 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Evaluation: past, present and future
Aug 21, 2016
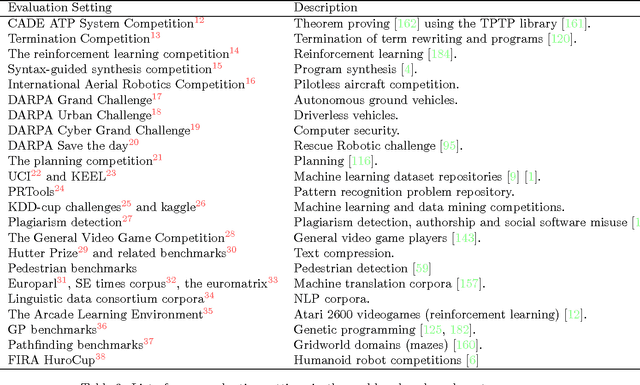
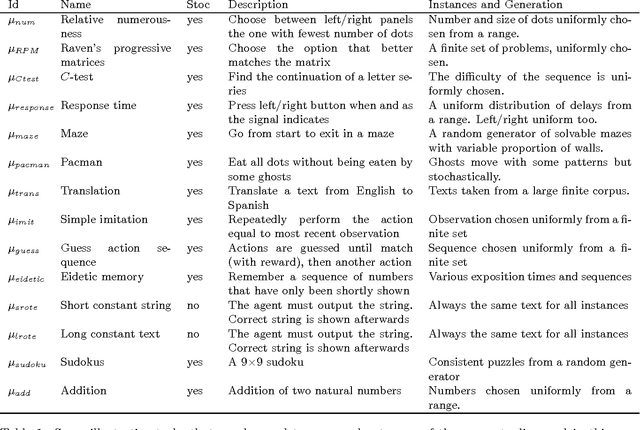
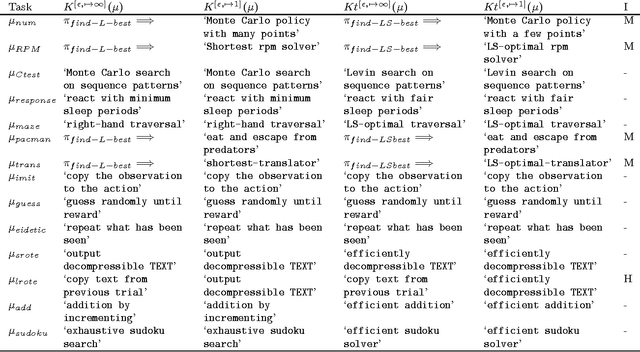
Artificial intelligence develops techniques and systems whose performance must be evaluated on a regular basis in order to certify and foster progress in the discipline. We will describe and critically assess the different ways AI systems are evaluated. We first focus on the traditional task-oriented evaluation approach. We see that black-box (behavioural evaluation) is becoming more and more common, as AI systems are becoming more complex and unpredictable. We identify three kinds of evaluation: Human discrimination, problem benchmarks and peer confrontation. We describe the limitations of the many evaluation settings and competitions in these three categories and propose several ideas for a more systematic and robust evaluation. We then focus on a less customary (and challenging) ability-oriented evaluation approach, where a system is characterised by its (cognitive) abilities, rather than by the tasks it is designed to solve. We discuss several possibilities: the adaptation of cognitive tests used for humans and animals, the development of tests derived from algorithmic information theory or more general approaches under the perspective of universal psychometrics.
