 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuction-Consensus Algorithm with Learned Bidding Scheme for Multi-Robot Systems
May 21, 2026Multi-Robot Task Allocation (MRTA) is a central challenge in decentralized multi-agent systems, where teams of robots must cooperatively assign and execute tasks under limited communication while optimizing global performance objectives. Auction-consensus algorithms, such as the Consensus-Based Bundle Algorithm (CBBA), provide scalable decentralized coordination with provable convergence, but rely on hand-crafted greedy scoring functions that often lead to suboptimal task allocations. This paper proposes a learning-enhanced auction-consensus framework in which CBBA's deterministic bidding mechanism is replaced by a neural bidding policy trained using reinforcement learning. Under a centralized training and decentralized execution paradigm, agents learn to compute task bids from partial local observations while retaining the standard auction and consensus phases for decentralized coordination. The learned bidding policy is trained using Proximal Policy Optimization with rewards shaped by proximity to globally optimal solutions obtained via mixed-integer linear programming. Multiple neural architectures are evaluated, including a Neural Additive Model, the Long Short-Term Memory (LSTM) model, and the Set Transformer Model. Experimental results across varying swarm sizes demonstrate that learned bidding policies can improve solution quality over classical CBBA while preserving decentralized execution. The proposed approach highlights the effectiveness of integrating reinforcement learning with classical distributed coordination algorithms, offering a scalable pathway toward higher-quality decentralized multi-robot task allocation.
An Attention Mechanism for Answer Selection Using a Combined Global and Local View
Sep 20, 2017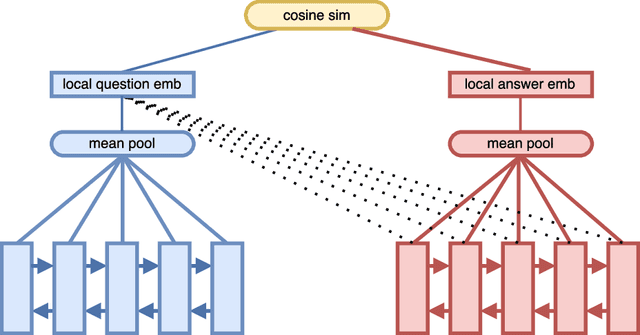
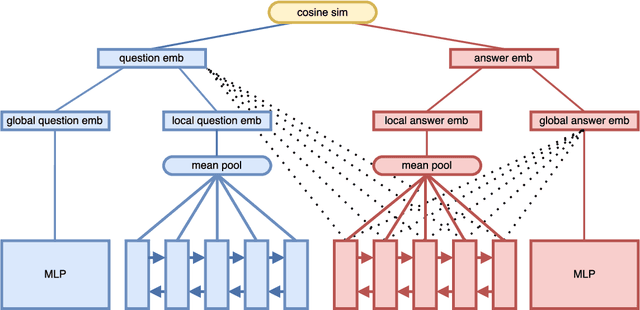
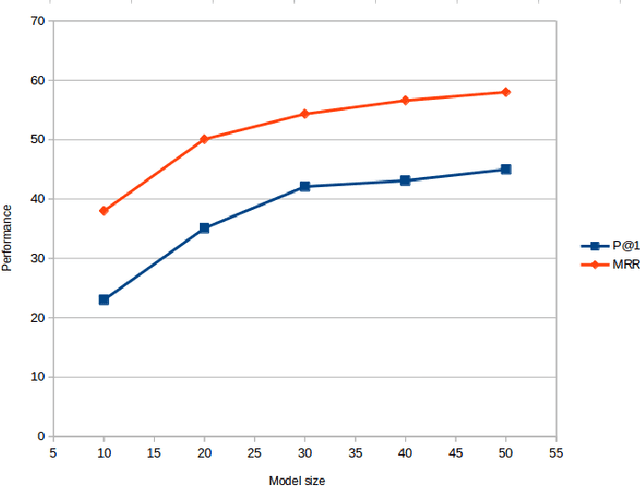
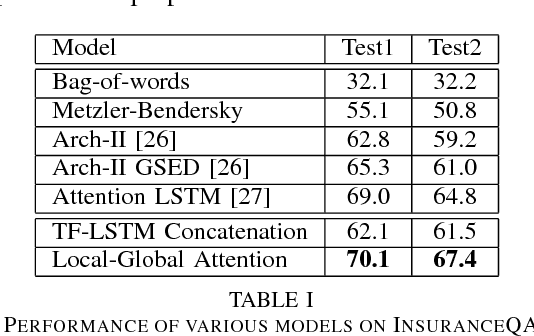
We propose a new attention mechanism for neural based question answering, which depends on varying granularities of the input. Previous work focused on augmenting recurrent neural networks with simple attention mechanisms which are a function of the similarity between a question embedding and an answer embeddings across time. We extend this by making the attention mechanism dependent on a global embedding of the answer attained using a separate network. We evaluate our system on InsuranceQA, a large question answering dataset. Our model outperforms current state-of-the-art results on InsuranceQA. Further, we visualize which sections of text our attention mechanism focuses on, and explore its performance across different parameter settings.