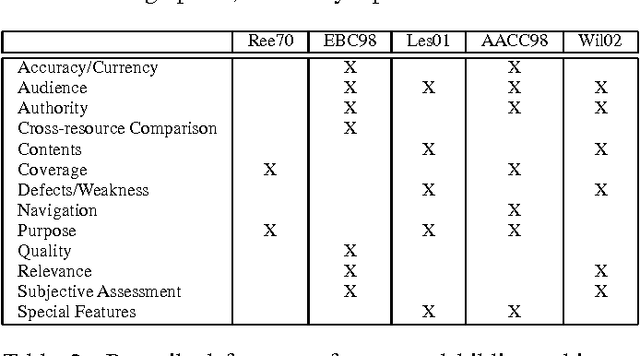
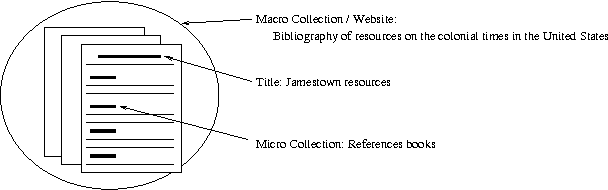
We report on a language resource consisting of 2000 annotated bibliography entries, which is being analyzed as part of our research on indicative document summarization. We show how annotated bibliographies cover certain aspects of summarization that have not been well-covered by other summary corpora, and motivate why they constitute an important form to study for information retrieval. We detail our methodology for collecting the corpus, and overview our document feature markup that we introduced to facilitate summary analysis. We present the characteristics of the corpus, methods of collection, and show its use in finding the distribution of types of information included in indicative summaries and their relative ordering within the summaries.
* 8 pages, 3 figures
Applying Natural Language Generation to Indicative Summarization
Jul 16, 2001

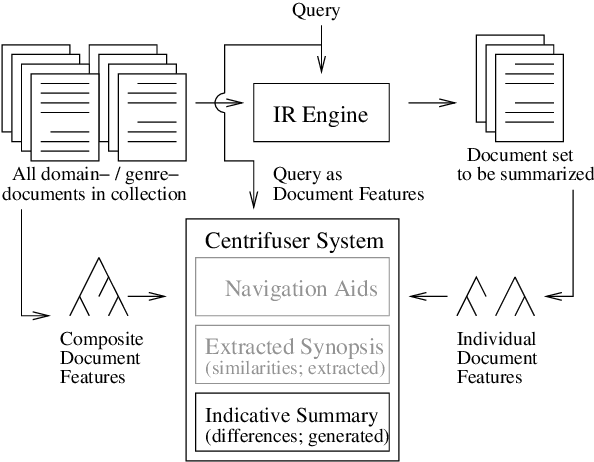
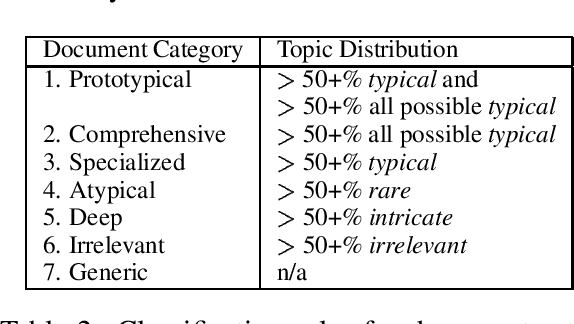
The task of creating indicative summaries that help a searcher decide whether to read a particular document is a difficult task. This paper examines the indicative summarization task from a generation perspective, by first analyzing its required content via published guidelines and corpus analysis. We show how these summaries can be factored into a set of document features, and how an implemented content planner uses the topicality document feature to create indicative multidocument query-based summaries.
Resources for Evaluation of Summarization Techniques
Oct 13, 1998
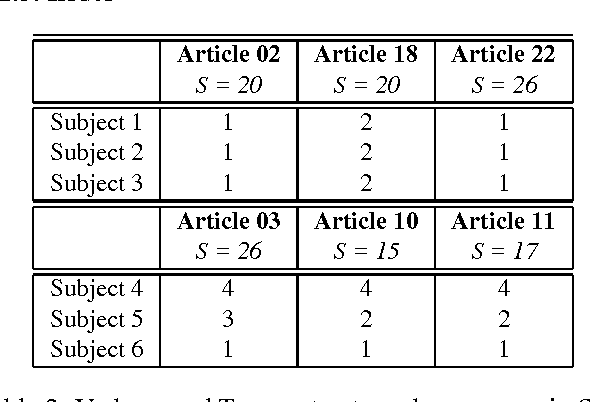
We report on two corpora to be used in the evaluation of component systems for the tasks of (1) linear segmentation of text and (2) summary-directed sentence extraction. We present characteristics of the corpora, methods used in the collection of user judgments, and an overview of the application of the corpora to evaluating the component system. Finally, we discuss the problems and issues with construction of the test set which apply broadly to the construction of evaluation resources for language technologies.
