 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting judgements about dependent quantities of interest: The SHELF extension and copula methods illustrated using an asthma case study
Feb 15, 2021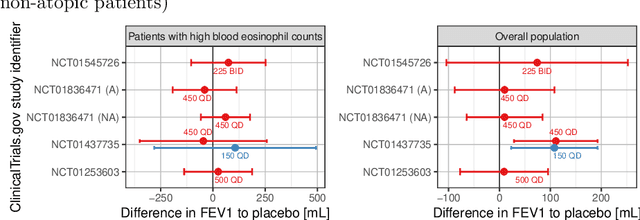
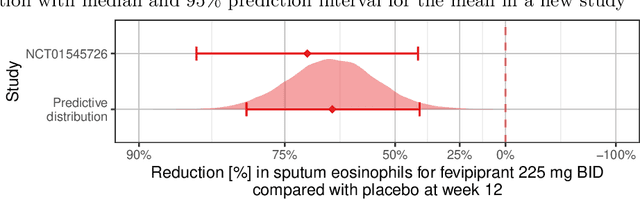
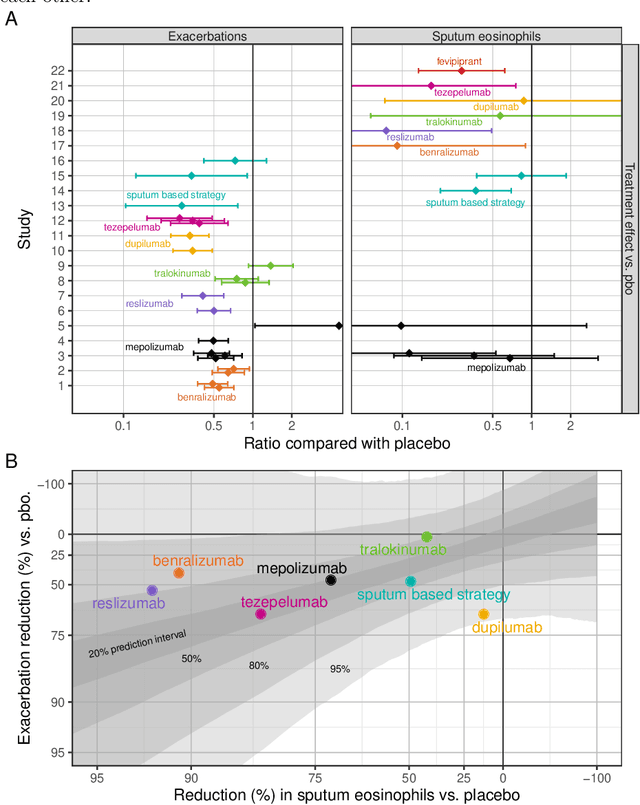
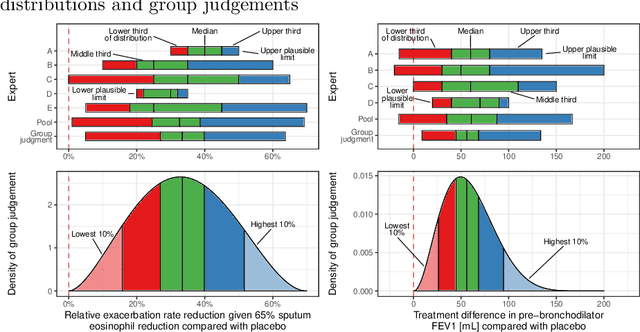
Pharmaceutical companies regularly need to make decisions about drug development programs based on the limited knowledge from early stage clinical trials. In this situation, eliciting the judgements of experts is an attractive approach for synthesising evidence on the unknown quantities of interest. When calculating the probability of success for a drug development program, multiple quantities of interest - such as the effect of a drug on different endpoints - should not be treated as unrelated. We discuss two approaches for establishing a multivariate distribution for several related quantities within the SHeffield ELicitation Framework (SHELF). The first approach elicits experts' judgements about a quantity of interest conditional on knowledge about another one. For the second approach, we first elicit marginal distributions for each quantity of interest. Then, for each pair of quantities, we elicit the concordance probability that both lie on the same side of their respective elicited medians. This allows us to specify a copula to obtain the joint distribution of the quantities of interest. We show how these approaches were used in an elicitation workshop that was performed to assess the probability of success of the registrational program of an asthma drug. The judgements of the experts, which were obtained prior to completion of the pivotal studies, were well aligned with the final trial results.
