 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividually amplified text-to-speech
Dec 03, 2020



Text-to-speech (TTS) offers the opportunity to compensate for a hearing loss at the source rather than correcting for it at the receiving end. This removes limitations such as time constraints for algorithms that amplify a sound individually and can lead to higher speech quality for hearing-impaired listeners. We propose an algorithm that restores loudness to normal perception at a high resolution in time, frequency and level, and embed it in a TTS system that uses Tacotron2 and WaveGlow to produce individually amplified speech. Subjective evaluations of speech quality showed that the proposed algorithm led to high-quality audio. Mean opinion scores were predicted well by the STOI metric. Transfer learning led to a quick adaption of the produced spectra from original speech to individually amplified speech and gives us a way to train an individual TTS system efficiently.
Fast computation of loudness using a deep neural network
May 24, 2019
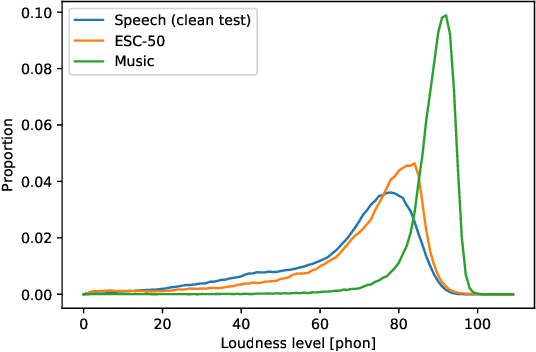
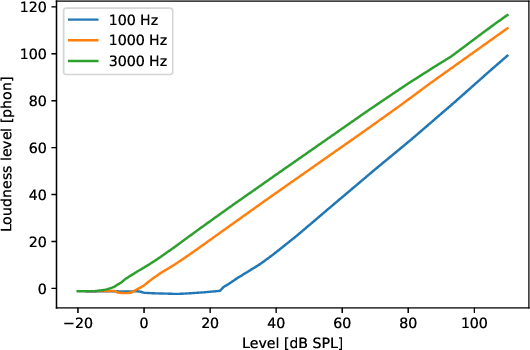
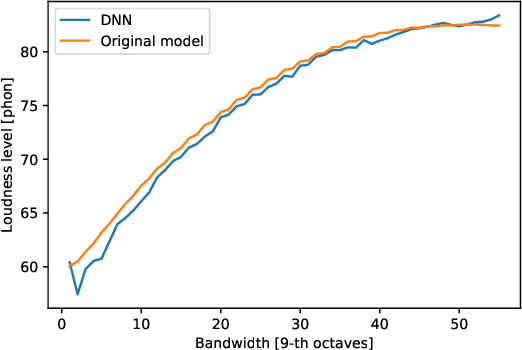
The present paper introduces a deep neural network (DNN) for predicting the instantaneous loudness of a sound from its time waveform. The DNN was trained using the output of a more complex model, called the Cambridge loudness model. While a modern PC can perform a few hundred loudness computations per second using the Cambridge loudness model, it can perform more than 100,000 per second using the DNN, allowing real-time calculation of loudness. The root-mean-square deviation between the predictions of instantaneous loudness level using the two models was less than 0.5 phon for unseen types of sound. We think that the general approach of simulating a complex perceptual model by a much faster DNN can be applied to other perceptual models to make them run in real time.