Universal Psychometrics Tasks: difficulty, composition and decomposition
Mar 26, 2015
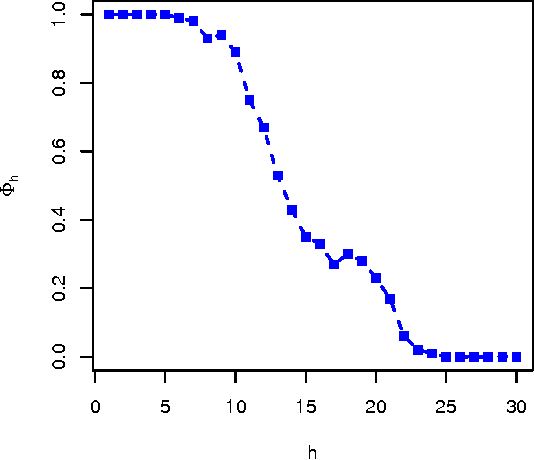
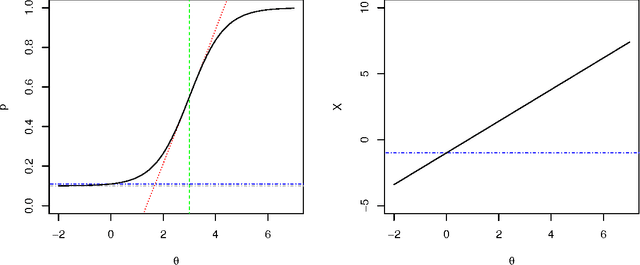
This note revisits the concepts of task and difficulty. The notion of cognitive task and its use for the evaluation of intelligent systems is still replete with issues. The view of tasks as MDP in the context of reinforcement learning has been especially useful for the formalisation of learning tasks. However, this alternate interaction does not accommodate well for some other tasks that are usual in artificial intelligence and, most especially, in animal and human evaluation. In particular, we want to have a more general account of episodes, rewards and responses, and, most especially, the computational complexity of the algorithm behind an agent solving a task. This is crucial for the determination of the difficulty of a task as the (logarithm of the) number of computational steps required to acquire an acceptable policy for the task, which includes the exploration of policies and their verification. We introduce a notion of asynchronous-time stochastic tasks. Based on this interpretation, we can see what task difficulty is, what instance difficulty is (relative to a task) and also what task compositions and decompositions are.
A note about the generalisation of the C-tests
Mar 26, 2015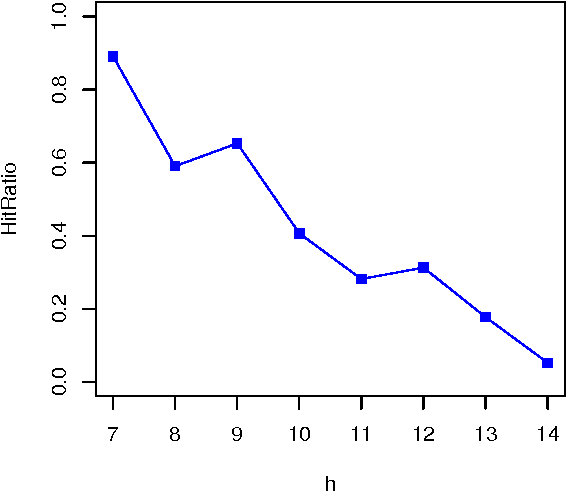
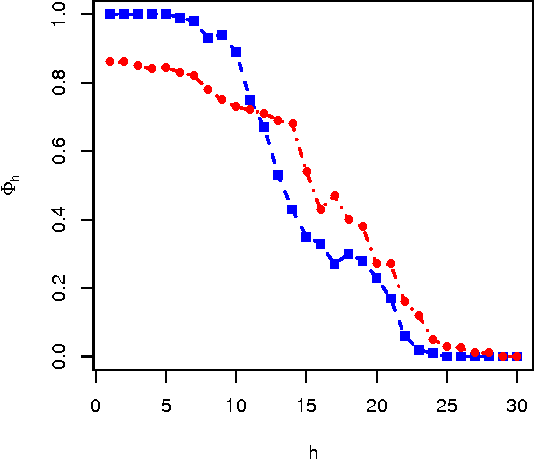
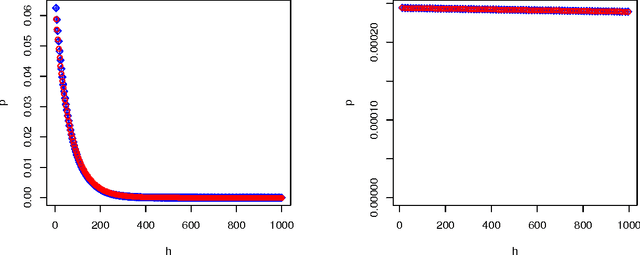

In this exploratory note we ask the question of what a measure of performance for all tasks is like if we use a weighting of tasks based on a difficulty function. This difficulty function depends on the complexity of the (acceptable) solution for the task (instead of a universal distribution over tasks or an adaptive test). The resulting aggregations and decompositions are (now retrospectively) seen as the natural (and trivial) interactive generalisation of the C-tests.