A Generative Bayesian Model for Aggregating Experts' Probabilities
Jul 11, 2012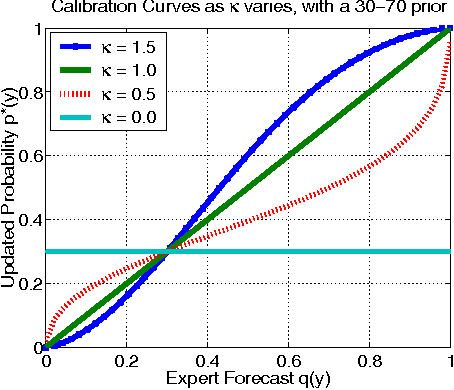
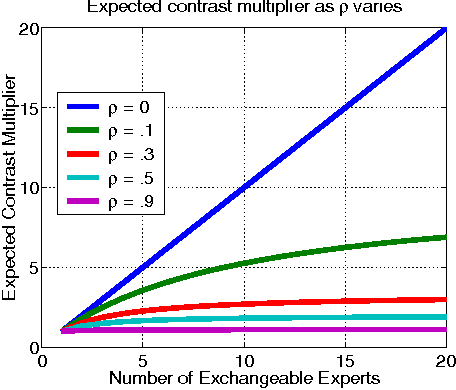
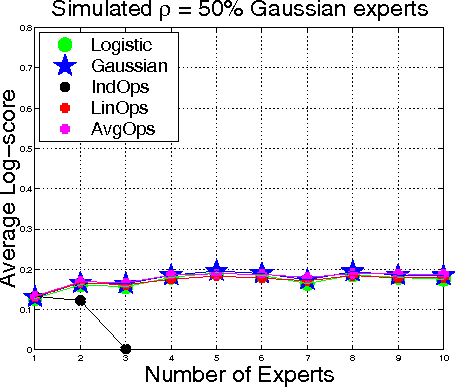
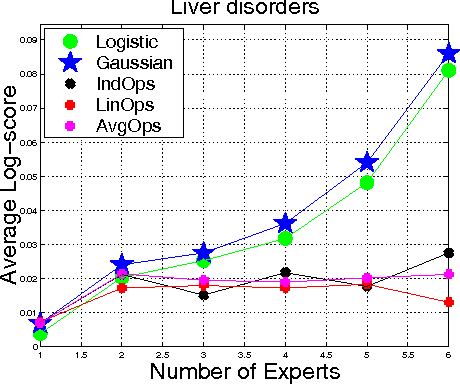
In order to improve forecasts, a decisionmaker often combines probabilities given by various sources, such as human experts and machine learning classifiers. When few training data are available, aggregation can be improved by incorporating prior knowledge about the event being forecasted and about salient properties of the experts. To this end, we develop a generative Bayesian aggregation model for probabilistic classi cation. The model includes an event-specific prior, measures of individual experts' bias, calibration, accuracy, and a measure of dependence betweeen experts. Rather than require absolute measures, we show that aggregation may be expressed in terms of relative accuracy between experts. The model results in a weighted logarithmic opinion pool (LogOps) that satis es consistency criteria such as the external Bayesian property. We derive analytic solutions for independent and for exchangeable experts. Empirical tests demonstrate the model's use, comparing its accuracy with other aggregation methods.