 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Constructive and Perturbative Deep Learning Algorithms for the Capacitated Vehicle Routing Problem
Nov 25, 2022The Capacitated Vehicle Routing Problem is a well-known NP-hard problem that poses the challenge of finding the optimal route of a vehicle delivering products to multiple locations. Recently, new efforts have emerged to create constructive and perturbative heuristics to tackle this problem using Deep Learning. In this paper, we join these efforts to develop the Combined Deep Constructor and Perturbator, which combines two powerful constructive and perturbative Deep Learning-based heuristics, using attention mechanisms at their core. Furthermore, we improve the Attention Model-Dynamic for the Capacitated Vehicle Routing Problem by proposing a memory-efficient algorithm that reduces its memory complexity by a factor of the number of nodes. Our method shows promising results. It demonstrates a cost improvement in common datasets when compared against other multiple Deep Learning methods. It also obtains close results to the state-of-the art heuristics from the Operations Research field. Additionally, the proposed memory efficient algorithm for the Attention Model-Dynamic model enables its use in problem instances with more than 100 nodes.
A Straightforward Framework For Video Retrieval Using CLIP
Feb 26, 2021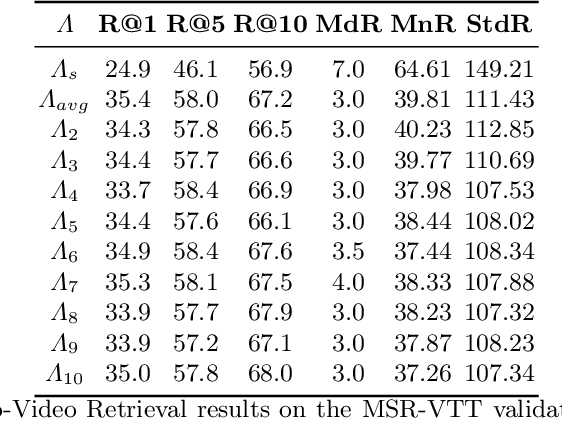
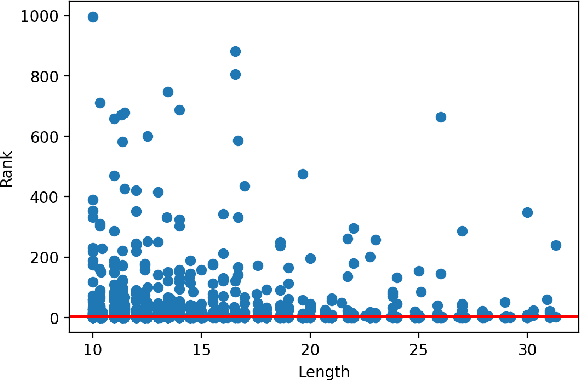
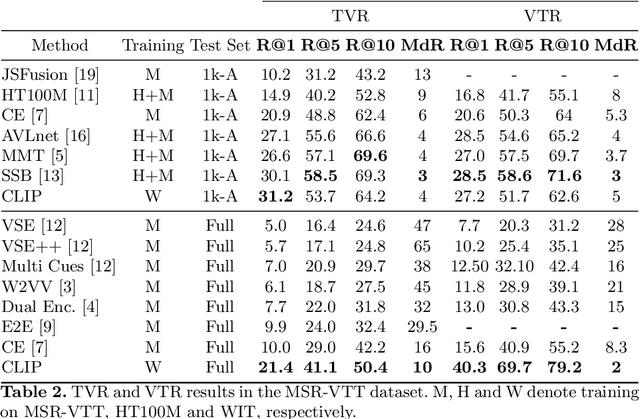
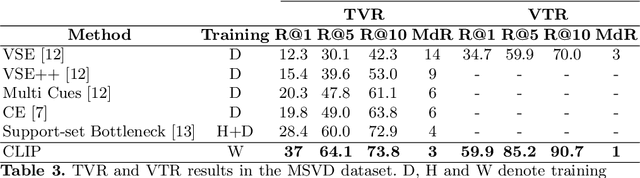
Video Retrieval is a challenging task where a text query is matched to a video or vice versa. Most of the existing approaches for addressing such a problem rely on annotations made by the users. Although simple, this approach is not always feasible in practice. In this work, we explore the application of the language-image model, CLIP, to obtain video representations without the need for said annotations. This model was explicitly trained to learn a common space where images and text can be compared. Using various techniques described in this document, we extended its application to videos, obtaining state-of-the-art results on the MSR-VTT and MSVD benchmarks.