On the universality of cognitive tests
May 09, 2013


The analysis of the adaptive behaviour of many different kinds of systems such as humans, animals and machines, requires more general ways of assessing their cognitive abilities. This need is strengthened by increasingly more tasks being analysed for and completed by a wider diversity of systems, including swarms and hybrids. The notion of universal test has recently emerged in the context of machine intelligence evaluation as a way to define and use the same cognitive test for a variety of systems, using some principled tasks and adapting the interface to each particular subject. However, how far can universal tests be taken? This paper analyses this question in terms of subjects, environments, space-time resolution, rewards and interfaces. This leads to a number of findings, insights and caveats, according to several levels where universal tests may be progressively more difficult to conceive, implement and administer. One of the most significant contributions is given by the realisation that more universal tests are defined as maximisations of less universal tests for a variety of configurations. This means that universal tests must be necessarily adaptive.
A short note on estimating intelligence from user profiles in the context of universal psychometrics: prospects and caveats
May 07, 2013There has been an increasing interest in inferring some personality traits from users and players in social networks and games, respectively. This goes beyond classical sentiment analysis, and also much further than customer profiling. The purpose here is to have a characterisation of users in terms of personality traits, such as openness, conscientiousness, extraversion, agreeableness, and neuroticism. While this is an incipient area of research, we ask the question of whether cognitive abilities, and intelligence in particular, are also measurable from user profiles. However, we pose the question as broadly as possible in terms of subjects, in the context of universal psychometrics, including humans, machines and hybrids. Namely, in this paper we analyse the following question: is it possible to measure the intelligence of humans and (non-human) bots in a social network or a game just from their user profiles, i.e., by observation, without the use of interactive tests, such as IQ tests, the Turing test or other more principled machine intelligence tests?
Complexity distribution of agent policies
Feb 08, 2013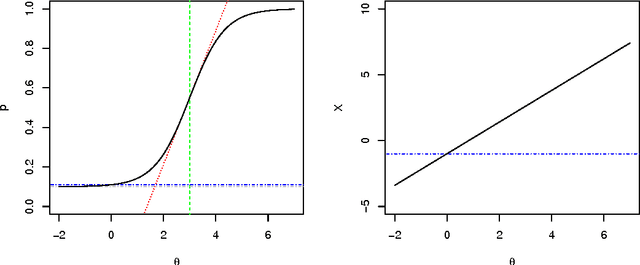
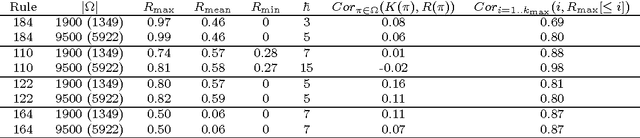
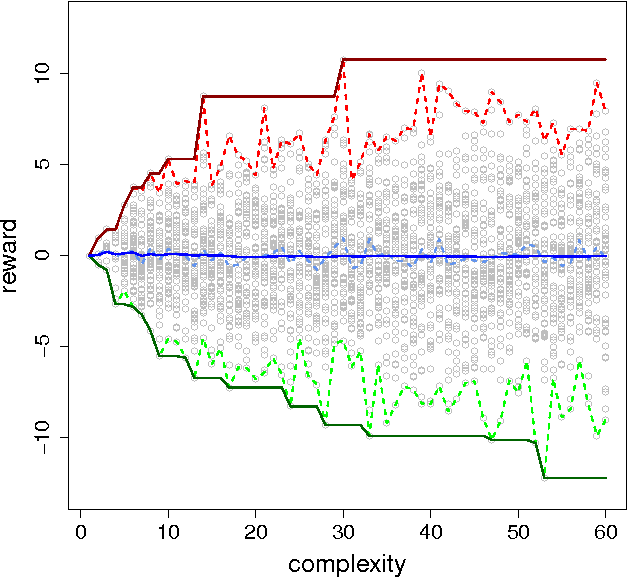
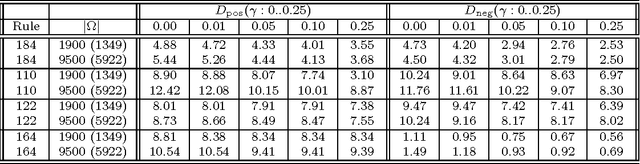
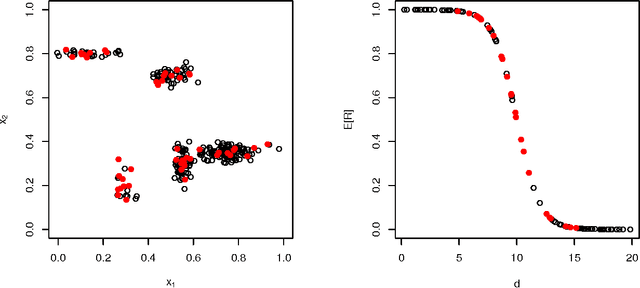
We analyse the complexity of environments according to the policies that need to be used to achieve high performance. The performance results for a population of policies leads to a distribution that is examined in terms of policy complexity and analysed through several diagrams and indicators. The notion of environment response curve is also introduced, by inverting the performance results into an ability scale. We apply all these concepts, diagrams and indicators to a minimalistic environment class, agent-populated elementary cellular automata, showing how the difficulty, discriminating power and ranges (previous to normalisation) may vary for several environments.
