 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Activity Detection (VAD) in Noisy Environments
Dec 10, 2023In the realm of digital audio processing, Voice Activity Detection (VAD) plays a pivotal role in distinguishing speech from non-speech elements, a task that becomes increasingly complex in noisy environments. This paper details the development and implementation of a VAD system, specifically engineered to maintain high accuracy in the presence of various ambient noises. We introduce a novel algorithm enhanced with a specially designed filtering technique, effectively isolating speech even amidst diverse background sounds. Our comprehensive testing and validation demonstrate the system's robustness, highlighting its capability to discern speech from noise with remarkable precision. The exploration delves into: (1) the core principles underpinning VAD and its crucial role in modern audio processing; (2) the methodologies we employed to filter ambient noise; and (3) a presentation of evidence affirming our system's superior performance in noisy conditions.
Few-Shot Learning for Image Classification of Common Flora
May 07, 2021
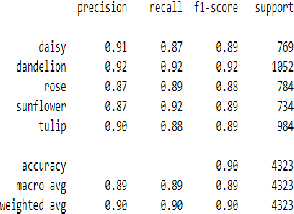
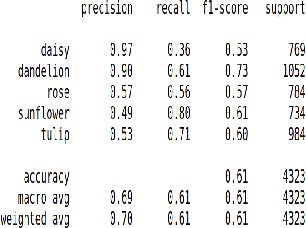
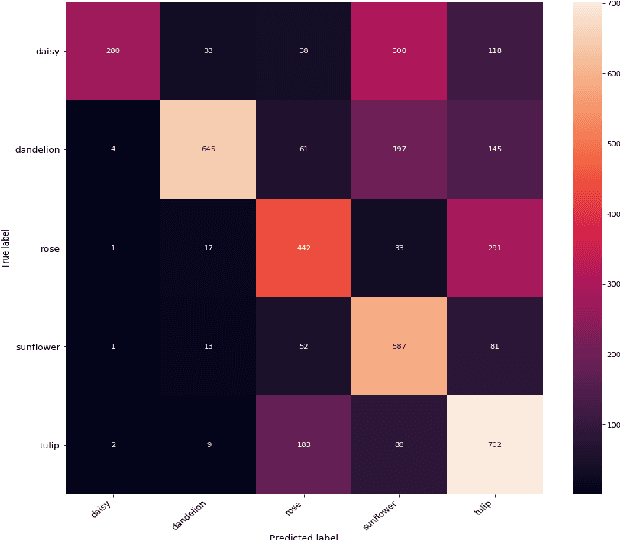
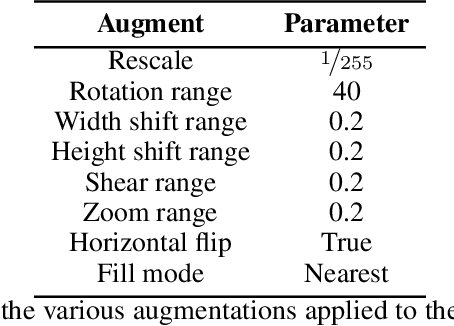
The use of meta-learning and transfer learning in the task of few-shot image classification is a well researched area with many papers showcasing the advantages of transfer learning over meta-learning in cases where data is plentiful and there is no major limitations to computational resources. In this paper we will showcase our experimental results from testing various state-of-the-art transfer learning weights and architectures versus similar state-of-the-art works in the meta-learning field for image classification utilizing Model-Agnostic Meta Learning (MAML). Our results show that both practices provide adequate performance when the dataset is sufficiently large, but that they both also struggle when data sparsity is introduced to maintain sufficient performance. This problem is moderately reduced with the use of image augmentation and the fine-tuning of hyperparameters. In this paper we will discuss: (1) our process of developing a robust multi-class convolutional neural network (CNN) for the task of few-shot image classification, (2) demonstrate that transfer learning is the superior method of helping create an image classification model when the dataset is large and (3) that MAML outperforms transfer learning in the case where data is very limited. The code is available here: github.com/JBall1/Few-Shot-Limited-Data
Food Classification with Convolutional Neural Networks and Multi-Class Linear Discernment Analysis
Dec 11, 2020


Convolutional neural networks (CNNs) have been successful in representing the fully-connected inferencing ability perceived to be seen in the human brain: they take full advantage of the hierarchy-style patterns commonly seen in complex data and develop more patterns using simple features. Countless implementations of CNNs have shown how strong their ability is to learn these complex patterns, particularly in the realm of image classification. However, the cost of getting a high performance CNN to a so-called "state of the art" level is computationally costly. Even when using transfer learning, which utilize the very deep layers from models such as MobileNetV2, CNNs still take a great amount of time and resources. Linear discriminant analysis (LDA), a generalization of Fisher's linear discriminant, can be implemented in a multi-class classification method to increase separability of class features while not needing a high performance system to do so for image classification. Similarly, we also believe LDA has great promise in performing well. In this paper, we discuss our process of developing a robust CNN for food classification as well as our effective implementation of multi-class LDA and prove that (1) CNN is superior to LDA for image classification and (2) why LDA should not be left out of the races for image classification, particularly for binary cases.