 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards symbolic regression for interpretable clinical decision scores
Dec 08, 2025



Medical decision-making makes frequent use of algorithms that combine risk equations with rules, providing clear and standardized treatment pathways. Symbolic regression (SR) traditionally limits its search space to continuous function forms and their parameters, making it difficult to model this decision-making. However, due to its ability to derive data-driven, interpretable models, SR holds promise for developing data-driven clinical risk scores. To that end we introduce Brush, an SR algorithm that combines decision-tree-like splitting algorithms with non-linear constant optimization, allowing for seamless integration of rule-based logic into symbolic regression and classification models. Brush achieves Pareto-optimal performance on SRBench, and was applied to recapitulate two widely used clinical scoring systems, achieving high accuracy and interpretable models. Compared to decision trees, random forests, and other SR methods, Brush achieves comparable or superior predictive performance while producing simpler models.
PMLB v1.0: an open source dataset collection for benchmarking machine learning methods
Nov 30, 2020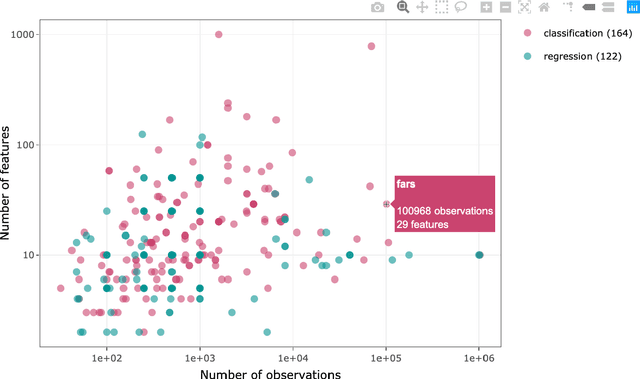
PMLB (Penn Machine Learning Benchmark) is an open-source data repository containing a curated collection of datasets for evaluating and comparing machine learning (ML) algorithms. Compiled from a broad range of existing ML benchmark collections, PMLB synthesizes and standardizes hundreds of publicly available datasets from diverse sources such as the UCI ML repository and OpenML, enabling systematic assessment of different ML methods. These datasets cover a range of applications, from binary/multi-class classification to regression problems with combinations of categorical and continuous features. PMLB has both a Python interface (pmlb) and an R interface (pmlbr), both with detailed documentation that allows the user to access cleaned and formatted datasets using a single function call. PMLB also provides a comprehensive description of each dataset and advanced functions to explore the dataset space, allowing for smoother user experience and handling of data. The resource is designed to facilitate open-source contributions in the form of datasets as well as improvements to curation.
Is deep learning necessary for simple classification tasks?
Jun 11, 2020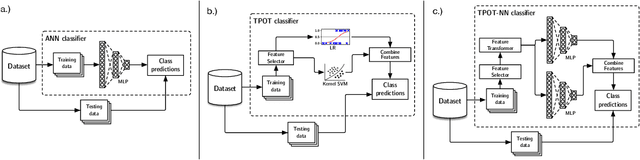
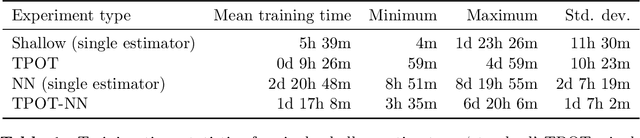
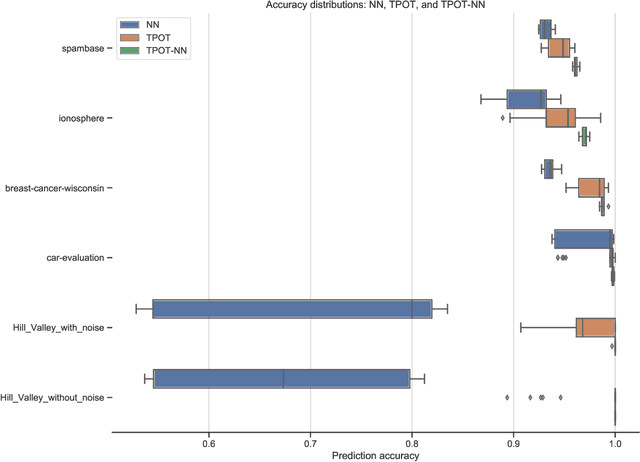
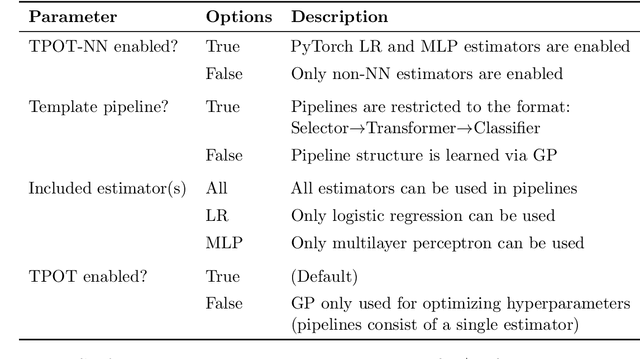
Automated machine learning (AutoML) and deep learning (DL) are two cutting-edge paradigms used to solve a myriad of inductive learning tasks. In spite of their successes, little guidance exists for when to choose one approach over the other in the context of specific real-world problems. Furthermore, relatively few tools exist that allow the integration of both AutoML and DL in the same analysis to yield results combining both of their strengths. Here, we seek to address both of these issues, by (1.) providing a head-to-head comparison of AutoML and DL in the context of binary classification on 6 well-characterized public datasets, and (2.) evaluating a new tool for genetic programming-based AutoML that incorporates deep estimators. Our observations suggest that AutoML outperforms simple DL classifiers when trained on similar datasets for binary classification but integrating DL into AutoML improves classification performance even further. However, the substantial time needed to train AutoML+DL pipelines will likely outweigh performance advantages in many applications.