Soft (Gaussian CDE) regression models and loss functions
Nov 05, 2012
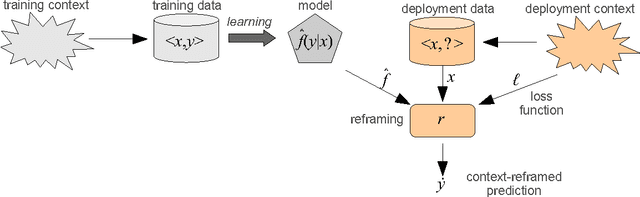
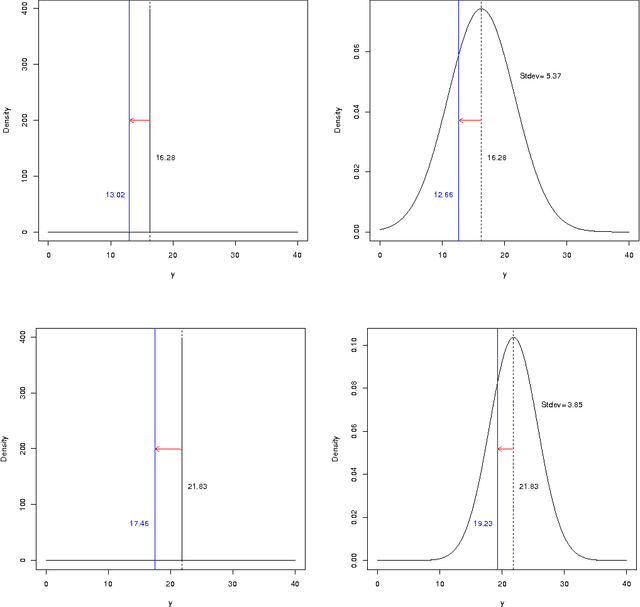

Regression, unlike classification, has lacked a comprehensive and effective approach to deal with cost-sensitive problems by the reuse (and not a re-training) of general regression models. In this paper, a wide variety of cost-sensitive problems in regression (such as bids, asymmetric losses and rejection rules) can be solved effectively by a lightweight but powerful approach, consisting of: (1) the conversion of any traditional one-parameter crisp regression model into a two-parameter soft regression model, seen as a normal conditional density estimator, by the use of newly-introduced enrichment methods; and (2) the reframing of an enriched soft regression model to new contexts by an instance-dependent optimisation of the expected loss derived from the conditional normal distribution.