* LaTeX source, 5 pages, US Letter, uses lrec98.sty
Linear Segmentation and Segment Significance
Sep 15, 1998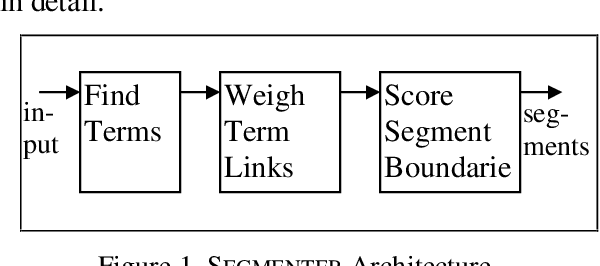
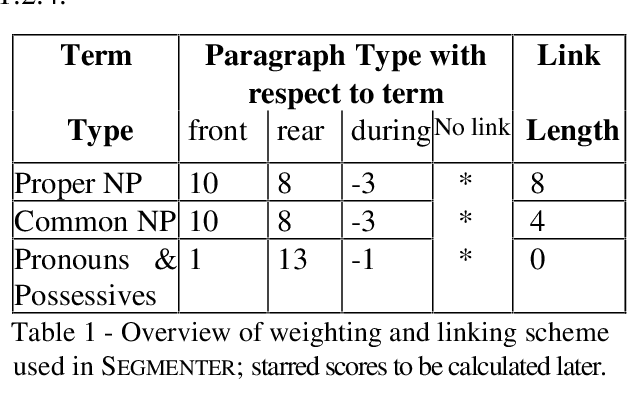
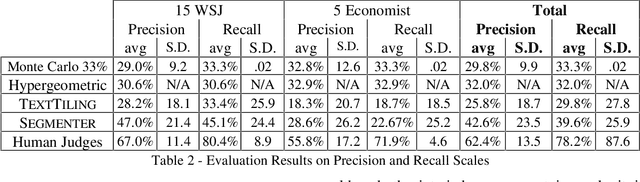
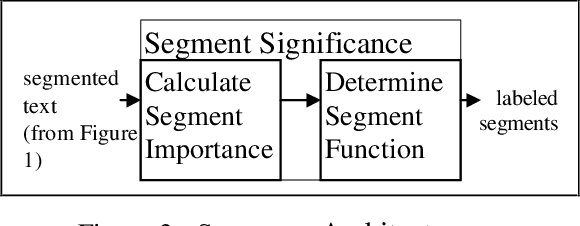
We present a new method for discovering a segmental discourse structure of a document while categorizing segment function. We demonstrate how retrieval of noun phrases and pronominal forms, along with a zero-sum weighting scheme, determines topicalized segmentation. Futhermore, we use term distribution to aid in identifying the role that the segment performs in the document. Finally, we present results of evaluation in terms of precision and recall which surpass earlier approaches.
* 9 pages, US Letter, 4 figures. Software License can be found at http://www.cs.columbia.edu/nlp/licenses/segmenterLicenseDownload.html
The Role of Verbs in Document Analysis
Jul 13, 1998
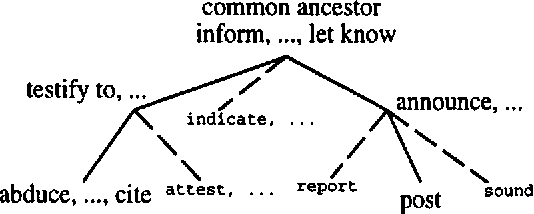

We present results of two methods for assessing the event profile of news articles as a function of verb type. The unique contribution of this research is the focus on the role of verbs, rather than nouns. Two algorithms are presented and evaluated, one of which is shown to accurately discriminate documents by type and semantic properties, i.e. the event profile. The initial method, using WordNet (Miller et al. 1990), produced multiple cross-classification of articles, primarily due to the bushy nature of the verb tree coupled with the sense disambiguation problem. Our second approach using English Verb Classes and Alternations (EVCA) Levin (1993) showed that monosemous categorization of the frequent verbs in WSJ made it possible to usefully discriminate documents. For example, our results show that articles in which communication verbs predominate tend to be opinion pieces, whereas articles with a high percentage of agreement verbs tend to be about mergers or legal cases. An evaluation is performed on the results using Kendall's Tau. We present convincing evidence for using verb semantic classes as a discriminant in document classification.
* 7 + 1 pages, US Letter, LaTeX (+2 eps figures). To appear in Proceedings of the 17th International Conference on Computational Linguistics (COLING-ACL '98). Tool license available at http://www.cs.columbia.edu/nlp/licenses/verberLicenseDownload.html