 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus Function from an $L_p^q-$norm Regularization Term for its Use as Adaptive Activation Functions in Neural Networks
Jun 30, 2022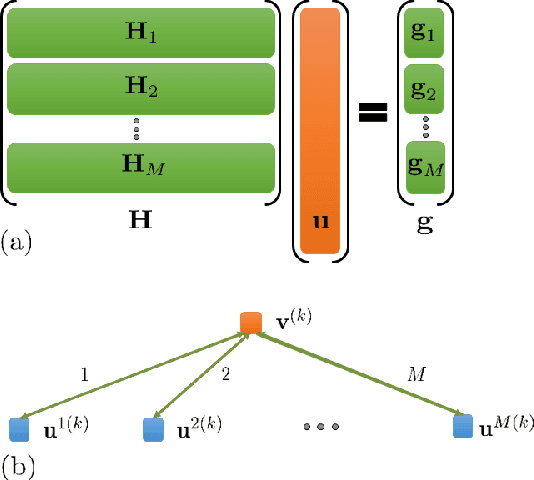



The design of a neural network is usually carried out by defining the number of layers, the number of neurons per layer, their connections or synapses, and the activation function that they will execute. The training process tries to optimize the weights assigned to those connections, together with the biases of the neurons, to better fit the training data. However, the definition of the activation functions is, in general, determined in the design process and not modified during the training, meaning that their behavior is unrelated to the training data set. In this paper we propose the definition and utilization of an implicit, parametric, non-linear activation function that adapts its shape during the training process. This fact increases the space of parameters to optimize within the network, but it allows a greater flexibility and generalizes the concept of neural networks. Furthermore, it simplifies the architectural design since the same activation function definition can be employed in each neuron, letting the training process to optimize their parameters and, thus, their behavior. Our proposed activation function comes from the definition of the consensus variable from the optimization of a linear underdetermined problem with an $L_p^q$ regularization term, via the Alternating Direction Method of Multipliers (ADMM). We define the neural networks using this type of activation functions as $pq-$networks. Preliminary results show that the use of these neural networks with this type of adaptive activation functions reduces the error in regression and classification examples, compared to equivalent regular feedforward neural networks with fixed activation functions.
Decentralized Reinforcement Learning for Multi-Target Search and Detection by a Team of Drones
Mar 17, 2021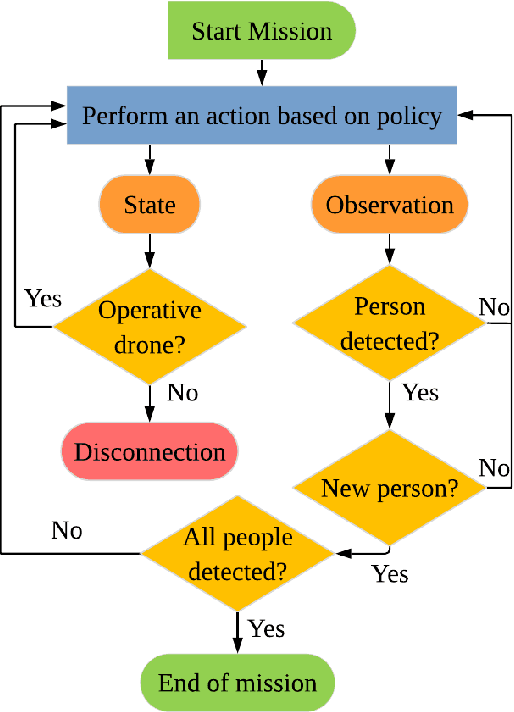
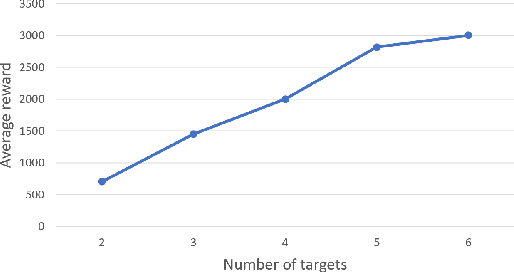
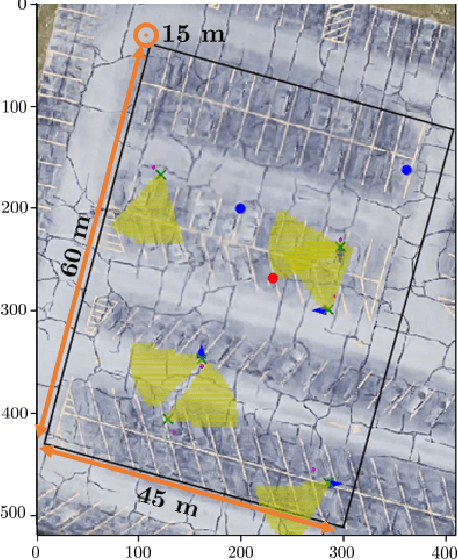
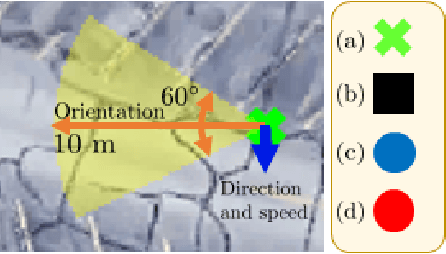
Targets search and detection encompasses a variety of decision problems such as coverage, surveillance, search, observing and pursuit-evasion along with others. In this paper we develop a multi-agent deep reinforcement learning (MADRL) method to coordinate a group of aerial vehicles (drones) for the purpose of locating a set of static targets in an unknown area. To that end, we have designed a realistic drone simulator that replicates the dynamics and perturbations of a real experiment, including statistical inferences taken from experimental data for its modeling. Our reinforcement learning method, which utilized this simulator for training, was able to find near-optimal policies for the drones. In contrast to other state-of-the-art MADRL methods, our method is fully decentralized during both learning and execution, can handle high-dimensional and continuous observation spaces, and does not require tuning of additional hyperparameters.