On the influence of intelligence in (social) intelligence testing environments
Feb 03, 2012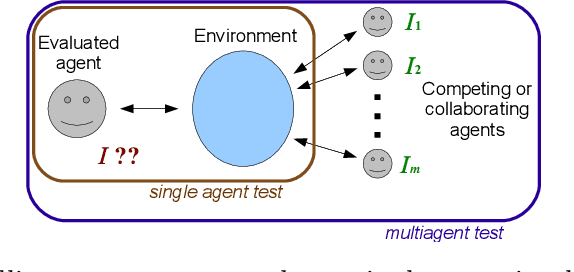
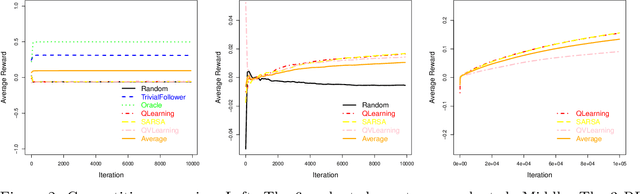
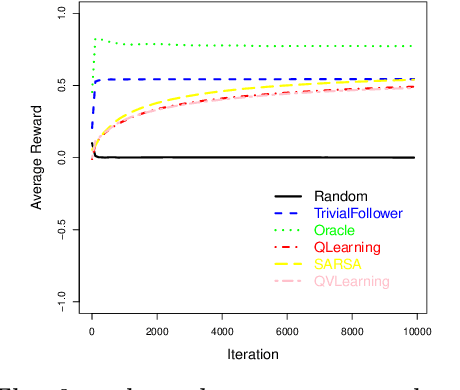
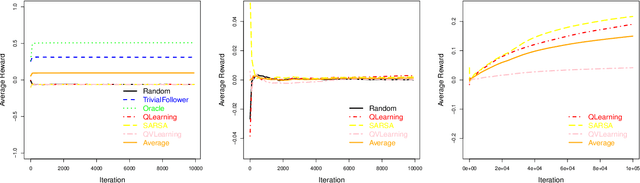
This paper analyses the influence of including agents of different degrees of intelligence in a multiagent system. The goal is to better understand how we can develop intelligence tests that can evaluate social intelligence. We analyse several reinforcement algorithms in several contexts of cooperation and competition. Our experimental setting is inspired by the recently developed Darwin-Wallace distribution.
Application of distances between terms for flat and hierarchical data
Sep 23, 2011In machine learning, distance-based algorithms, and other approaches, use information that is represented by propositional data. However, this kind of representation can be quite restrictive and, in many cases, it requires more complex structures in order to represent data in a more natural way. Terms are the basis for functional and logic programming representation. Distances between terms are a useful tool not only to compare terms, but also to determine the search space in many of these applications. This dissertation applies distances between terms, exploiting the features of each distance and the possibility to compare from propositional data types to hierarchical representations. The distances between terms are applied through the k-NN (k-nearest neighbor) classification algorithm using XML as a common language representation. To be able to represent these data in an XML structure and to take advantage of the benefits of distance between terms, it is necessary to apply some transformations. These transformations allow the conversion of flat data into hierarchical data represented in XML, using some techniques based on intuitive associations between the names and values of variables and associations based on attribute similarity. Several experiments with the distances between terms of Nienhuys-Cheng and Estruch et al. were performed. In the case of originally propositional data, these distances are compared to the Euclidean distance. In all cases, the experiments were performed with the distance-weighted k-nearest neighbor algorithm, using several exponents for the attraction function (weighted distance). It can be seen that in some cases, the term distances can significantly improve the results on approaches applied to flat representations.
Analysis of first prototype universal intelligence tests: evaluating and comparing AI algorithms and humans
Sep 23, 2011Today, available methods that assess AI systems are focused on using empirical techniques to measure the performance of algorithms in some specific tasks (e.g., playing chess, solving mazes or land a helicopter). However, these methods are not appropriate if we want to evaluate the general intelligence of AI and, even less, if we compare it with human intelligence. The ANYNT project has designed a new method of evaluation that tries to assess AI systems using well known computational notions and problems which are as general as possible. This new method serves to assess general intelligence (which allows us to learn how to solve any new kind of problem we face) and not only to evaluate performance on a set of specific tasks. This method not only focuses on measuring the intelligence of algorithms, but also to assess any intelligent system (human beings, animals, AI, aliens?,...), and letting us to place their results on the same scale and, therefore, to be able to compare them. This new approach will allow us (in the future) to evaluate and compare any kind of intelligent system known or even to build/find, be it artificial or biological. This master thesis aims at ensuring that this new method provides consistent results when evaluating AI algorithms, this is done through the design and implementation of prototypes of universal intelligence tests and their application to different intelligent systems (AI algorithms and humans beings). From the study we analyze whether the results obtained by two different intelligent systems are properly located on the same scale and we propose changes and refinements to these prototypes in order to, in the future, being able to achieve a truly universal intelligence test.